The student paradox
When you learn jazz from a recording of John Coltrane, your instinct is to copy his exact phrasing, fingerings, and timing. But the best jazz students don't stop at imitation. They internalize the principles and eventually develop their own voice that sometimes surpasses the original. Yet when training AI models, researchers have been optimizing for something closer to perfect imitation. A student model learns by matching a teacher's decisions on its own generated tasks, which is better than simply copying a frozen teacher. But here's what has been left unexamined: the method treats two different goals as equally important, when they might not be.
This is the core tension that a new paper resolves. On-policy distillation (OPD) is popular because it works well empirically, consistently outperforming off-policy distillation and standard reinforcement learning approaches. But the technique has been treating it as a pure imitation problem. What if that assumption is costing performance?
Why standard distillation leaves something on the table
Standard on-policy distillation works by having the student generate its own rollouts, then rewarding it for matching the teacher's decisions. It's like learning from a coach who corrects you on the specific plays you attempt, not on hypothetical plays you might have tried. This is fundamentally better than learning from a frozen teacher.
But the mechanism treats two intertwined but distinct goals as equals: first, match the teacher's style; second, actually perform well on the task. The paper's key theoretical contribution reveals that OPD is actually a special case of dense KL-constrained reinforcement learning. In other words, distillation isn't primarily about copying. It's about solving an RL problem where you have competing goals and a penalty for diverging too far from a reference model.
This realization unlocks something. Standard OPD uses fixed weights, treating all goals as equally important. But you could adjust those weights. The method has a hidden parameter that practitioners haven't been tuning. Once you see that, distillation transforms from "here's the standard way to do it" into "here's a control problem with multiple degrees of freedom."
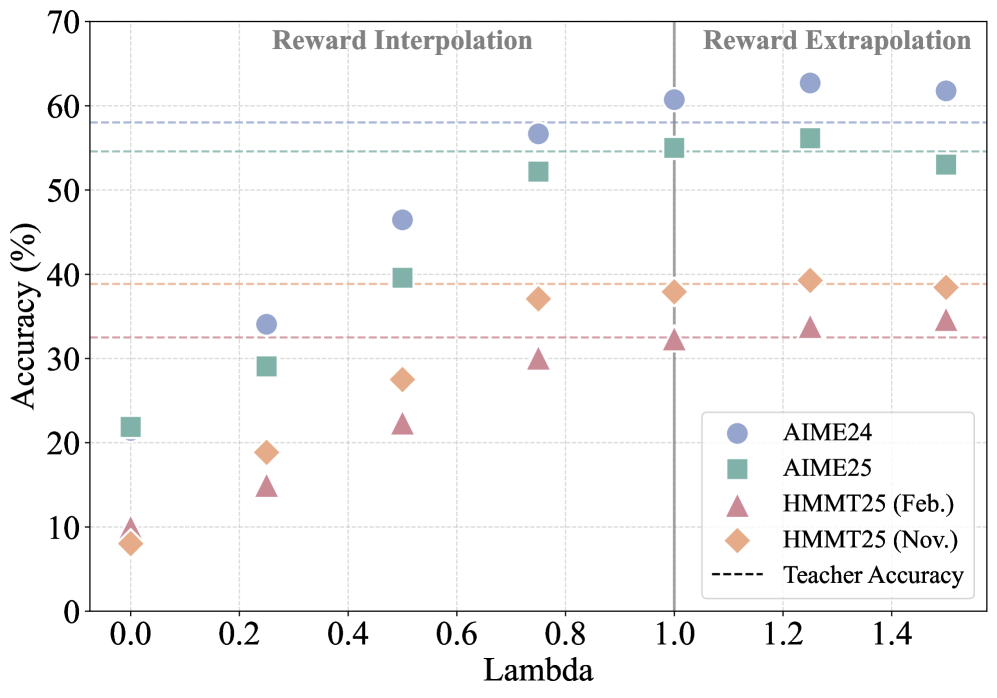
Turning the control knob
The experiments reveal what happens when you adjust that weight. Setting the performance reward's weight higher than the KL constraint, consistently beats the standard approach. The researchers call this Extrapolated On-Policy Distillation (ExOPD). The weight factor is your control knob, and turning it up past one says: "I respect the teacher's guidance, but I'm also going to push beyond it."
Results on four math reasoning benchmarks showing how performance changes as the reward scaling factor increases. Each curve represents a different benchmark, with performance consistently improving as the factor moves above 1
Figure 2: On-policy distillation results on four math reasoning benchmarks under different choices of reward scaling factor
The pattern holds across domains. Code generation shows the same trend.
Results on three code generation benchmarks demonstrating consistent performance gains from reward extrapolation across diverse coding tasks
Figure 3: On-policy distillation results on three code generation benchmarks under different choices of reward scaling factor
This consistency matters. The surprise isn't that the knob exists, it's that turning it up works reliably. The student learns to follow the teacher's direction while optimizing for actual task performance, and something unexpected emerges: the student sometimes surpasses the teacher.
When students beat teachers
Two concrete applications reveal where this idea produces outsized benefits. The first is multi-teacher fusion. Imagine having three specialized teachers, each an expert in different aspects of a task. You can fine-tune a single student model with each teacher separately via RL, then use ExOPD to merge all that knowledge back into one unified student. The result is a model that beats all three teachers individually.
This is difficult with existing methods. The student is synthesizing expertise from multiple sources in a way that produces something greater than any single teacher. It's not copying any one teacher more carefully, it's finding a path through the knowledge space that exists between them.
Comparison of ExOPD against off-policy distillation (SFT) and standard OPD in multi-teacher and strong-to-weak distillation settings
Figure (a): The empirical effectiveness of ExOPD compared with off-policy distillation (SFT), standard OPD, and the weight-extrapolation method
The second application is the strong-to-weak setting, where a smaller student learns from a larger teacher. Here there's an additional trick: use the teacher's pre-RL version as the reference model for KL correction. Why? The teacher model's RL training has already baked in certain preferences. If you use that as your reference, you penalize the student for moving away from those preferences rather than away from the true base model. It's a more accurate compass for understanding what divergence actually means.
Training dynamics showing how ExOPD and standard OPD converge over time in multi-teacher experiments
Figure (a): Training dynamics of OPD and ExOPD in multi-teacher distillation experiments with exponential moving average smoothing
These wins emerge naturally from the theoretical reframing. Once you see distillation as a control problem with adjustable weights, these applications become obvious rather than requiring special tricks. The work connects to broader research on post-training optimization methods and self-distillation approaches that similarly challenge how we think about aligning student models.
The practical cost
There's no free lunch. The reward correction trick requiring access to the teacher's pre-RL model incurs computational overhead. You're doing additional forward passes to maintain both the RL-trained and base versions. The performance gain comes at a cost, and practitioners need to weigh them.
This isn't a weakness of the research. It's intellectual honesty about real-world constraints. The work identifies which variant to use when: ExOPD with simple reward scaling for the multi-teacher case, or the more expensive reward correction approach for strong-to-weak distillation where the gains justify the compute.
The core insight remains simple. Distillation isn't about perfect mimicry. It's about finding the right balance between following the teacher and optimizing for performance. Turn up that balance knob, and suddenly students can synthesize knowledge from multiple teachers and exceed what any single one could teach alone.
This is a Plain English Papers summary of a research paper called Learning beyond Teacher: Generalized On-Policy Distillation with Reward Extrapolation. If you like these kinds of analysis, join AIModels.fyi or follow us on Twitter.