Table of Links
-
Method
-
Experiments
-
Performance Analysis
Supplementary Material
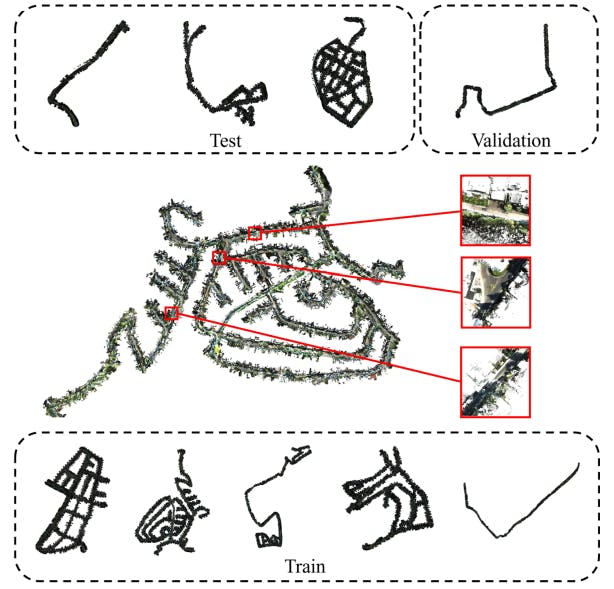
- Details of KITTI360Pose Dataset
- More Experiments on the Instance Query Extractor
- Text-Cell Embedding Space Analysis
- More Visualization Results
- Point Cloud Robustness Analysis
Anonymous Authors
- Details of KITTI360Pose Dataset
- More Experiments on the Instance Query Extractor
- Text-Cell Embedding Space Analysis
- More Visualization Results
- Point Cloud Robustness Analysis
4.3 Evaluation Criteria
In alignment with the current research, we adopt retrieve recall at top 𝑘 (for 𝑘 = 1, 3, 5) as our metric for evaluating the coarse stage capability of text-cell retrieving. For the fine stage evaluation, we use the normalized Euclidean distance error between the groundtruth position and the predicted position. Meanwhile, to evaluate the comprehensive effectiveness of our IFRP-T2P, we assess localization performance based on the top 𝑘 retrieval outcomes, where 𝑘 is set to 1, 5, and 10, and subsequently report on the localization recall. Localization recall is quantified as the fraction of text query accurately localized within predefined error margins, which is typically less than 5, 10, or 15 meters.
4.4 Results
Pipeline localization. To conduct a comprehensive evaluation of IFRP-T2P, we compare our model with three state-of-the-art models [21, 39, 42] in two scenarios: one takes the ground-truth instance as input and the other uses the raw point cloud as input. In the context of raw point cloud scenario, we additionally compare our model with the 2D and 3D visual localization baselines, specifically NetVlad [2] and PointNetVlad [36] to demonstrate the efficiency of our multi-modal model. We report the NetVlad result available in Text2Pos. For PointNetVlad, we employ a downsampled one-third central region of the cell point cloud as the query to retrieve the top-𝑘 cells and adopt the center of the cell as the predicated position, similar as the NetVlad setting in Text2Pos. Table 1 illustrates the top-𝑘 (𝑘 = 1/5/10) recall rate of different error thresholds 𝜖 < 5/10/15𝑚 for comparison. Our IFRP-T2P achieves 0.23/0.53/0.64 at top-1/5/10 under the error bound 𝜖 < 5𝑚 on validation set. In the scenario where raw point cloud is adopted as input, our model outperforms the Text2Loc with prior instance segmentation model by 27%/23%/17% at top-1/5/10 under the error bound 𝜖 < 5𝑚. Comparing with the Text2Loc, our model shows comparable performance—lagging by merely 17%/8%/7% at top1/5/10 under the error bound 𝜖 < 5𝑚. Note that we report the result of our reproduced Text2Loc and the values available in the original publication of RET and Text2Pos. This trend is also observed in the test set, indicating our IFRP-T2P model effectively diminishes the dependency on ground-truth instances as input and effectively integrates relative position information in the coarse-to-fine localization process to improve the overall localization performance. Additionally, our model outperforms NetVlad and PointNetVlad
![Table 4: Ablation study of the row-column relative position-aware self-attention (RowColRPA) in coarse stage. “Naive” refers to the employment of standard self-attention mechanisms. “Value” denotes integrating pooled relative position features into the value, akin to the methodology described in RET [39]. “Row” signifies adding the query with row-wise pooled relative position features. “RowCol” stands for our proposed RowColRPA.](https://cdn.hackernoon.com/images/fWZa4tUiBGemnqQfBGgCPf9594N2-18033ld.png)
by 28%/82%/88% and 10%/20%/19% at top-1/5/10 under the error bound 𝜖 < 5𝑚. This result indicates our multi-modal model is more effective comparing to the 2D/3D mono-modal models.
Coarse text-cell retrieval. In align with current works, we evaluate coarse text-cell retrieval performance on the KITTI360Pose validation and test set. Table 2 presents the top-1/3/5 recall for each method. Our IFRP-T2P achieves the recall of 0.24/0.46/0.57, on the validation set. In the scenario where raw point cloud is adopted as input, our model outperforms the Text2Loc with prior instance segmentation model by 26%/24%/23% at top-1/3/5 recall rates. Comparing with the Text2Loc, our model shows comparable performance—lagging by merely 17%/10%/8% at top-1/3/5 recall rates on the validation set. This trend is also observed in the test set, indicating that our proposed instance query extractor could effectively generate instance queries with semantic information and the RowColRPA module could capture the crucial relative position information of potential instances. More qualitative results are given in Section 5.2.
Fine position estimation. To evaluate the fine stage model performance, we use the paired cells and text descriptions as input and compute the normalized Euclidean distance between the groundtruth position and the predicted position. We normalize the side length of the cell to 1. Table 3 shows that, under the instance-free scenario, our fine position estimation model yields 0.118 normalized Euclidean distance error, which is 2% and 9% lower comparing to Text2Loc and Text2Pos in validation set. This trend is also observed in the test set. This result indicates that our RPCA module effectively incorporates the spatial relation information in the text and point cloud feature fusion process, and thus improves the fine position estimation performance.
Authors:
(1) Lichao Wang, FNii, CUHKSZ (wanglichao1999@outlook.com);
(2) Zhihao Yuan, FNii and SSE, CUHKSZ (zhihaoyuan@link.cuhk.edu.cn);
(3) Jinke Ren, FNii and SSE, CUHKSZ (jinkeren@cuhk.edu.cn);
(4) Shuguang Cui, SSE and FNii, CUHKSZ (shuguangcui@cuhk.edu.cn);
(5) Zhen Li, a Corresponding Author from SSE and FNii, CUHKSZ (lizhen@cuhk.edu.cn).
This paper is
[story continues]
tags