Table of Links
- Abstract and Introduction
- Backgrounds
- Type of remote sensing sensor data
- Benchmark remote sensing datasets for evaluating learning models
- Evaluation metrics for few-shot remote sensing
- Recent few-shot learning techniques in remote sensing
- Few-shot based object detection and segmentation in remote sensing
- Discussions
- Numerical experimentation of few-shot classification on UAV-based dataset
- Explainable AI (XAI) in Remote Sensing
- Conclusions and Future Directions
- Acknowledgements, Declarations, and References
6 Recent few-shot learning techniques in remote sensing
In the domain of remote sensing, the intersection with computer vision has received considerable attention and research interest, as evinced by numerous works such as those undertaken by [8] and [38], which delve into and assess diverse active machine learning frameworks. Moreover, the intricacies of hyperspectral image classification and contemporary developments in machine learning and computer vision methods are explored by [39]. A comprehensive and exhaustive analysis of deep learning algorithms utilized for processing remote sensing images, while detailing current practices and available resources, is provided by [40]. Furthermore, [8] presents an overview of Vision Transformer-based approaches to remote sensing, with a specific focus on very high-resolution, hyperspectral, and radar imaging. In this review, our specific focus lies on recent breakthroughs in the realm of few-shot learning techniques for remote sensing imaging. We seek to provide an in-depth exploration of the implications of such advancements for scene classification and comprehension in both satellite-based and UAV-based data collection platforms. The incorporation of explainable AI can aid in understanding the reasoning behind classification results, providing more transparency and confidence in decision-making processes.
6.1 Few-Shot learning in hyperspectral images classification
In the field of remote sensing, few-shot learning has gained significant traction, as highlighted in the introductory section. In this particular section, we shall concentrate on the techniques put forward for both single-label and multilabel remote sensing classification within the context of both satellite and UAV-based platforms. It is worth noting that, unless indicated otherwise, all the evaluation metrics employed in the studies under review in this section encompass OA, AA, and κ.
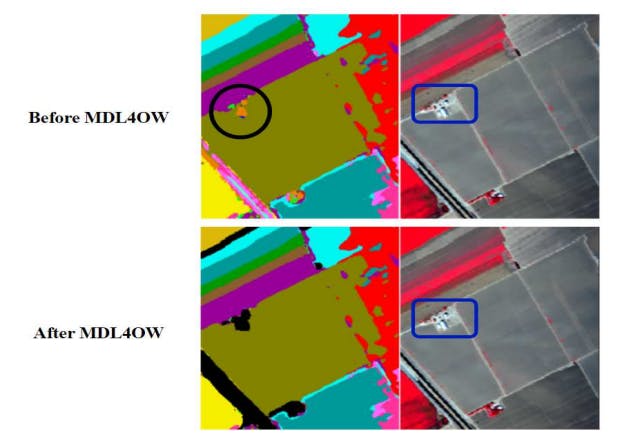
The MDL4OW model, presented by [41], employs a few-shot based deep learning architecture to classify five unknown classes through training on nine known classes. Notably, the proposed model departs from traditional centroidbased methods, instead utilizing extreme value theory from a statistical model, as depicted in Figure 3. Furthermore, the authors introduced a novel evaluation metric, the mapping error, which is particularly sensitive to imbalanced classification scenarios frequently encountered in hyperspectral remote sensing image datasets. Mathematical expression of the mapping error for C classes is provided in 10, subject to constraints expressed in 11 and 12.
The mathematical expression of 10 represents the mapping error, where Ap,i signifies the predicted area of the ith class and Agt,i denotes the corresponding ground-truth area. Here, C represents the total number of known classes (as in the case of their work, where it is equal to 9), while C + 1 refers to the total number of unknown classes (which, in their work, is 5). The Pavia dataset, the Indian Pines dataset, and the Salinas Valley dataset are the datasets that are evaluated in their study. Apart from mapping error, the Openess metric [42] is also considered as a benchmark for their evaluation, which evaluates the degree of openness for a given dataset in open-world classification, in addition to OA and micro F1 score.
Equation 13 elucidates the association between Openess and the number of training and testing data, Ntrain and Ntest, respectively.
Figure 5 presents an illustration of how the MDL4OW methodology effectively identifies unknown classes, as demonstrated through an example image. The top portion of the figure highlights the road (denoted by black) and the house (enclosed by a dark-blue border), both of which cannot be assigned to any known class, as they were not presented a priori. However, a standard deep learning model would still require assigning them a label, as it was not trained to recognize these specific labels. In contrast, the MDL4OW approach (depicted in the bottom portion of the figure) is adept at identifying and marking unknown classes (denoted by black), effectively applying the proposed scheme.
Employing adaptive subspace learning and feature-wise transformation (SSFT) techniques, [43] aimed to enhance feature diversities and minimize overfitting. In particular, they incorporated a 3-D local channel attention residual network to extract features, and evaluated their algorithm against the SOTA using the Salinas, Pavia, and Indian Pines datasets. To compare with other SOTA, they performed a 5-shot, 10-shot, 15-shot, 20-shot, and 25- shot evaluation approach. In the study conducted by [44], a pseudo-labelling approach was adopted to augment the feature extraction procedure of their network using limited samples and also reduce overfitting. The soft pseudo label was computed by taking into account the euclidean distance between the unlabelled samples and the other agents with each labelled sample acting as a reference. Two sub-networks, namely the 3D-CNN and the SSRN (based on the ResNet), were proposed to function as the feature extractor. The dataset used for evaluation comprised of Pavia, Indian Pines and Salinas Valley. For comparison with other SOTA approaches, a 1-shot, 3-shot, and 5-shot evaluation approach was employed. Results showed that the proposed model outperformed all existing SOTA approaches in all three evaluation settings.
Using a 3D residual convolutional block attention network (R3CBAM), the authors of [45] demonstrated how to effectively learn spectral-spatial features in a more salient manner with small training samples. The CBAM is incorporated as an attention network. Meta-learning is employed, where a set of Euclidean distances from the test query set from known class prototypes are leveraged, and unknown class queries are labelled as outliers and are recognized without setting a threshold value beforehand. The evaluation of their approach was performed on the Indian Pines, Pavia, Salians, and Houston datasets. During the training of their network, a query set was generated from six base classes randomly chosen, and the support set was formed from samples using three randomly chosen query classes. A 1-shot and 5-shot OSR performance evaluation were carried out and compared with SOTA methods. In both 1-shot and 5-shot OSR evaluations, the results indicated that the proposed method outperformed the SOTA methods.
Expanding upon previous works, [46] proposed the Heterogeneous FewShot Learning (HFSL) approach for remote sensing classification with few samples per class. The method initially learns from data randomly sampled from the mini-ImageNet dataset to obtain transferable knowledge, followed by separating the data into support and query sets. A spectral-spatial fusion fewshot learning model is proposed that extracts spectral information through 1D mathematical operations and spatial information through a CNN with VGG16 pre-trained weights in the first layer. Their evaluation approach includes the Pavia University and Houston datasets, with a 5-shot performance evaluation against state-of-the-art methods. Building on this, [47] adds Knowledge Distillation (KD) to the approach, making it simpler to identify important parts of small samples, even with a shallower network. Further knowledge transfer and fine-tuning of the classifier model are performed, with evaluation on the Pavia University and Indian Pines datasets.
Using the Dirichlet-Net for feature extraction, [48] suggested a few-shot multi-task transfer learning strategy that aims to maintain classification accuracy across several domains. The key concept is to extract fundamental representations that are common to the same type of object features across domains, with the aim of circumventing the requirement for more ground-truth labels from the target domain. The Pavia University dataset was employed to assess their approach, with a 5-sample per class evaluation strategy (i.e., 5-shot evaluation). Results showed that the proposed method was able to accurately classify unseen target domain samples, demonstrating the efficacy of the approach.
The authors of [49] proposed a new Attention-weight Graph Convolutional Network (AwGCN) for a few-shot method of quantifying and correlating internal features in hyperspectral data. This is followed by a semi-supervised label propagation of the node labels (features) from the support to query set via the GCN using the trained weights of the attention graphs. Unlike other approaches, they did not rely on pre-trained CNN-based weights as feature extractors but instead utilized a graph-based approach. The proposed method was evaluated on the Indian Pines dataset using 1-shot, 3-shot, and 5-shot approaches and on the Pavia University dataset using a 5-shot approach. In a similar vein, [50] proposed a GraphSAGE-based approach that utilizes spectral and spatial feature information to greatly reduce algorithmic space and time complexity. Their approach was evaluated on the Pavia University, Indian Pines, and Kennedy Space Centre dataset using a 30-samples per class evaluation approach for training and a 15-samples per class evaluation approach for validation. Their results demonstrated improved accuracy compared to other state-of-the-art methods, with a 6.7% increase in accuracy on the Pavia University dataset and a 5.2% increase on the Indian Pines dataset. Furthermore, the Kennedy Space Centre dataset improved accuracy by 7.1%, making their approach a strong contender for further research. This improvement in accuracy indicates that their approach is more effective than other methods and could be a potential solution for future applications.
The proposed method by [51], Self-Attention and Mutual-Attention FewShot Learning (SMA-FSL), utilizes a 3D convolutional feature embedding network for spectral-spatial extraction, coupled with a self-attention module to extract prototypes from each class in the support set and a mutual-attention module that updates and aligns these category prototypes with the query set. Attention-based learning is emphasized, where crucial features are enhanced while noisy features are reduced. To assess the efficacy of their approach, it is evaluated on the Houston, Botswana [28], Chikusei [52] and Kennedy Space Center datasets using 1-shot, 5-shot, and 15-shot evaluation approaches. These datasets are chosen for their diverse range of terrain and vegetation, allowing for a comprehensive evaluation of the model’s performance. The results of the evaluation show that the approach is effective across all datasets, demonstrating its versatility in different environments.
The proposed work by [53] presents an incremental learning-based method that constantly updates the classifier by utilizing few-shot samples, allowing recognition of new classes while retaining knowledge of previous classes. The feature extractor module is implemented using a 20-layer ResNet, and the few-shot class incremental learning (FSCIL) is carried out via a constantly updated classifier (CUC), which is further enhanced by incorporating an attention mechanism for measuring the prototype similarity between each training and test sample class. The Pavia University dataset was employed for evaluating the performance of this approach using a 5-shot evaluation strategy. The results obtained showed that the proposed FSCIL with CUC and attention mechanism achieved superior performance compared to the baseline method. Furthermore, it was also observed that the performance improved with an increase in the number of shots.
Most previous works have employed CNN-based architectures for few-shot learning in hyperspectral image classification. However, CNNs can struggle with modeling long-range dependencies in spectral-spatial data when training samples are scarce. This has motivated recent interest in transformer architectures as an alternative.
In a notable contribution, Shi et al. [54] addressed the challenge of performance degradation observed in hyperspectral image classification methods when only a limited number of labeled samples are available for training. They proposed a unified framework with a Transformer Encoder and Convolutional Blocks to enhance feature extraction without needing extra data. The Transformer Encoder provides global receptive fields to capture longrange dependencies, while the Convolutional Blocks model local relationships. Their method achieved state-of-the-art results on few-shot hyperspectral tasks using public datasets, demonstrating the potential of transformers to advance few-shot learning in this domain.
Huang et al. [55] also recognized limitations of CNN-based models for fewshot hyperspectral image classification. They highlighted the inherent difficulty of CNNs in effectively capturing long-range spatial-spectral dependencies, especially in scenarios with limited training data. They proposed an improved spatial-spectral transformer (HFC-SST) to overcome this, inspired by transformers’ strong modeling capabilities for long-range relationships. HFC-SST generates local spatial-spectral sequences as input based on correlation analysis between spectral bands and adjacent pixels. A transformer-based network then extracts discriminative spatial-spectral features from this sequence using only a few labeled samples. Experiments on multiple datasets demonstrated that HFC-SST outperforms CNNs and prior few-shot learning methods by effectively modeling local long-range dependencies in limited training data. This further highlights the potential of transformers to advance few-shot hyperspectral classification through robust spatial-spectral feature learning.
The work by Wang et al. [56] also explores cross-domain few-shot learning for hyperspectral image classification, where labeled samples in the target domain are scarce. They propose a convolutional transformer-based few-shot learning (CTFSL) approach within a meta-learning framework. Most prior cross-domain few-shot methods rely on CNNs to extract statistical features, which only capture local spatial information. To address this, CTFSL incorporates a convolutional transformer network to extract both local and global features. A domain aligner maps the source and target domains to the same space, while a discriminator reduces domain shift and distinguishes feature origins. By combining few-shot learning across domains, transformer-based feature extraction, and domain alignment, their method outperforms state-of-the-art techniques on public hyperspectral datasets. This demonstrates the potential of transformers and cross-domain learning strategies to advance few-shot hyperspectral classification with limited labeled data.
Recently, Ran et al. [57] proposed a novel deep transformer and few-shot learning (DTFSL) framework for hyperspectral image classification that aims to overcome the limitations of CNNs. The DTFSL incorporates spatial attention and spectral query modules to capture long-range dependencies between non-local spatial samples. This helps reduce uncertainty and better represent underlying spectral-spatial features with limited training data. The network is trained using episode and task-based strategies to learn an adaptive metric space for few-shot classification. Domain adaptation is also integrated to align distributions and reduce variation across domains. Experiments on three public HSI datasets demonstrated that the transformer-based DTFSL approach outperforms state-of-the-art methods by effectively modeling relationships between non-local spatial samples in a few-shot context. This indicates transformers could be a promising alternative to CNNs for few-shot hyperspectral classification.
In another work, [58] introduces a Vision Transformer (ViT)-based architecture for FSL that employs feedback learning. The Few-Shot Transformer Network (FFTN) developed by [58] combines spatial and spectral attention of the extracted features learned by the transformer component. By incorporating XAI, the model’s decision-making process can be made more transparent and interpretable, thereby enhancing its trustworthiness and reducing the risk of biases. Additionally, the network incorporates meta-learning with reinforced feedback learning on the source set as the first step to improving the network’s ability to identify misclassified samples through reinforcement. The second step is target-learning with transductive feedback training on the target sample to learn the distribution of unlabeled samples. This two-step process helps the network adapt to the target domain, thus improving its accuracy and reducing the risk of overfitting.
The table 3 provides an overview of some of the existing methods for fewshot approaches in hyperspectral image classification. It lists the dataset and metrics used, as well as the type of feature extractor approach for each method
and the year of publication. The addition of XAI techniques could enhance the transparency and interpretability of these methods.
A 5-shot evaluation method is mostly used to measure how well the proposed methods work on the Chikusei, Salinas Valley, and Pavia University datasets. Table 3 gives an overview of the methods that have been discussed, including the datasets and evaluation metrics, the learning methods that were used, and the year the paper was published. From the works that were talked about, it is clear that the Pavia, Indian Pines, and Salinas Valley datasets are the ones most often used to compare algorithms.
In the table 3, most of the few-shot approaches for hyperspectral image classification have not incorporated XAI for better interpretability. However, the addition of XAI techniques could enhance transparency and provide insights into the decision-making process of the models. One way to incorporate XAI is by using visualization techniques to highlight the features or regions of the image that contribute to the model’s prediction. Another approach is to use saliency maps to identify the most important regions of the input image that influence the model’s decision. Additionally, model-agnostic methods such as LIME or SHAP can provide insights into the decision-making process of the models. Overall, the incorporation of XAI techniques in few-shot approaches for hyperspectral image classification can improve the transparency and interpretability of the models and facilitate their adoption in real-world applications.
6.2 Few-shot learning in VHR image classification
All studies in this section employ the OA metric unless otherwise stated. [59] proposes a novel zero-shot scheme for scene classification (ZSSC) based on the visual similarity of images from the same class. Their work employs the UC Merced dataset for evaluation, where a number of classes were randomly chosen as observed classes while the rest were unseen classes. Additionally, the authors incorporate the RSSCN7 dataset [60] and a VHR satellite-based image database consisting of instances from both observed and unknown classes in an unlabeled format. To address the issue, the authors adopt the word2vec [61] model to represent each class as a semantic vector and use a K-Nearest Neighbor (KNN) graph-based model to implement sparse learning for label refinement. The refinement also helps to denoise any noisy label during the zero-shot classification scheme. Their proposed model achieves significant performance gains compared to existing SOTA zero-shot learning models with linear computational complexity. Furthermore, the proposed model can handle a large number of classes with minimal memory requirements. Some of the newest attempts to use few-shot learning and UAV-based data was carried out by [62, 63].
The work presented by [64] proposed a hierarchical prototypical network (HPN) as a novel approach for few-shot learning, which is evaluated on the RESISC45 dataset. The HPN model is designed to perform analysis of highlevel aggregated information in the image, followed by fine-level aggregated information computation and prediction, utilizing prototypes associated with each level of the hierarchy as described in (4). The evaluation protocol involves a 5-way 1-shot and 5-way 5-shot classification approach within the standard meta-learning framework. In the proposed approach, the ResNet-12 model serves as the backbone for the first stage of feature extraction. The extracted features are then passed through a linear layer to obtain the final feature representation. This feature representation is used for the classification task in the second stage.
In a bid to augment the performance of few-shot task-specific contrastive learning (TSC), [65] introduced a self-attention and mutual-attention module (SMAM) that scrutinizes feature correlations with the aim of reducing any background interference. The adoption of a contrastive learning strategy facilitates the pairing of data using original images from diverse perspectives. Ultimately, the aforementioned approach enhances the potentiality to distinguish intra-class and inter-class image features. The NWPU-RESISC45, WHU-RS19, and UC Merced datasets were leveraged for their algorithmic evaluation, which comprised a 5-way 1-shot and 5-way 5-shot classification approach that was scrutinized and compared. Furthermore, [66] introduced a multiple-attention approach that concurrently focuses on the global and local feature scale as part of their Multi-Attention Deep Earth Mover Distance (MAEMD) proposed network. Local attention is geared towards capturing significant and subtle local features while suppressing others, thereby improving representational learning performance and mitigating small inter-class and large intra-class differences. Their approach was evaluated on the UC-Merced, AID, and OPTIMAL-31 [67] datasets with a 1-shot, 5-way 5-shot, and 10-shot evaluation approach. As evidence of the success of the local attention strategy, the results showed that the model achieved state-of-the-art performance across all datasets.
Another illustration of an attention-based model is presented by [68] with the introduction of the Self-Attention Feature Selection Network (SAFFNet). This model aims to integrate features across multiple scales using a self-attention module, in a similar manner to that of a spatial pyramid network. The Self-Attention Feature Selection (SAFS) module is employed to better match features from the query set with the fused features in the class-specified support set. Experimental analysis was conducted on the UC-Merced, RESISC45, and AID datasets, using a 1-shot and 5-shot classification evaluation approach. The results showed that SAFS was able to improve the performance of the baseline model for all datasets, with the largest improvement seen on the AID dataset.
Incorporating a feature encoder to learn the embedded features of input images as a pre-training step, [69] proposed the Task-Adaptive Embedding Network (TAE-Net). To choose the most informative embedded features during the learning task in an adaptive manner, a task-adaptive attention module is employed. By utilizing only limited support samples, the prediction is performed on the query set by the meta-trained network. For their algorithmic evaluation, they employed the NWPU-RESISC45, WHU-RS19, and UC Merced dataset. A 5-way 1-shot and 5-way 5-shot classification approach were implemented for comparison. The results were evaluated based on accuracy, precision, recall, and F1-score metrics. Furthermore, the models were compared in terms of their training time and memory usage.
The study conducted by [70] aims to achieve few-shot learning through deep economic networks. The deep economic network incorporates a two-step simplification process to reduce training parameters and computational costs in deep neural networks. The reduction of redundancy in input image, channel, and spatial features in deep layers is achieved. In addition, teacher knowledge is utilized to improve classification with limited samples. The last block in the model includes depth- and point-wise convolutions that effectively learn crosschannel interactions and enhance computational efficiency. The algorithmic evaluation of the model is conducted on three datasets, namely the UC-Merced, RESISC45, and RSD46-WHU. The evaluation is carried out using a 1-shot and 5-shot approach on RESISC45 and the RSD46-WHU, and an additional 10- shot evaluation is implemented on the UC-Merced dataset. The model shows promising performance across all datasets, with the highest accuracy coming from the 10-shot evaluation.
The introduction of the Discriminative Learning of Adaptive Match Network (DLA-MatchNet) for few-shot classification by [71] incorporated the attention mechanism in the channel and spatial domains to identify the discriminative feature regions in the images through the examination of their inter-channel and inter-spatial relations. In order to address the challenges posed by large intra-class variances and inter-class similarity, the discriminative features of both the support and query sets were concatenated, and the most relevant pairs of samples were adaptively selected by a matcher, which was manifested as a multi-layer perceptron. The UC-Merced, RESISC45, and WHU-RS19 datasets were employed for the state-of-the-art (SOTA) evaluation, utilizing a 5-way 1-shot and 5-shot approach for all datasets. The results confirmed the superior accuracy of the proposed method over the SOTA, proving its utility for remote sensing image retrieval.
Graph-based methods have also been employed in the very high-resolution (VHR) domain for few-shot learning. In this regard, [72] proposed a multi-scale graph-based feature fusion (MGFF) approach that involves a feature construction model that converts typical pixel-based features to graph-based features. Subsequently, a feature fusion model combines the graph features across several scales, which enhances the distinguishing ability of the model via integrating the essential semantic feature information and thereby improving few-shot classification capability. The authors conducted the algorithmic evaluation on the RESISC45 and WHU-RS19 datasets using a 5-way 1-shot and 5-way 5-shot classification approach. In addition, [73] proposed Graph Embedding Smoothness Network (GES-Net), which implements embedded smoothing to regularize the embedded features. This not only effectively extracts higher-order feature relations but also introduces a task-level relational representation that captures graph relations among the nodes at the level of the whole task, thereby enhancing the node relations and feature discerning capabilities of the network. The work is evaluated on the RESISC45, WHU-RS19, and UC Merced datasets using 5-way 1-shot and 5-shot comparison approaches. Episodic training was adopted, where each episode refers to a task and is comprised of N uniformly sampled categories without replacement and the query and support set. The support set contains K samples from each of the N categories, and the query set contains a single sample from each of the N categories. The samples in the query and support sets are selected from a larger pool of available samples in a random manner, ensuring that each episode is unique.
Few-shot strategies for VHR image classification can benefit greatly from the application of XAI methods like explainable graph neural networks and attention mechanisms. Transparency, accountability, bias detection, and fairness issues can all be improved with the help of xGNNs because they shed light on the model’s decision-making process. To make the model’s decisions more understandable and transparent, attention mechanisms can draw focus to key features and nodes in the graph. In principle, these methods could make graph-based few-shot classification models more reliable and easy to understand.
Table 4 presents a similar format to Table 3, depicting a comprehensive summary of the aforementioned methods in the very high-resolution (VHR) classification domain. It can be observed that the RESISC45, UC-Merced, and WHU-RS19 dataset are among the most frequently employed for algorithmic comparison, as seen in the subset of the existing works highlighted.
Furthermore, the majority of the approaches presented in Table 4 incorporate attention mechanisms and graph-based methods for few-shot VHR classification. The MGFF approach presented by [72] is an example of a graph-based method, while the DLA-MatchNet presented by [71] is an example of an approach that utilizes attention mechanisms. Similarly, the GES-Net presented by [73] also uses graph-based methods in its approach. These techniques aim to extract more relevant and informative features from the input images, which can enhance the performance of few-shot VHR classification systems.
6.3 Few-shot learning in SAR image classification
SAR (Synthetic Aperture Radar) is a remote sensing technology for capturing high-resolution images of the Earth’s surface regardless of the weather conditions, making it a valuable tool in various applications such as agriculture, forestry, and land use management. However, the availability of SAR-based data is often limited in comparison to hyperspectral or VHR-based data, mainly due to the high cost of SAR sensors and the complexity of SAR data processing. As a result, traditional classification approaches for SAR data are often challenged by insufficient training data and the high intra-class variability, which leads to a pressing need for the development of few-shot learning methods that can effectively tackle these challenges. Therefore, a review of emerging few-shot learning methods in the SAR-based classification domain is highly desirable to advance the state-of-the-art and enable more accurate and efficient classification of SAR data.
The integration of XAI techniques, such as explainable graph neural networks (xGNNs) and attention mechanisms, can significantly enhance the proposed few-shot transfer learning technique for SAR image classification presented by [74]. This novel approach uses a connection-free attention module to selectively transfer shared features between SAR and Electro-Optical (EO) image domains, reducing the dependence on additional SAR samples, which may not be feasible in certain scenarios. By using xGNNs, the authors can provide insights into the decision-making process, increasing transparency and accountability, which is particularly crucial for SAR image classification due to restricted data access and high acquisition costs. The attention mechanism can highlight relevant features and nodes in the graph, improving the model’s interpretability and transparency, and ultimately, its performance and trustworthiness. In addition, the authors implemented a Bayesian convolutional neural network to update only relevant parameters and discard those with high uncertainties. The evaluation was performed on three EO datasets that included ships, planes, and cars, with SAR images obtained from [75], [76], and MSTAR. The classification accuracy (OA) value was used as the performance metric, with the 10-way k-shot approach achieving an OA of approximately 70%, outperforming other approaches. Overall, incorporating XAI techniques can potentially improve the performance and trustworthiness of the proposed few-shot transfer learning technique for SAR image classification.
In the pursuit of effective few-shot classification, [77] proposed a Handcrafted Feature Insertion Module (HcFIM), which combines learned features from CNN with hand-crafted features via a weighted-concatenated approach to aggregate more priori knowledge. Their Multi-scale Feature Fusion Module (MsFFM) is used to aggregate information from different layers and scales, which helps distinguish target samples from the same class more easily. The combination of MsFFM and HcFIM forms their proposed Multi-Feature Fusion Network (MFFN). To tackle the challenge of high similarity within interclasses in SAR images, the authors proposed the Weighted Distance Classifier (WDC), which computes class-specific weights for query samples in a datadriven manner, distributed using the Euclidean distance as a guide. They also incorporated weight generation loss to guide the process of weight generation. The benchmark MSTAR dataset and their proposed Vehicles and Aircraft (VA) dataset were used for evaluation, where a 4-way 5-shot evaluation approach was used for MSTAR and a 4-way 1-shot evaluation approach was used for VA. The Average Accuracy (AA) was used as the evaluation metric throughout. The evaluation results demonstrated that the VA dataset had a higher AA than MSTAR, indicating that it was better suited for fine-grained classification tasks.
In the study by [36], a novel approach to few-shot classification is introduced through the integration of meta-learning. This method is characterized by the synergistic use of two primary components: a meta-learner and a base-learner. The meta-learner’s primary function is to determine and store the learning rates, along with generalized parameters pertinent to both the feature extractor and classifier. Its objective is to discern an optimal initialization parameter, thereby refining update strategies by meticulously examining the distribution of few-shot tasks. This optimal initialization is instrumental in setting the algorithm on a path that potentially accelerates convergence and improves performance. Following this, the meta-learner plays a pivotal role in directing the base-learner. Here, the base-learner is conceptualized as a classifier model specifically tailored for SAR-based target detection. Its design ensures enhanced convergence efficiency under the guidance of the meta-learner.
Recognizing the challenges posed by more complex tasks, the study further augments its methodology with a hard-task mining technique. This is particularly valuable in emphasizing and addressing tasks that are inherently more challenging. For the acquisition of transferrable knowledge—a crucial aspect of few-shot learning—the 4CONV network is employed during the meta-training phase. The efficacy of this approach, termed as MSAR in the publication, was rigorously tested on two datasets: the MSTAR dataset and the newly proposed NIST-SAR dataset. Evaluations were carried out using both the 5-way 1-shot and 5-way 5-shot paradigms, with the mean accuracy (AA) serving as the benchmark metric. The empirical results were telling; the MSAR method surpassed baseline methodologies in performance for both tasks. Specifically, it achieved an impressive AA of 86.2% for the 5-way 1-shot task and an even more commendable 97.5% for the 5-way 5-shot task.
The paper by [37] proposed a novel few-shot cross-domain transfer learning approach to transfer knowledge from the electro-optical (EO) domain to the synthetic aperture radar (SAR) domain. This is accomplished by utilizing an encoder in each domain to extract and embed individual features into a shared embedded space. The encoded parameters are updated continuously by minimizing the discrepancies in the marginal probability distributions between the two embedded domains. Since the distributions are generally unknown in few-shot learning, the authors approximate the optimal transport discrepancy measurement metric using the Sliced Wasserstein Distance (SWD) for more efficient computation. The approach is evaluated on a dataset of SAR images acquired by [78] for detecting the presence or absence of ships. The classification accuracy (OA) is used as the evaluation metric for this approach. The results show that this approach can achieve an OA of over 90%, indicating that it is a reliable and accurate method for ship detection.
In their study on few-shot ship recognition using the MSTAR dataset, [79] proposed a Deep Kernel Learning (DKL) approach that harnesses the nonparametric adaptability of Gaussian Processes (GP). The kernel function used in their approach is mathematically defined in (14) as a Gaussian kernel
Graph-based learning methods have gained popularity in SAR image classification similar to hyperspectral and VHR image classification. To enhance feature similarity learning among query images and support samples more effectively using graphs, [80] proposed a relation network based on the embedding network for feature extraction and attention-based Graph Neural Networks (GNN) in the form of a metric network [81]. The channel attention module in CBAM is incorporated into the GNN. MSTAR is utilized for evaluation, and a 5-way 1-shot comparison is used with classification accuracy (OA) as the metric. In addition, Yang proposed a Mixed-loss Graph Attention Network (MGA-Net) which utilizes a multi-layer GAT combined with a mixed-loss (embedding loss and classification loss) training to increase inter-class separability and speed up convergence. The MSTAR dataset and the OpenSARShip
dataset were used for comparison, and a 3-way 1-shot and 3-way 5-shot classification evaluation were utilized for comparison of the results represented by the classification accuracy (OA) and the confusion matrix. The results showed that the MGA-Net achieved a better performance than the baseline models in both datasets, indicating that the multi-layer GAT and mixed-loss training had a positive effect on the classification accuracy.
Recently, Zhao et al. [82] proposed an instance-aware transformer (IAT) model for few-shot synthetic aperture radar automatic target recognition (SAR-ATR). They recognize that modeling relationships between query and support images is critical for few-shot SAR-ATR. The IAT leverages transformers and attention to aggregate relevant support features for each query image. It constructs attention maps based on similarities between query and support features to exploit information from all instances. Shared cross-transformer modules align query and support features. Instance cosine distance during training pulls same-class instances closer to improve compactness. Experiments on few-shot SAR-ATR datasets show IAT outperforms state-of-the-art methods. Visualizations also demonstrate improved intra-class compactness and inter-class separation. This highlights the potential of transformers and attention for few-shot SAR classification by effectively relating queries to supports and learning discriminative alignments.
CNNs have been dominant for SAR-ATR, but struggle with limited training data. To address this, Wang et al. [83] proposed a convolutional transformer (ConvT) architecture tailored for few-shot SAR ATR. They recognize that CNNs are hindered by narrow receptive fields and inability to capture global dependencies in few-shot scenarios. ConvT constructs hierarchical features and models global relationships of local features at each layer for more robust representation. A hybrid loss function based on recognition labels and contrastive image pairs provides sufficient supervision from limited data. Auto augmentation further enhances diversity while reducing overfitting. Without needing additional datasets, ConvT achieves state-of-the-art few-shot SAR ATR performance on MSTAR by effectively combining transformers with CNNs. This demonstrates transformers can overcome CNN limitations for few-shot SAR classification by integrating local and global dependencies within and across layers.
Table 5 provides an overview of the various few-shot learning methods that have been proposed for SAR classification. The table summarizes the key aspects of each approach, including the name of the method, the year of publication, the dataset used for evaluation, and the evaluation metric used. It is noteworthy that among the subset of existing works described in this review, the MSTAR dataset is the most commonly used for algorithmic comparisons. The MSTAR dataset has been widely used in SAR classification due to its relatively large size and the diversity of the target types that it contains. Overall, the methods discussed in Table 5 highlight the potential of few-shot learning approaches in the SAR domain, and demonstrate the effectiveness of various techniques such as graph-based learning, deep kernel learning, and meta-learning. These approaches have the potential to enable more efficient and accurate classification of SAR data, which can have important applications in fields such as remote sensing, surveillance, and defense. XAI techniques can be really useful for identifying objects in radar images. Because researchers usually have limited access to radar data and it’s expensive to get new radar images, techniques like explainable graph neural networks and attention mechanisms are helpful.
Authors:
(1) Gao Yu Lee, School of Electrical and Electronic Engineering, Nanyang Technological University, 50 Nanyang Ave, 639798, Singapore (GAOYU001@e.ntu.edu.sg);
(2) Tanmoy Dam, School of Mechanical and Aerospace Engineering, Nanyang Technological University, 65 Nanyang Drive, 637460, Singapore and Department of Computer Science, The University of New Orleans, New Orleans, 2000 Lakeshore Drive, LA 70148, USA (tanmoy.dam@ntu.edu.sg);
(3) Md Meftahul Ferdaus, School of Electrical and Electronic Engineering, Nanyang Technological University, 50 Nanyang Ave, 639798, Singapore (mferdaus@uno.edu);
(4) Daniel Puiu Poenar, School of Electrical and Electronic Engineering, Nanyang Technological University, 50 Nanyang Ave, 639798, Singapore (EPDPuiu@ntu.edu.sg);
(5) Vu N. Duong, School of Mechanical and Aerospace Engineering, Nanyang Technological University, 65 Nanyang Drive, 637460, Singapore (vu.duong@ntu.edu.sg).
This paper is