Table of Links
3.2 RQ2: Affected software artifacts
We define affected software artifacts as objects in software repositories that violate ethical principles. To derive the set of affected software artifacts, we started with the 19 categories from the taxonomy of prior study [74]. Then, we categorized the artifacts we found in our study based on the 19 categories. After removing categories with no artifact found, we obtained eight categories: (1) source code, (2) script, (3) configuration, (4) database (data), (5) image, (6) prose, (7) legalese, and (8) other. For the prose category (i.e., plain text files), we only found two concrete types (i.e., README/CONTRIBUTING.md, and CHANGELOG) so we separated them into two categories. As the category “other” in prior study [74] is too broad, we split it into 10 new categories based on aforementioned steps in thematic analysis: (1) external application programming interface (API), (2) user interface (UI), (3) project, (4) release history, (5) software feature, (6) product name, (7) operating system (OS), (8) website, (9) PR/Issue code review, (10) PR/Issue comment. We derive “PR/Issue code review” and “PR/Issue comment” based on prior work [58]. Our newly introduced categories aim to preserve the hierarchy of artifacts (Project > Software feature [50] > Source code). For 28 cases (8.9%), both authors meet to discuss the issues labeled with different categories to resolve any disagreement. Finally, we obtained 18 types of affected software artifacts: (1) project, (2) software feature, (3) source code, (4) external API, (5) legalese, (6) product name, (7) release history, (8) UI, (9) configuration file, (10) PR/Issue code review, (11) PR/Issue comment, (12) README / CONTRIBUTING.md, (13) CHANGELOG, (14) data, (15) image, (16) OS, (17) website, and (18) script (i.e., source code in languages executed by an interpreter). As several artifacts are more difficult to understand, we explain them below:
Project: The affected artifacts involve more than one types of artifacts within the entire repository.
Software feature: Functional or non-functional requirements of a system [50, 57]. An example is the ability to unsubscribe a service.
Source code: Source files (excluding scripts, binary code, build code) that belong to the current repository (internal).
External API: API from third party (external) library or service.
Legalese: Licenses, copyright notes, or patents.
Product name: The product, project, or app name.

The third column in Table 1 presents the affected artifacts for each unethical behavior. Each number in the column denotes the number of GitHub issues with a certain type of artifact (e.g., “19 Projects” means that there are 19 issues where S2 is affected by projects). Theoretically, one issue might discuss multiple artifacts but we found that each issue only discusses one artifact because (1) developers prefer discussing ethical concerns for one type of artifact in one issue, and (2) some categories are hierarchical (e.g., “project” includes multiple types of artifacts). Overall, Table 1 shows that source code is still the most common type of artifacts for unethical behavior (i.e., it affects eight types of unethical behavior).

4 METHODOLOGY
Our study shows that diverse types of unethical behavior exist in OSS projects, and they usually involve diverse types of software artifacts. The diversity and the complexity of the rules governing the ethics-related activities in GitHub motivate the need for a modeling approach that can abstract this complexity and facilitate its automatic detection. In Section 4.1, we describe how we model unethical behavior using SWRL rules. Then, we explain the architecture of Etor that uses SWRL rules for automatic detection in Section 4.2.
4.1 Modeling via SWRL rules
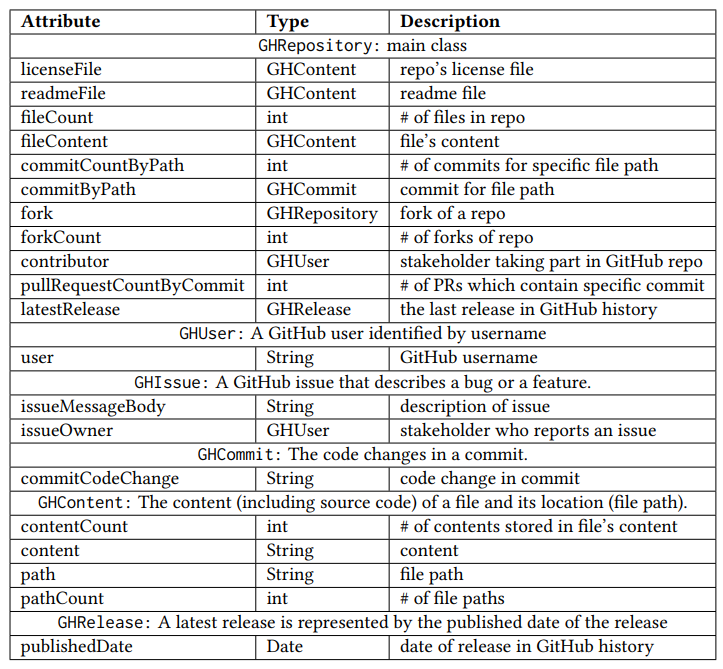
We propose using SWRL rules to represent unethical behavior in an OSS project together with the publicly available data in GitHub. SWRL rules allow us to model affected software artifacts as hierarchies of classes and properties, capturing the relationships between affected software artifacts and stakeholders. Table 2 shows GitHub attributes used in our modeling. The columns under “Attribute”, and “Type” explain each attribute and its type. We model each OSS project as GHRepository. By referring to the GitHub Repositories API [19], we selected 11 data properties (e.g., latestRelease and licenseFile) that belong to a GHRepository by excluding properties that are irrelevant for unethical behavior (e.g., avatar_url that points to the icon for a repository). Apart from GHRepository, we introduce six classes to model data properties of a repository: (1) GHUser, (2) GHCommit, (3) GHContent, (4) GHIssue (5) GHPullRequest), (6) GHRelease. While GitHub users (GHUser) usually play different roles in OSS projects, we only model: (1) contributors (users who are official contributors of a repository) and (2) issue owners (users who report an issue). For modeling GHIssue, we reuse the same convention in GitHub by modeling a PR (GHPullRequest) as a subclass of GHIssue (i.e., GitHub Issue Search API will search for issues and PRs, essentially treating a PR as a type of GitHub issue). Figure 3 shows the OWL ontology for our model where GHRepository is the main class, and the arrows denote the relationships between the classes. Specifically, GHIssue − GHPullRequest represents the subclass relations, whereas other arrows denote hasA relations (e.g., GHIssue − GHUser means that each issue has a user who reports the issue).
Authors:
(1) Hsu Myat Win, Southern University of Science and Technology, China (11960003@mail.sustech.edu.cn);
(2) Haibo Wang, Southern University of Science and Technology, China (wanghb2020@mail.sustech.edu.cn);
(3) Shin Hwei Tan, a corresponding author from Southern University of Science and Technology, China (tansh3@sustech.edu.cn).
This paper is
[story continues]
tags