
In the field of data integration, when facing thousands of synchronization tasks, the performance bottleneck often lies not in the data transmission itself, but in "metadata management." Classloader conflicts, Checkpoint pressure, and frequent database metadata requests are the "three mountains" that crush clusters. As a next-generation integration engine, SeaTunnel Zeta delivers a highly reliable and high-performance answer through a sophisticated metadata caching mechanism.
This mechanism solves the performance bottlenecks of traditional data tools in classloading, state management, and metadata processing through three dimensions: intelligent caching, distributed storage, and automated management.
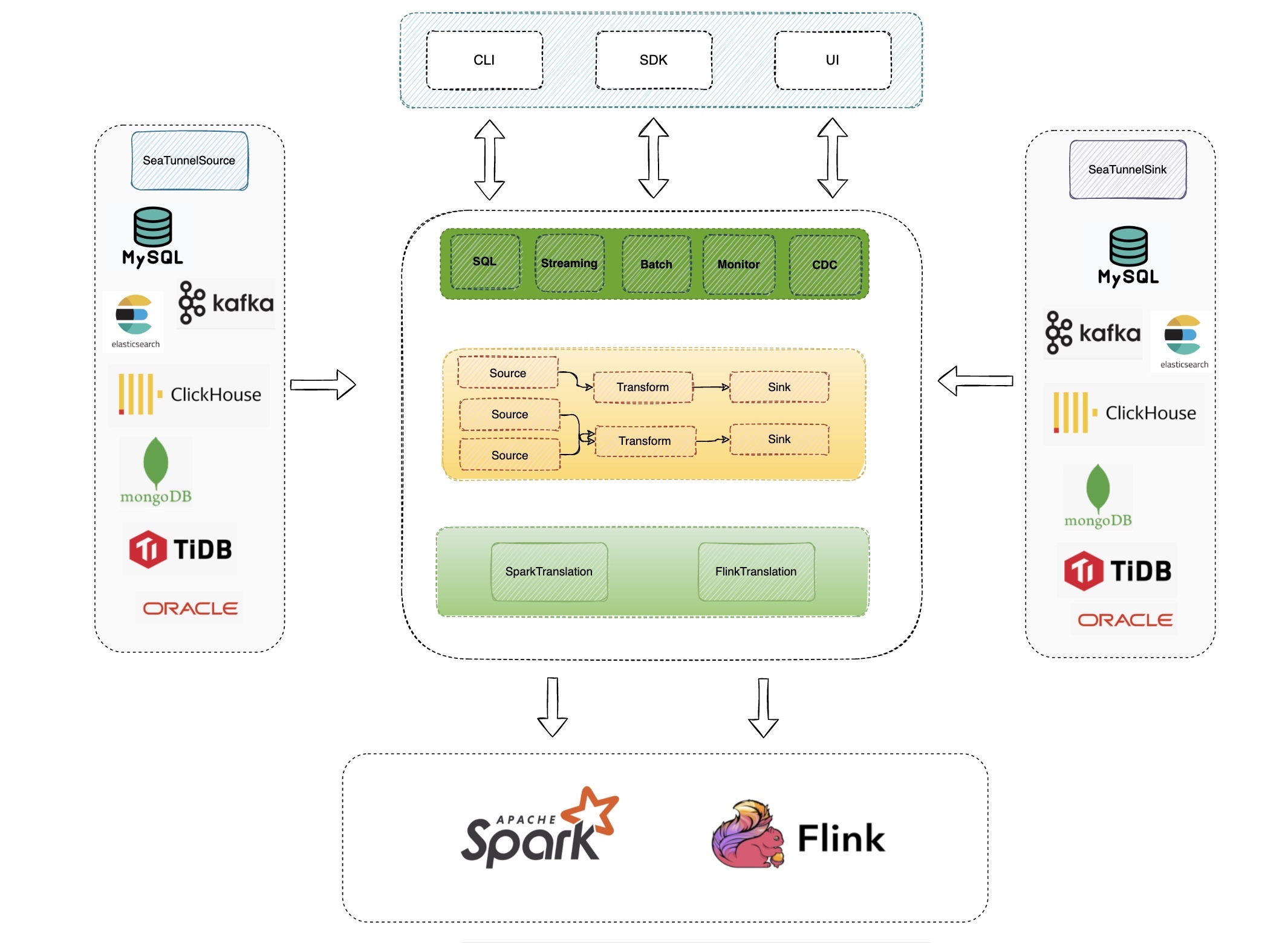
Caching Mechanism Detailed
1. Memory Strategy for Classloader Reuse
In traditional distributed engines, each job usually creates an independent classloader. When the task volume reaches thousands or tens of thousands, the Metaspace quickly fills up because it loads a large number of duplicate connector Jar packages, eventually leading to OOM (Out of Memory) crashes.
SeaTunnel's classloader caching mechanism implements a clever "shared memory" solution through DefaultClassLoaderService. Identifying the fingerprint of a Connector's Jar package, it allows different jobs using the same connector to share the same ClassLoader instance.
Core Implementation Principles:
- In cache mode, all jobs share the same classloader (jobId is uniformly set to 1L).
- Use
classLoaderReferenceCountto track the usage of each classloader. - The classloader is only truly released when the reference count reaches 0, avoiding premature recycling.
Configuration:
seatunnel:
engine:
classloader-cache-mode: true
This mechanism borrows the reference counting idea from memory management; the classloader is only truly uninstalled when all associated jobs have ended, and the count returns to zero. This delayed-release design ensures the number of core loaders remains stable regardless of job volume, greatly saving system overhead.
2. Fault-Tolerant Evolution of Distributed Checkpoints
SeaTunnel's state management is based on the classic Chandy-Lamport algorithm, but its innovation lies in deep integration with the distributed memory grid Hazelcast (IMap). Unlike engines like Flink that rely heavily on external state backends (such as RocksDB), SeaTunnel Zeta uses IMap as a primary cache for state, achieving millisecond-level state access. Data is organized in a rigorous hierarchy of {namespace}/{jobId}/{pipelineId}/{checkpointId}/.
Storage Architecture:
- Supports HDFS, S3, OSS, and other backend storage.
- Checkpoint data is stored according to the
{namespace}/{jobId}/{pipelineId}/{checkpointId}/structure. - Supports incremental checkpoints and precise state recovery.
Configuration Example:
seatunnel:
engine:
checkpoint:
interval: 300000
timeout: 10000
storage:
type: hdfs
plugin-config:
fs.defaultFS: hdfs://localhost:9000
This design not only supports incremental snapshots to reduce I/O pressure but, more importantly, achieves storage decoupling through an SPI plugin architecture. Once the IMap in memory completes a state update, data can be asynchronously persisted to HDFS or S3, forming a "memory read, persistent backup" dual guarantee to ensure tasks restart from a precise location after a failure.
3. Catalog Metadata Caching to Relieve Source Database Pressure
When massive tasks start in parallel, frequent requests to the source database for Schemas lead to severe connection latency or can even crash metadata services like Hive Metastore or MySQL. SeaTunnel introduces a Catalog caching strategy at the Connector Layer, transforming "high-frequency point-to-point requests" into "engine-side local extraction."
- JDBC Connector: Table Structure Snapshots and Fast Splitting: SeaTunnel performs "structure sampling" on target databases via
CatalogUtils, caching full information such as table comments, field precision, and primary key constraints into theJobMastercontext. This not only speeds up job initialization but, crucially, allows using cached index information to directly calculate Reading Splits, eliminating multiple database round-trips and significantly shortening the preparation time for synchronizing tens of thousands of tables. - Hive Connector: Offloading Single-Point Pressure from Metastore: For the fragile Hive Metastore,
HiveMetaStoreCatalogimplements metadata hosting logic, batch-caching Database, Table, and Partition definitions. This means multiple pipelines under the same cluster can share already loaded table paths and SerDe information. By caching partition mapping relationships, SeaTunnel offloads the parsing pressure from the Metastore to Zeta engine nodes, significantly boosting synchronization throughput for large-scale partitioned tables.
Summary of Mechanism Advantages
1. Resource Utilization Optimization
- Reducing Classloading Overhead: Traditional tools recreate classloaders for every job, whereas SeaTunnel's cache reuse significantly reduces Metaspace occupancy. Tests show the number of classloaders is kept within 3 in cache mode, compared to linear growth in non-cache mode.
- Smart Memory Management: The
history-job-expire-minutesparameter automatically cleans up historical job data (defaulting to 1440 minutes) to prevent memory overflow.
2. High Availability Guarantee
- Distributed State Storage: IMap supports data backup and synchronization across multiple nodes, ensuring single-point failures do not affect overall system availability.
- Persistence Support: IMap can be persisted to external storage like HDFS to achieve automatic recovery after cluster restarts.
3. Significant Performance Improvement
- Thread-Safe Design: All cache operations use
synchronizedandConcurrentHashMapto ensure thread safety. - Precise State Management: The checkpoint mechanism only cleans up completed checkpoint data while retaining uncompleted states, avoiding unnecessary state reconstruction overhead.
Summary of Key Factors for Efficiency Gain
1. Architectural Design Advantages
- Micro-kernel Mode: Checkpoint storage adopts a micro-kernel design, separating the storage module from the engine and allowing users to customize storage implementations.
- Layered Caching: Classloaders, checkpoints, and catalog metadata are managed in layers, optimized independently yet working together.
2. Intelligent Scheduling Strategies
- Reference Counting Mechanism: Accurately tracks resource usage to avoid resource waste and leakage.
- Dynamic Resource Allocation: Supports dynamic slot allocation, automatically adjusting resource usage based on cluster load.
3. Robust Fault-Tolerance
- Automatic Failure Recovery: Precise state recovery based on checkpoints ensures tasks can continue execution from the exact point of failure.
- Data Consistency Guarantee: Ensures metadata consistency and reliability through distributed transactions and two-phase commit protocols.
Key Design Differences From Flink and Spark
SeaTunnel's caching mechanism differs from Flink or Spark primarily in its "lightweight" and "integrated" nature. Flink, as a stream computing platform, manages metadata primarily for stateful services of complex operators; supporting tens of thousands of independent small tasks is not its primary goal. Spark experiences obvious latency during classloading and Context initialization when handling short jobs.
SeaTunnel adopts a typical "micro-kernel" design, sinking metadata caching into the Zeta engine layer so it no longer starts a heavy context for every job. Through a built-in cluster coordinator, SeaTunnel can more finely control the metadata lifecycle of each Slot, making it more resilient when handling large-scale, heterogeneous data source synchronization tasks than traditional computing frameworks.
By intelligently managing classloaders, distributed checkpoint storage, and flexible catalog metadata processing, SeaTunnel has built an efficient, reliable, and scalable data integration platform. Its core strengths include:
- Performance Optimization: Significant reduction in resource overhead via cache reuse and smart scheduling.
- High Availability: Distributed storage and persistence mechanisms ensure system stability.
- Scalability: Micro-kernel design and plugin architecture support flexible expansion.
These designs allow SeaTunnel to excel in large-scale data integration scenarios, making it an ideal choice for enterprise-level data processing.
Best Practices for Production Environments
In actual production deployment, to unleash the power of this mechanism, it is recommended to adopt a "hybrid embedded + independent" strategy. For small clusters, using SeaTunnel’s built-in embedded Hazelcast is sufficient; however, for ultra-large clusters with tens of thousands of tasks, you should adjust the backup strategy in hazelcast.yaml to ensure the backup-count is at least 1, preventing metadata loss if a node goes down.
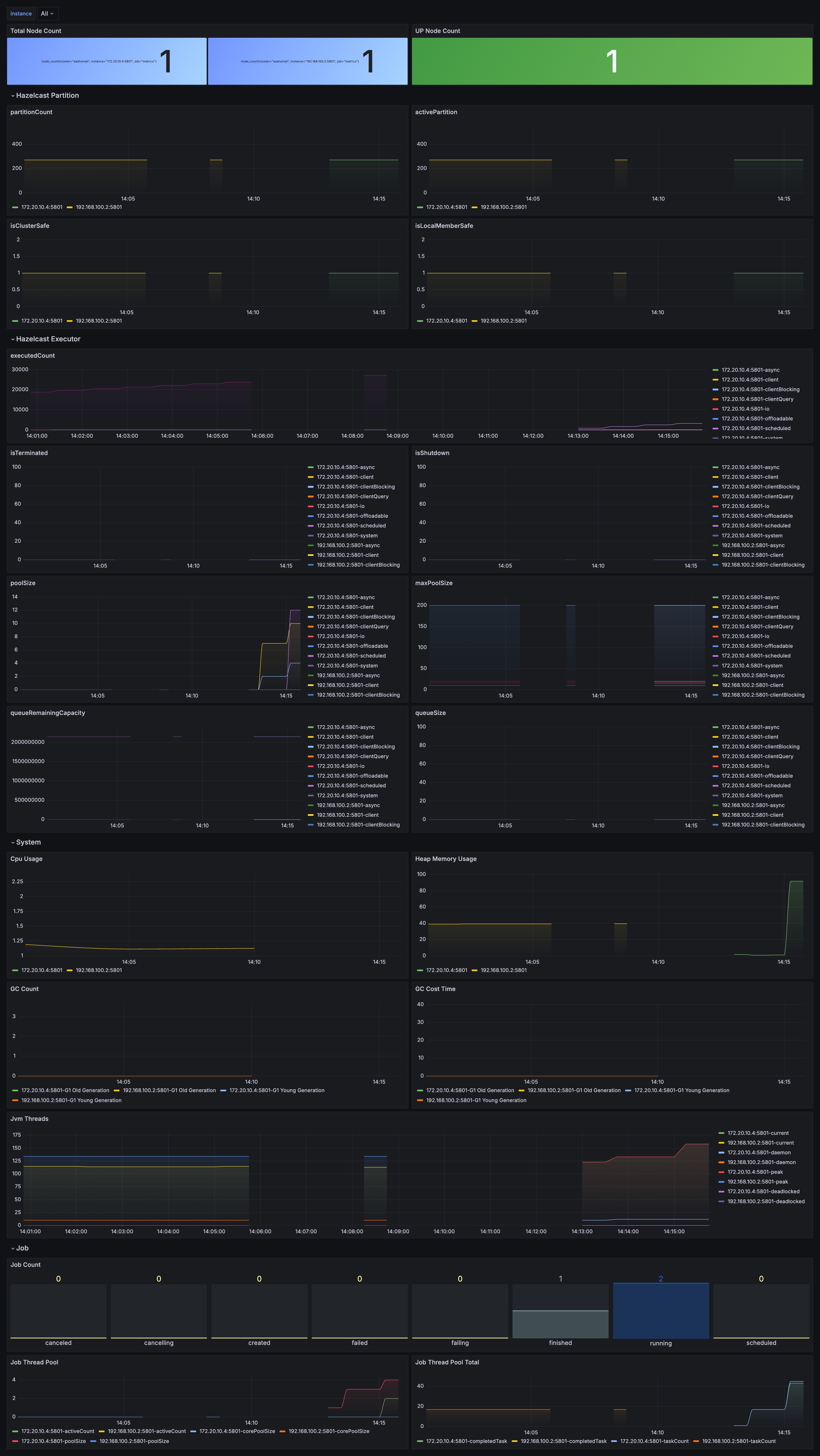
In terms of monitoring, focusing solely on JVM metrics is insufficient. You should prioritize the Zeta engine metrics dashboard, specifically, checkpoint_executor_queue_size and active_classloader_count. If you notice the number of classloaders growing linearly with jobs, it usually indicates that certain custom Connectors are failing to release correctly.
Additionally, properly configuring history-job-expire-minutes is vital; while ensuring traceability, timely recycling of no-longer-needed IMap data is key to maintaining stable cluster operation over long periods.
[story continues]
tags