
Problem
Let's consider such a case — you are developing functionality that processes thousands of records in any data storage and your weapon of choice is the AWS Step Function service.
One of the most powerful tools you can use there is Map task type since there you can maximize your function load and process chunks of data concurrently with maxConcurrency param.
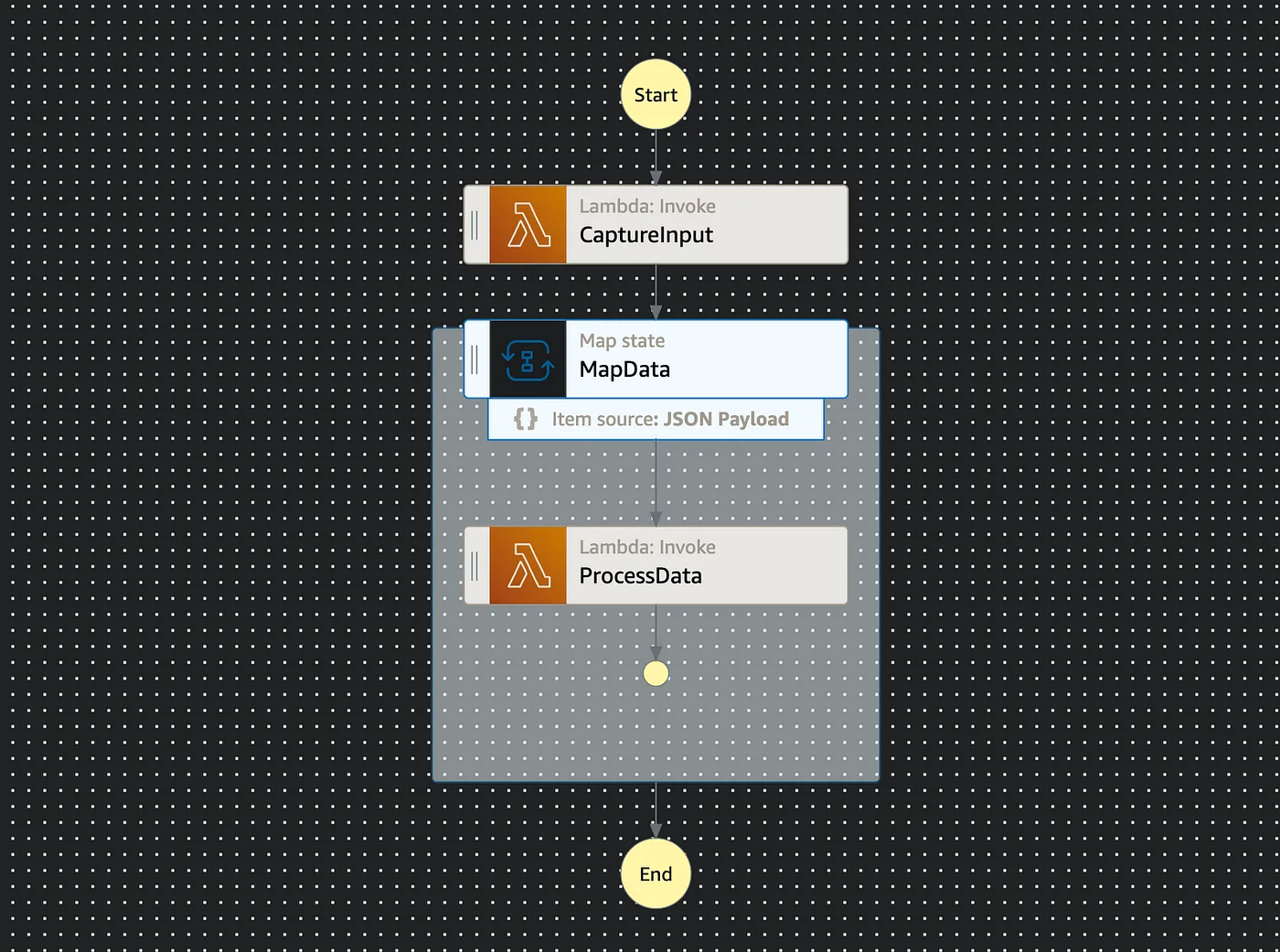
Let’s assume the logic of the steps:
-
CaptureInput — will accept some params from the user/service fetch data from storage and pass it to be processed
-
ProcessData — consume data process it and update/delete whatever logic requires
We also should keep in mind the main limitation of Inline Map for the step function
- Max payload size — 256 KB (whole payload, not just one array item)
- Max execution history — 25,000 events
- Accepts only a JSON array as input.
Code
An obvious part of the work that the CaptureInput Lamda should do is to fetch and pass some data into the Map state in the form from-to JSON Array:
// capture-input/handler.js
exports.handler = async ({number = 10, chunk = 1}) => {
return paginate(number, chunk)
}
function paginate(number, chunk){
const result = [];
const numPages = Math.ceil(number / chunk);
for (let i = 0; i < numPages; i++) {
result.push({
from: i * chunk,
to: Math.min((i + 1) * chunk, number),
});
}
// [{from: 1, to: 2}, {from: 2, to: 3}.....]
return result;
}j
For simplicity, imagine we are not passing raw ids but only a form — to cursor for a chunk of data. Lambda receives the following params:
- number — the number of processed data items
- chunk — count of the size that each map would process
The ProcessData Lambda would log it and somehow process the data:
// process-output/handler.js
exports.handler = (event) => {
console.log(JSON.stringify(event))
// ...do some processing
}
For deploying the step function serverless-step-function the plugin is used, the YAML file would look like this:
# serverless.yml
service: limit-payload-step-function
provider:
name: aws
runtime: nodejs18.x
stage: dev
region: us-east-1
accountId: 670913836060
architecture: arm64
package:
individually: true
plugins:
- serverless-step-functions
functions:
captureInput:
handler: capture-input/handler.handler
name: ${self:provider.stage}-${self:service}-captureInput
timeout: 900
memorySize: 1024
tags:
name: captureInput
processOutput:
handler: process-output/handler.handler
name: ${self:provider.stage}-${self:service}-processOutput
timeout: 900
memorySize: 128
tags:
name: processOutput
stepFunctions:
stateMachines:
ProcessDataStateMachine:
name: process-data-state-machine
definition:
StartAt: CaptureInput
States:
CaptureInput:
Type: Task
Resource: arn:aws:lambda:${self:provider.region}:${self:provider.accountId}:function:${self:provider.stage}-${self:service}-captureInput
Next: MapData
MapData:
MaxConcurrency: 5
Type: Map
InputPath: $
Iterator:
StartAt: ProcessData
States:
ProcessData:
Type: Task
Resource: arn:aws:lambda:${self:provider.region}:${self:provider.accountId}:function:${self:provider.stage}-${self:service}-processOutput
End: true
End: true
Then run to deploy:
serverless deploy --aws-profile=personal
Great! We have our function up and running and everything seems fine:
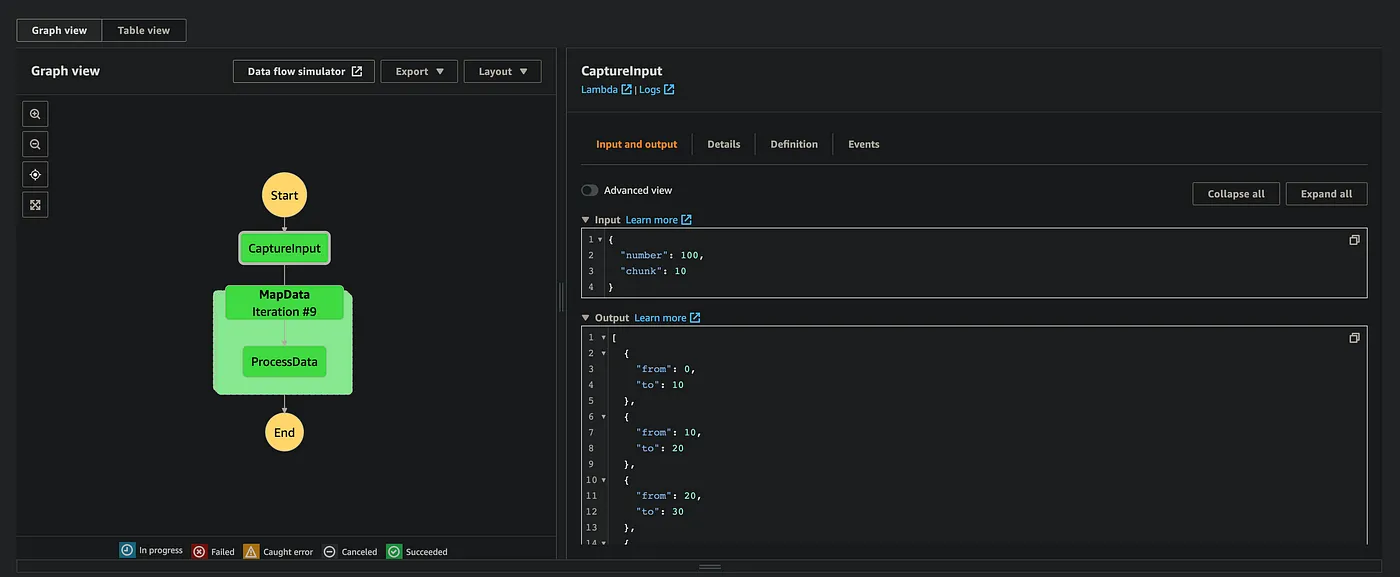
Until we try some bigger input to be passed to Map: Let’s try running it with:
{
"number": 10000,
"chunk": 5
}
And now we are in trouble:
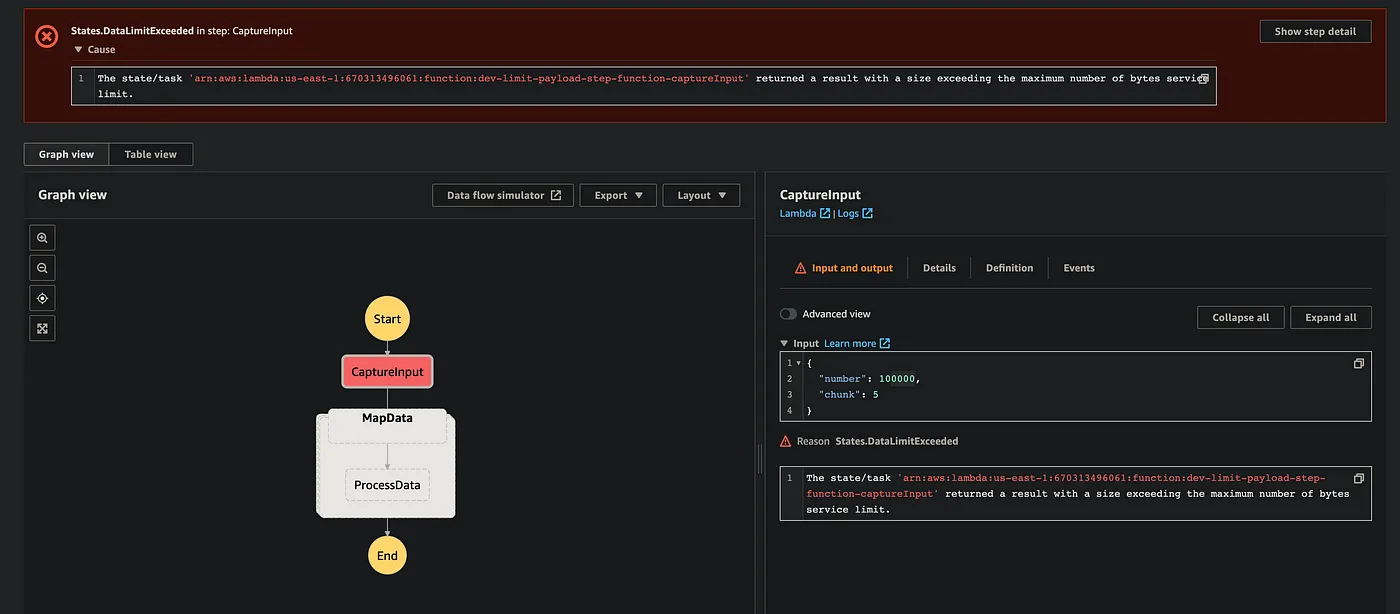
The state/task returned a result with a size* exceeding the maximum number of bytes service limit**.*
The output of CaptureInput is bigger than the step function can process (256 KB). Even if we try somehow to optimize params passing we still can hit 25k execution events when we would need to add other steps into the MapData task. And that is the time for Distributed Map to rescue us!
Inline VS Distributed
There is a neat illustration from AWS that outlines the work of the Inline Map we used before:
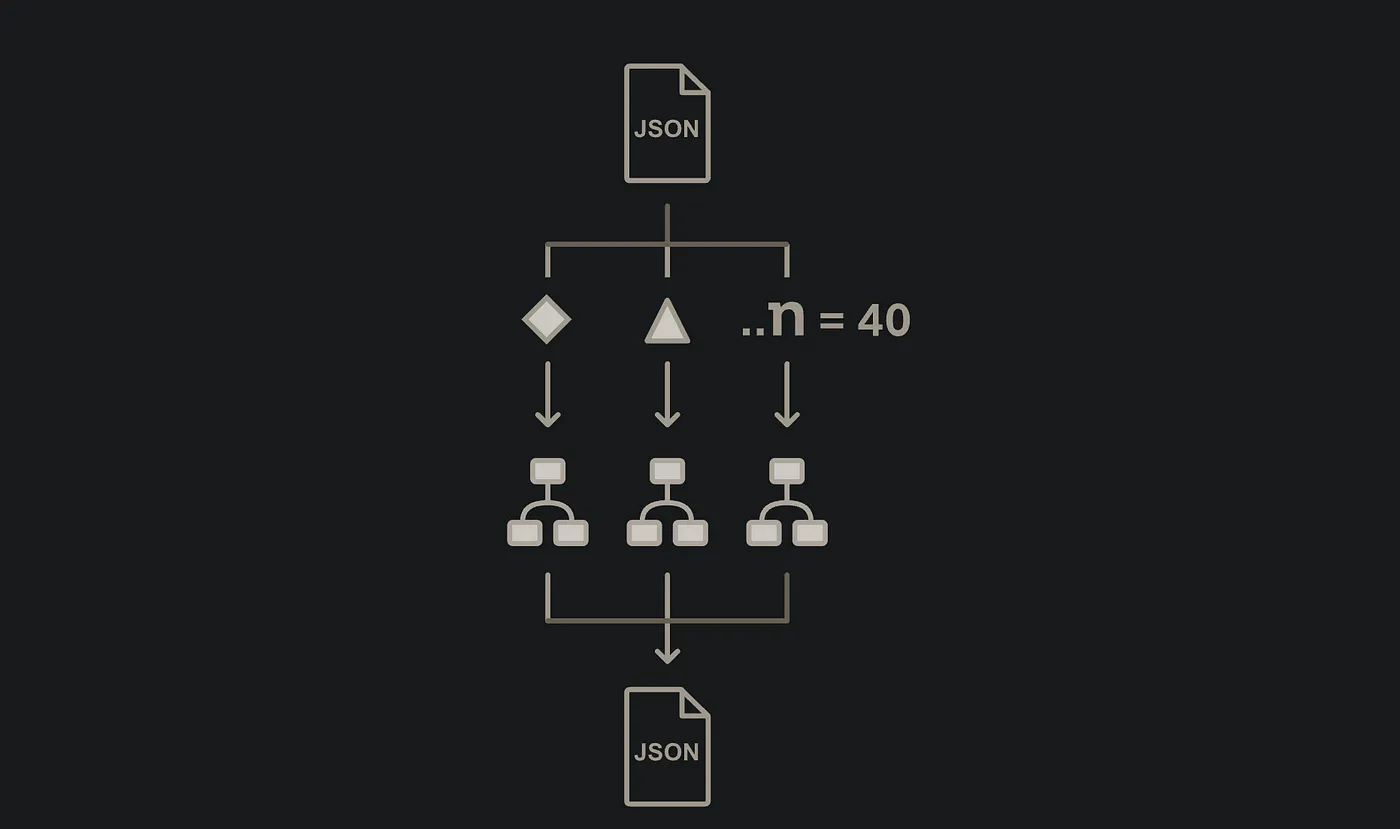
- Runs a set of steps for each element in a JSON array passed from the previous state.
- Step Functions adds the execution history of each Map iteration to the state machine’s execution history.
- Map iterations run in parallel, with limited concurrency after 40 iterations.
As we can see, we are pretty much limited using the default Map, and that's why the AWS team created a New Distributed Mode that would overcome the limits of the previous one.
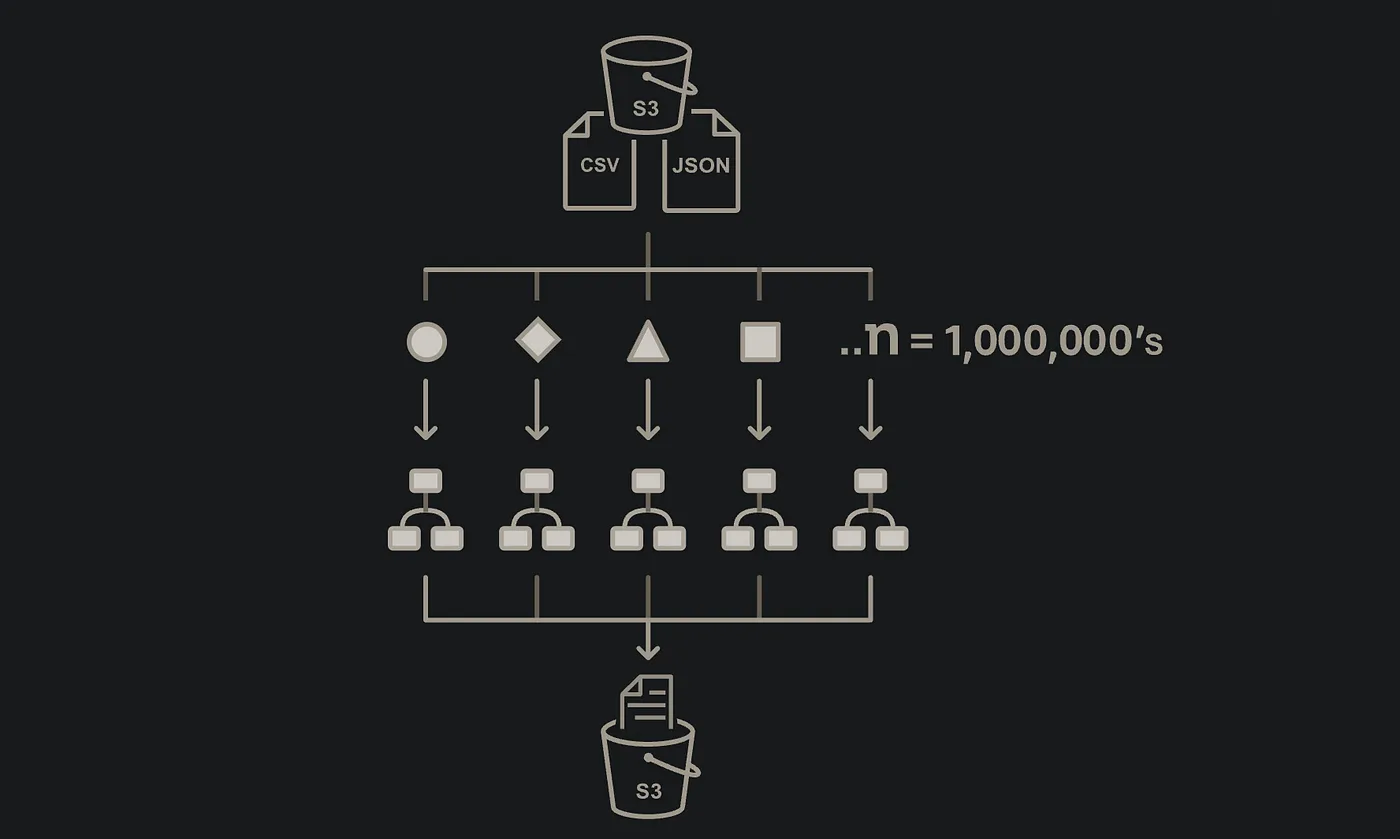
- Runs a set of steps for each item in a JSON array, S3 object list, or CSV file.
- Map iterations are fanned out as separate child executions with their own execution history, enabling very high concurrency.
- Iterates over and processes millions of items by running thousands of parallel child executions.
- Can cascade multiple Distributed Map states and batch items to create map-reduce type jobs.
- A Distributed Map state launches a Map Run resource, which you can access through the console, APIs, and SDK.
As you can see, basically every one of these items is going to make work with larger datasets easier and faster. By checking out Step Function Studio, you can see that there are 3 main types of Distributed Map:
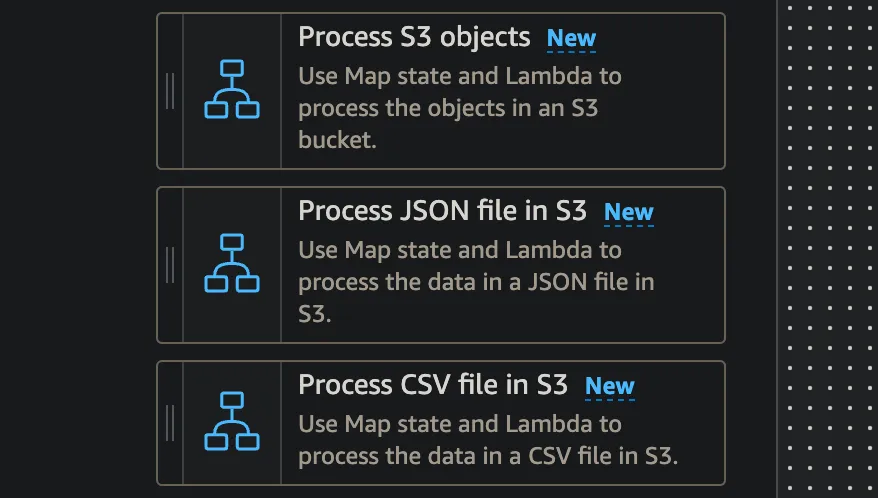
In this case, I guess the most suitable is the second option: Let Map iterate over JSON that is stored in S3. This is an example of how the step function can be realized using this approach:
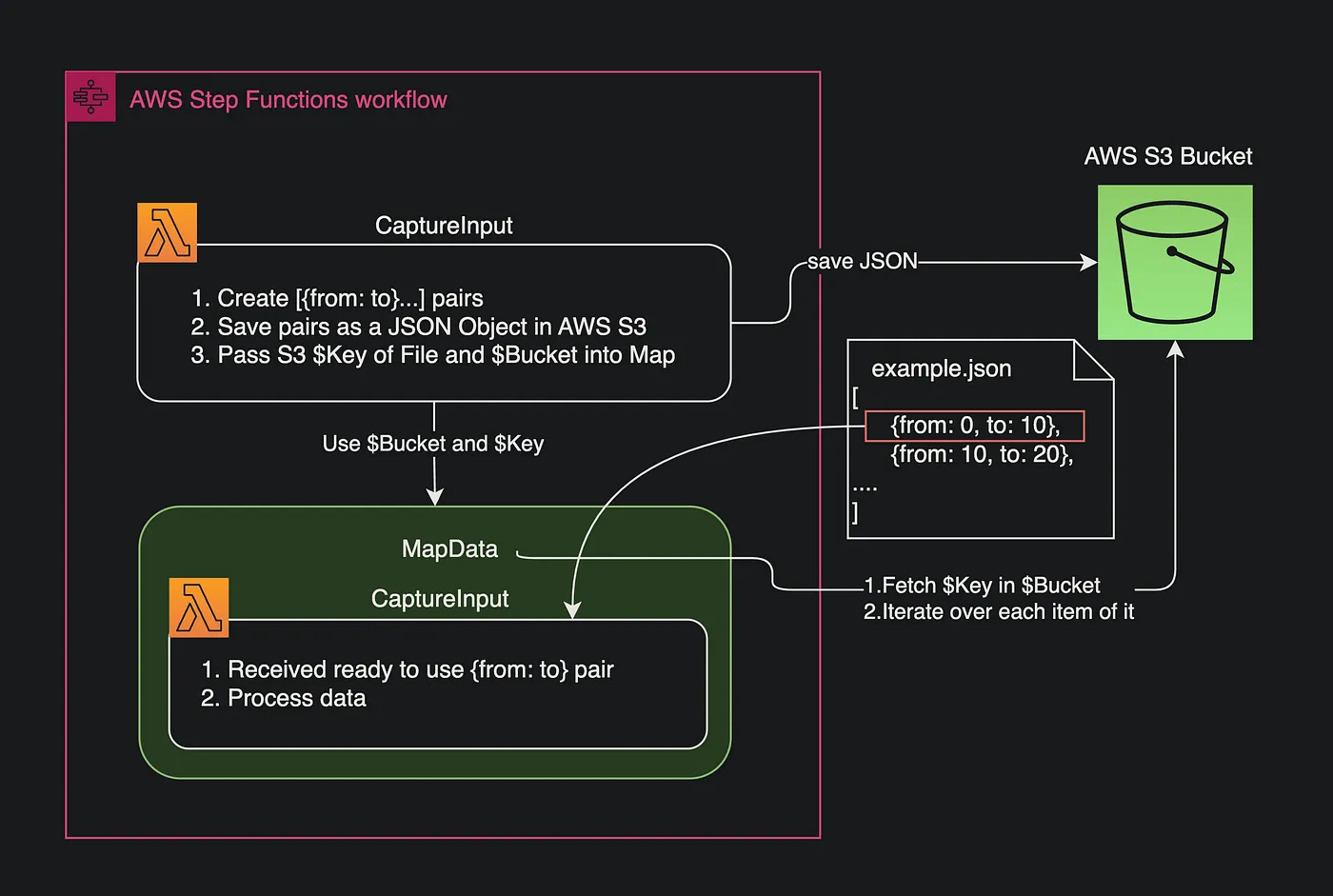
CaptureInputLambda receives params and generates from — to pais- Saves JSON with the pairs into Bucket
- Pass the Key (path) of JSON and Bucket name to Distributed Map
Mapwill automatically prefetch JSON and loop over each item in it, the item in the array is going to be passed directly into the Map body (CaptureInput)CaptureInputreceive the item of JSON array and process it like input for further data manipulations.
Coding the solution
Creating bucket
As was shown in the diagram above, we require AWS S3 Bucket to store items for Map. You can do it manually via the console or by adding Resource section in serverless.yml file:
resources:
Resources:
PayloadBucket:
Type: AWS::S3::Bucket
DeletionPolicy: Retain
Properties:
BucketName: step-function-payloads
Adding S3 permission
Then since CaptureInput function required S3 permission, I'm using serverless-iam-role-per-function plugin to do that, but you can also do it manually.
yarn add serverless-iam-roles-per-function
Add it to the plugins section:
provider:
# .....
environment:
BUCKET_NAME: step-function-payloads
iam:
role:
statements:
- Effect: 'Allow'
Action:
- 's3:*'
Resource:
- 'arn:aws:s3:::step-function-payloads/*'
- 'arn:aws:s3:::step-function-payloads'
# .....
plugins:
- serverless-step-functions
- serverless-iam-roles-per-function
# .....
custom:
serverless-iam-roles-per-function:
defaultInherit: true
This config will attach iam role with access to step-function-payload to each function as a default. Also, it will help create granular permissions in further development.
Saving Iterable JSON
Now we need to write our output JSON into S3 so that later Map state will iterate over it. It will be done in CaptureInput lambda:
// capture-input/handler.js
const AWS = require('aws-sdk')
const s3 = new AWS.S3();
const payloadFolder = 'temp-sf-payload'
const Bucket = process.env.BUCKET_NAME;
exports.handler = async ({number = 10, chunk = 1}) => {
const data = paginate(number, chunk)
const path = `${payloadFolder}/${Date.now()}.json`
const res = await s3.putObject({
Bucket,
Key: path,
Body: JSON.stringify(data)
}).promise()
console.log('Saved output: ', {Bucket, path})
return {bucket: Bucket, path}
}
function paginate(number, chunk){
const result = [];
const numPages = Math.ceil(number / chunk);
for (let i = 0; i < numPages; i++) {
result.push({
from: i * chunk,
to: Math.min((i + 1) * chunk, number),
});
}
return result;
}
We just save the from-to[] payload into an s3 file and pass bucket and path to the Map State. Now we need to consume it!
Distributed Map Definition
There are not many changes in a Step function definition:
# ...
MapData:
Type: Map
MaxConcurrency: 5
ItemReader:
Resource: arn:aws:states:::s3:getObject
ReaderConfig:
InputType: JSON
Parameters:
# Assign output of CaptureInput lambda for Map to iterate over
Bucket.$: $.bucket
Key.$: $.path
ItemProcessor:
ProcessorConfig:
Mode: DISTRIBUTED
ExecutionType: STANDARD
StartAt: ProcessData
States:
ProcessData:
Type: Task
Resource: arn:aws:lambda:${self:provider.region}:${self:provider.accountId}:function:${self:provider.stage}-${self:service}-processOutput
End: true
End: true
There are two new key components here:
ItemReaderused to specify the source of iteration and its type - either JSON CSV or S3 FolderItemProcessor— the same asIteratorin inline mode but with specifying nested workflow type
I’ve added all the references regarding the new Distributed mode including the blueprints repository in the last section of the article.
Step function Role
The last step is to add a custom role to the step function. New Map mode requires Map state to have getObject permissions to read from bucket we specified.
resources:
Resources:
ProcessDataStateMachineStepFunctionRole:
Type: "AWS::IAM::Role"
Properties:
RoleName: ${self:provider.stage}-ProcessDataStateMachine-StepFunctionRole
AssumeRolePolicyDocument:
Statement:
- Effect: Allow
Principal:
Service:
- states.amazonaws.com
Action:
- sts:AssumeRole
Policies:
# Allow invoking lambdas as a tasks in step function
- PolicyName: ${self:provider.stage}-${self:service}-lambda-invoke
PolicyDocument:
Version: '2012-10-17'
Statement:
- Effect: 'Allow'
Action:
- 'lambda:*'
Resource:
- 'arn:aws:lambda:*:*:function:${self:provider.stage}-*'
# Allow starting execution
- PolicyName: ${self:provider.stage}-${self:service}-start-execution
PolicyDocument:
Version: '2012-10-17'
Statement:
- Effect: 'Allow'
Action:
- 'states:StartExecution'
Resource:
- arn:aws:states:${self:provider.region}:${aws:accountId}:stateMachine:${self:stepFunctions.stateMachines.ProcessDataStateMachine.name}
# Allow logging
- PolicyName: ${self:provider.stage}-${self:service}-default-logging
PolicyDocument:
Version: '2012-10-17'
Statement:
- Effect: 'Allow'
Action:
- 'logs:CreateLogGroup'
- 'logs:CreateLogStream'
- 'logs:PutLogEvents'
Resource:
- 'arn:aws:logs:*:*:log-group:/aws/lambda/*'
- Effect: 'Allow'
Action:
- 'xray:PutTraceSegments'
- 'xray:PutTelemetryRecords'
Resource:
- '*'
# Full access to S3 bucket
- PolicyName: ${self:provider.stage}-${self:service}-read-s3-bucket
PolicyDocument:
Version: '2012-10-17'
Statement:
- Effect: 'Allow'
Action:
- 's3:*'
Resource:
- arn:aws:s3:::step-function-payloads/*
Demo
Started function with these params:
{
"number": 100000,
"chunk": 5
}
Map successfully started!
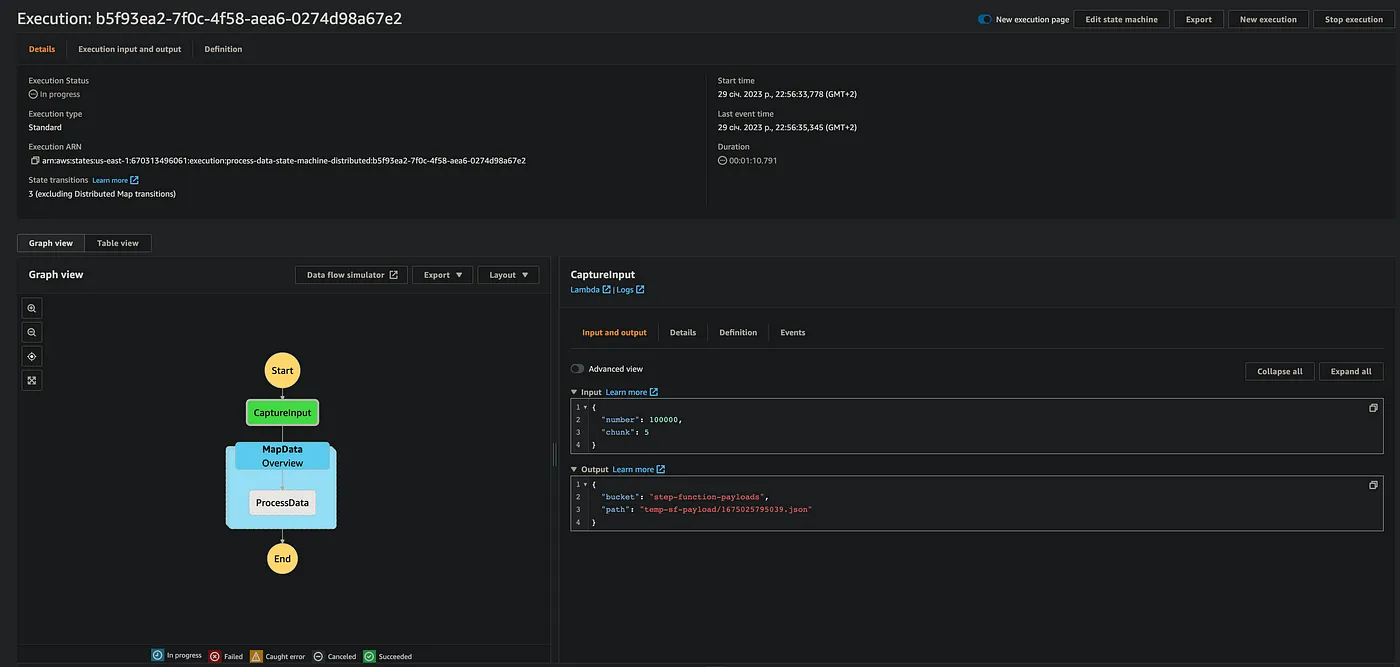 Now we can monitor the progress in a separate menu:
Now we can monitor the progress in a separate menu:
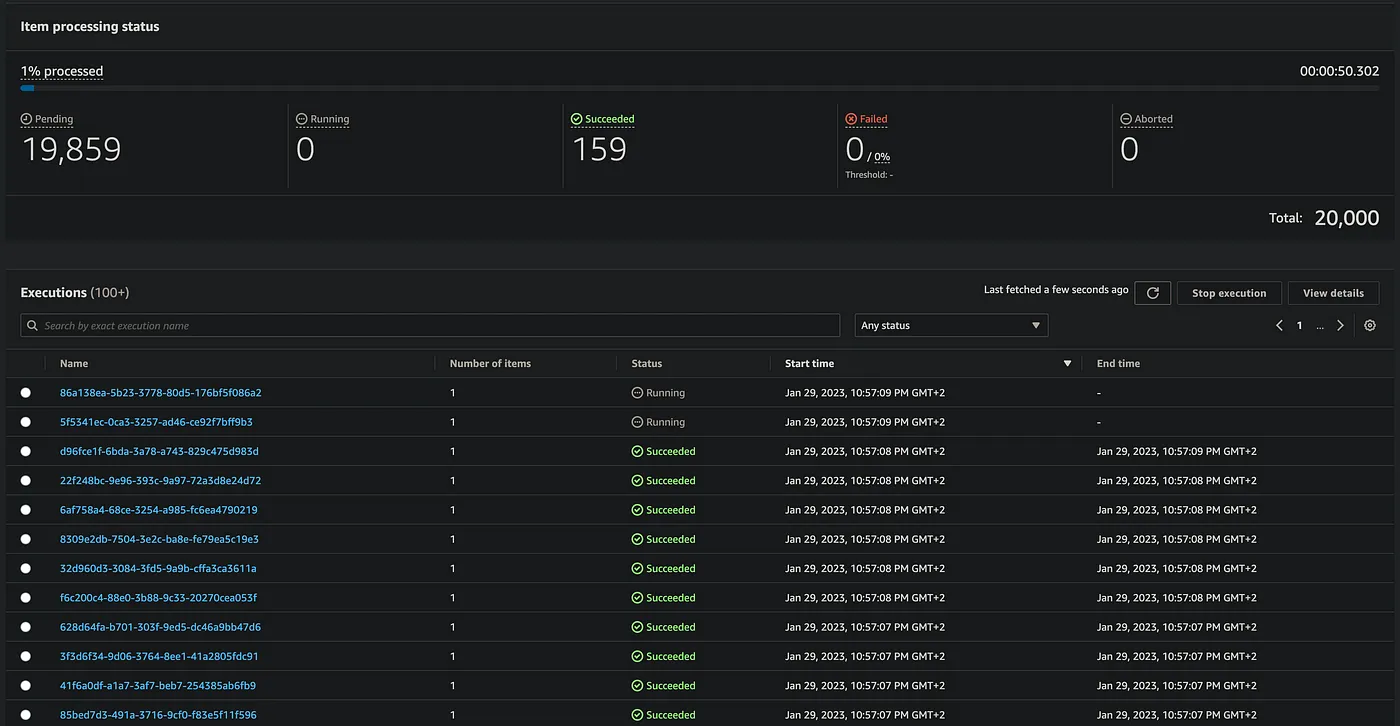 This Map is processing 20k steps in a snap of a finger, and it’s not the last feature of Distributed mode. We also can increase
This Map is processing 20k steps in a snap of a finger, and it’s not the last feature of Distributed mode. We also can increase MaxConcurrency and use ItemBatcher parameters to make it even faster!
Summary
Now you know how to overcome the limitations of the Inline Map of your step function workflow with Distributed Map task state. Check out the blueprint in the section below!
Thanks for reading!
Resources
- Repository: Step Function Distributed Map Example
- DOC: Map state processing modes
- DOC: Using Map state in Distributed mode
- DOC: ItemBatcher
[story continues]
tags