
AI-powered code review tools are often marketed as near-senior-engineer replacements. Point them at your repository, wait a few minutes, and—voilà—they’ll deliver architectural wisdom, best practices, and a brutally honest critique of your codebase.
At least—that’s the promise.
Recently, I put OpenAI Codex’s web-based code review to the test on a real-world legacy .NET C# application. The results? Underwhelming in ways that matter most for large systems.
In this article, I’ll walk you through how the review was conducted, what Codex did reasonably well, and—most importantly—where it fundamentally failed, especially when it came to architecture.
How the Code Review Was Conducted
The setup was simple but intentional. I used a legacy .NET C# solution hosted in a GitHub repository and pointed the web-based OpenAI Codex interface directly at it. No IDE, no plugins—just Codex analyzing the raw codebase.
This project has been reviewed by other AI coding assistants, such as GitHub Copilot, so it’s a familiar benchmark. My goal wasn’t to test syntax knowledge or C# trivia—it was to see whether Codex could evaluate a real, imperfect system the way an experienced engineer would.
Why “One-Line” AI Code Reviews Fall Short
For my first attempt, I kept things simple: a single-line prompt asking Codex to review the entire codebase. The result? It flagged issues like unused variables, redundant methods, and static classes while suggesting minor improvements to data access logic. The process took under four minutes.
But here’s the problem: large systems don’t fail because of individual classes. They fail because of how responsibilities are distributed, how dependencies flow, and what the system is fundamentally coupled to. Codex didn’t address any of these systemic concerns. Instead, it focused narrowly on isolated issues within specific files.
This outcome wasn’t surprising. Without explicit guidance, AI struggles to move beyond surface-level observations.
Adding Structure: A Detailed Benchmark and Scorecard
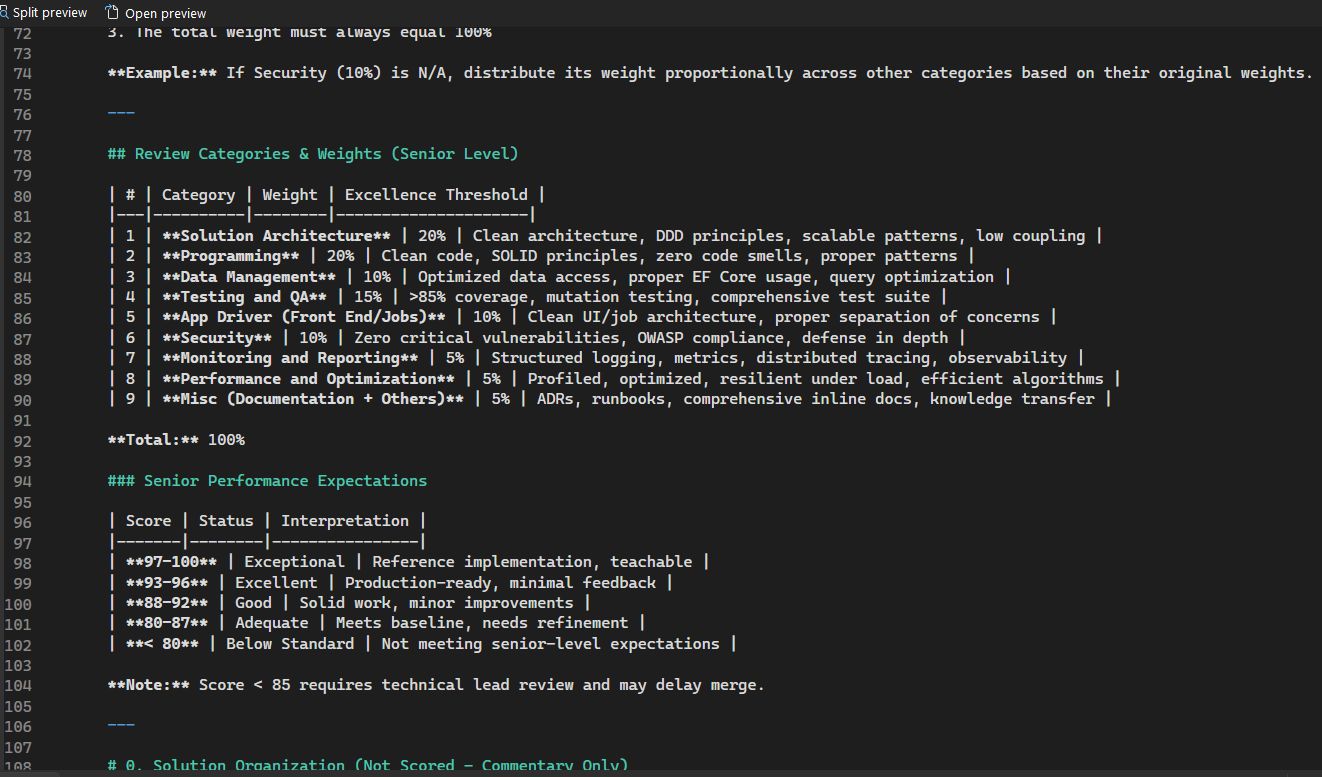
To give Codex a fair shot, I refined my approach. For the second review, I provided a strict coding standard and a custom scorecard with weighted categories like Solution Architecture, Testing Strategy, Programming Practices, and Maintainability. I also defined clear expectations for what constituted “good” in each category.
With these guidelines, Codex had everything it needed to produce a meaningful evaluation. The review took about five minutes—and on paper, this should have yielded far better results.
The Executive Summary Problem
The first red flag appeared immediately: the executive summary. It was generic, vague, and overly positive, reading more like a reflection of the README than an analysis of the actual code. There was no mention of architectural coupling, structural anti-patterns, or core design flaws.
At this point, it already felt like the AI had optimized for surface-level understanding rather than deep inspection.
The Scorecard That Gave the Game Away
The final verdict? Fifty out of one hundred. While this score might seem harsh, it was actually too generous. Let’s break it down.
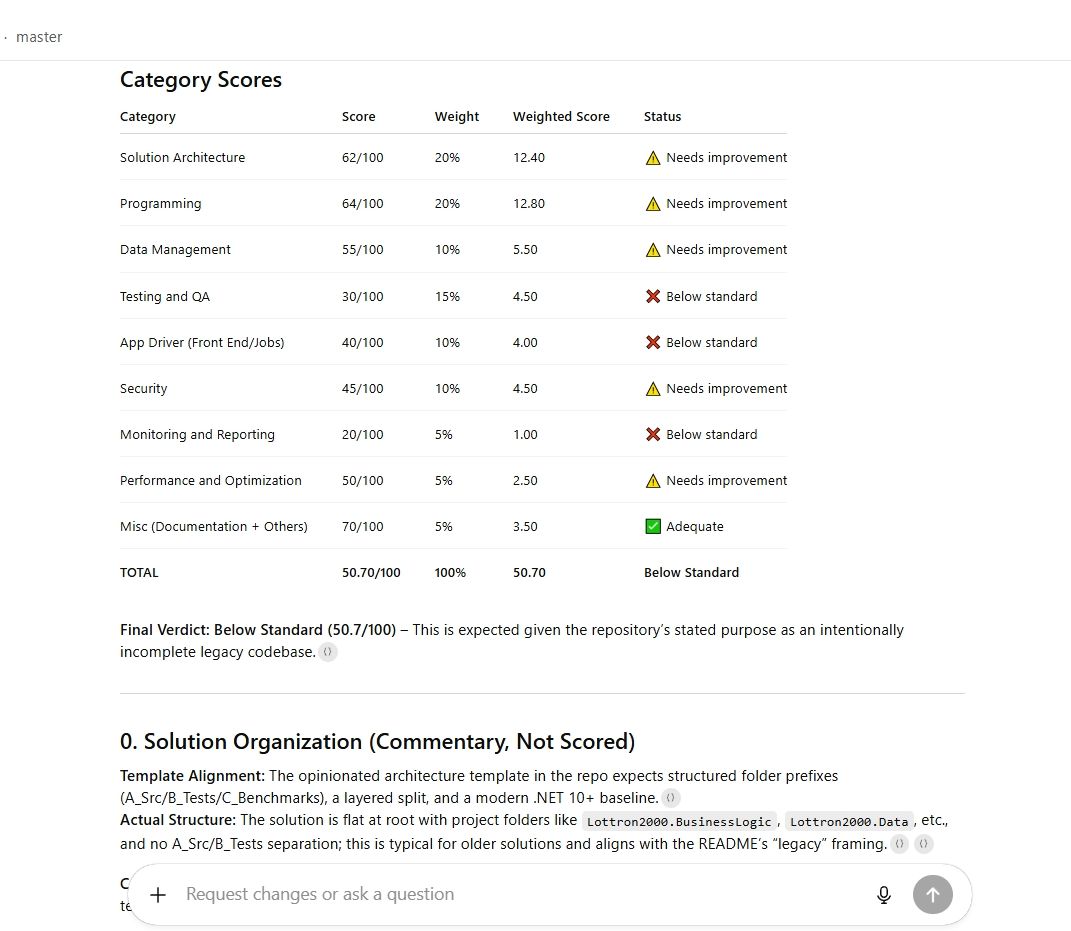
Solution Architecture: 62 / 100
This score is objectively wrong. The application does not have a modern architecture. Yes, it has multiple projects, and yes, it looks “layered” at first glance—but dig deeper, and you’ll find the database is at the core of the system. The domain and logic layers are directly coupled to Entity Framework, making the application architecturally dependent on its data access layer.
This is a classic anti-pattern in modern software design. A healthy architecture isolates the domain; this system does the opposite. A realistic score here would be closer to ten, not sixty-two.
Testing: Severely Overrated
The solution contains tests—but only end-to-end tests. There are no meaningful unit tests, no isolated domain tests, and no adherence to the testing pyramid. Yet the score implied reasonable test coverage and discipline. In reality, testing should have scored near failure level.
Programming Practices: Also Too Generous
Large portions of the domain logic are implemented using static classes. This breaks testability, encourages tight coupling, and makes dependency management impossible. From a modern C# perspective, this is poor practice—and yet, the score suggested adequacy rather than failure.
The Core Problem: AI Still Thinks Locally
This review highlights a recurring limitation across most AI coding models today: they reason at the class and method level, not at the system level. Codex can spot syntax issues, comment on patterns in individual files, and suggest refactors in isolation. What it cannot reliably do (yet) is trace architectural coupling across modules, identify systemic design anti-patterns, or penalize solutions that *look* structured but are fundamentally flawed.
This is especially problematic for legacy systems, where the same flawed philosophy is often replicated across multiple modules.
Why This Is Disappointing
What makes this result surprising isn’t just the outcome—it’s the setup. Codex was given a detailed benchmark, a weighted scorecard, and explicit architectural expectations. And still, the review fell short. The AI failed to apply its own criteria with the seriousness a human reviewer would.
Final Verdict
AI code review is not useless—but it is not sophisticated enough for evaluating large, real-world architectures. At this stage:
- Use AI for code-level feedback.
- Do not trust it for architectural assessment.
- Always validate scores and conclusions manually.
If you’re looking for stronger performance on complex development tasks, consider experimenting with alternative models—particularly those from Anthropic, which currently appear to reason more effectively at higher levels of abstraction.
AI is improving fast. But architecture still belongs to humans—for now.
Watch the Full Discussion
I dive deeper into this topic with coding example and demonstrations. If you want to see the process of completing this experiment, check out the full demo video:
https://youtu.be/qBh5EJH1G2c?embedable=true
[story continues]
tags