
Table of Links
-
Related Works
-
Methodology
4.1 Formulation of the DRL Problem
4.2 Instance-Aware Deep Reinforcement Learning for Efficient Index Selection
-
Experiments
6.2 Experimental Results
Training Efficiency of TD3-TD-SWAR:. In Figure 5 (a), the TD3-TD-SWAR algorithm showcases superior training efficiency against other RL algorithms like DQN, PPO, and vanilla TD3, particularly with the complex workload W6 under an 8-unit storage budget. Remarkably, IA2 completes 100 episodes in just 50 seconds, significantly faster than SWIRL, which can take several to tens of minutes under similar conditions. This efficiency is attributed to the effective what-if cost model, ensuring cost-efficient scaling for diverse data and workloads. IA2’s capacity for rapid training is further enhanced by its support for pre-trained models, offering adaptability without extensive retraining.
Efficiency of Action Pruning Approaches: Figure 5 (b) showcases IA2’s action masking efficiency when exhausting the storage budget, comparing it with SWIRL’s dynamic masking and Lan et al.’s static heuristic rules using workload W6. With an 8-unit budget and 1701 possible actions, IA2 significantly reduces the action space, especially in the early stages of training. This adaptive strategy emphasizes IA2’s ability to navigate and prune the action space more effectively, ensuring a streamlined and focused exploration of indexing strategies.
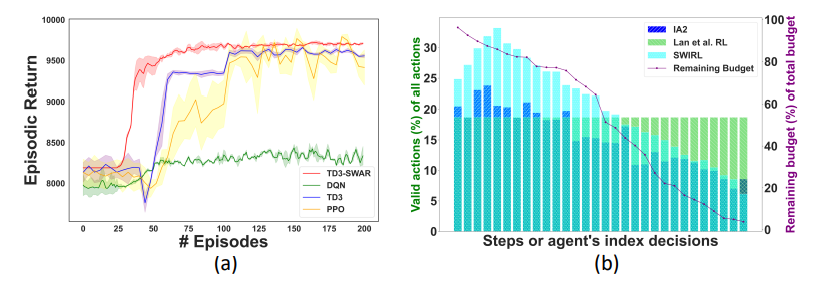
Our analysis reveals key differences in index selection strategies: Lan et al.[7] adopts a fixed-rule approach for index combinations, ensuring high training efficiency but potentially overlooking valuable index candidates. SWIRL[6] utilizes a combination of exhaustive generation and dynamic masking to explore a wider array of actions, though its effectiveness can vary with workload specifics, impacting training efficiency. As shown in Table 1, IA2 merges the benefits of both approaches, employing flexible and automatic selection of meaningful actions for training alongside specific rules for generating candidates, enhancing the efficiency and adaptability of index selection.
Authors:
(1) Taiyi Wang, University of Cambridge, Cambridge, United Kingdom (Taiyi.Wang@cl.cam.ac.uk);
(2) Eiko Yoneki, University of Cambridge, Cambridge, United Kingdom (eiko.yoneki@cl.cam.ac.uk).
This paper is
[story continues]
tags