If you’ve ever worked on big data problems or AI, you will know that the amount of time required to solve the problem is proportional to the data size/cost of the hardware. To reduce the time, we either decrease data size (which is not possible) or increase compute—large companies can do so with millions of dollars shelled out every year, but smaller companies don’t have that luxury. At least not until they reach the threshold where cloud services make more sense for scaling (they could also rent hardware upfront to circumvent hourly costs).
This article will go over the infrastructure optimizations a company can use to efficiently reuse compute and maximize capacity. I’ll go over scheduler setup and various options for scheduling.
Need for Efficient Scheduling
As highlighted, the core challenge is reducing compute time and costs without sacrificing performance—especially for teams handling large datasets but working with limited budgets. To address this challenge, we need a scheduler that can take jobs as input, store job information, submit and track those jobs, update metadata, and provide a callback mechanism if needed. The diagram below shows a high-level view of a basic scheduler design that can handle 90% of the use cases most teams encounter. To make it more scalable, you can extend a few components (consider that your learning exercise).
Before diving into the design, we should first understand the requirements and the problem we are trying to solve. In most cases, for big data ML jobs, it’s about running large MapReduce jobs efficiently. We have defined resources—such as 100 large clusters or machines with 10 GB of memory—and we need to adjust our jobs accordingly. We can also extend this design to a scalable cloud instance provider. For example, if a user requests a certain virtual machine, we can provision one from our pool of machines and spin it up for the customer. This can serve as a starter project if you are new to cloud services and want to build one.
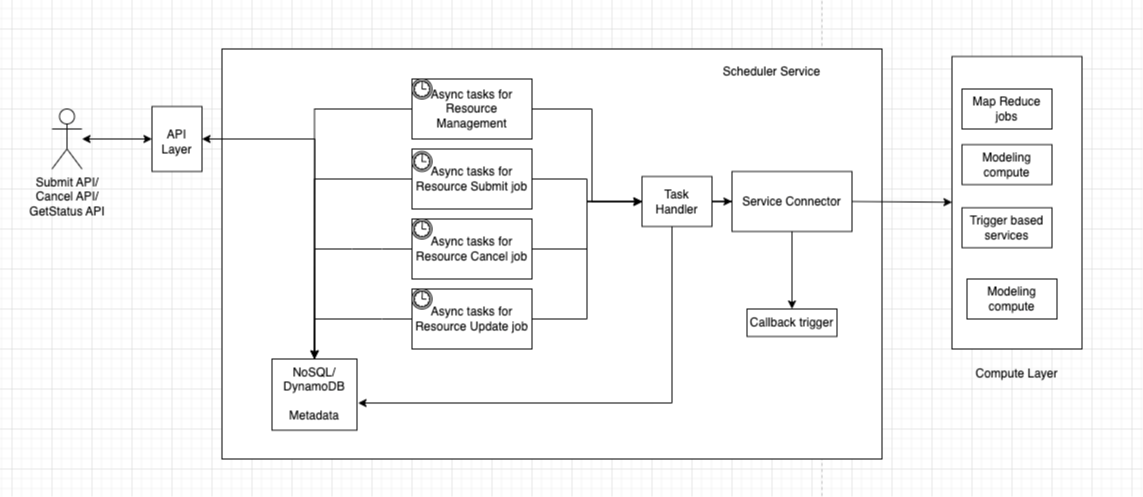
Internals of the design
Supported APIs
This design serves as a starting point, so feel free to extend it based on your specific needs. We want to support three APIs (you can use cloud APIs to host this and utilize serverless compute to process the requests). For AWS, these include API Gateway and AWS Batch services. We want to support submit, cancel, getStatus APIs so that we know where our job is, and you can add a callback if needed. We need callbacks in some cases because if we have thousands of jobs, we logically cannot poll a database thousands of times. But, if we have callbacks and SLA for a service, then we only need to poll on those that are delayed or failed, and then automatically get an update call when a job is failed/cancelled/complete. This way, we can avoid significant API calls.
Compute Layer
At the end of the day, this is where your big data job runs. To onboard a compute layer, it needs to define a few things—such as the amount of compute it can handle, user information (if possible), and authentication setup (which should be completed before onboarding). If available, gamma/beta/prod setups should also be in place. Additionally, there should be a way to know how many resources are running (and if this doesn’t exist, we can build a module to gather that information).
If we have all this support, we can easily manage our compute. Examples of compute layers in AWS include EMR (Elastic MapReduce), SWF (Simple Workflow Service), and SageMaker jobs.
Scheduler Service
The core component of our solution is this service. It requires a metadata store (DynamoDB/MongoDB) to store all relevant details, as well as a way to trigger asynchronous jobs (bonus points if we can make it onboardable during user onboarding), since each user wants polling at different intervals. We can use AWS EventBridge for this and register our jobs there.
We need four different types of jobs: one for retrieving available resources, another for checking job status, another for cancelling calls, and another for updating job status based on callbacks. The cadence of these jobs is debatable and should be adjusted according to user needs. There are race conditions in this design—leave a comment if you want to know more about them or if you’ve found one.
The task handler manages the logic and can be implemented using a serverless job to keep things simple. The service connector acts more like an adapter, linking different services to our scheduler service. This is why having a good interface is always important for problems of this nature.
Conclusion
We went through a somewhat scalable design that addresses the majority of scheduling use cases, providing services from a high-level perspective. This should help you get started if you’re looking to solve this problem. The solution also supports processing ML jobs at scale and has been proven to work for a large team at a FAANG company.
Leave a comment if something like this already exists that can integrate with various cloud providers. If there’s enough interest, I’ll share more details on building this service along with the code.
[story continues]
tags