
This is a Plain English Papers summary of a research paper called LTX-2: Efficient Joint Audio-Visual Foundation Model. If you like these kinds of analysis, join AIModels.fyi or follow us on Twitter.
The silent film problem
Text-to-video generation has become remarkably sophisticated. Modern models can render complex scenes with consistent character movements, realistic lighting, and intricate visual details across dozens of frames. Yet when you press play, you encounter silence. A tense confrontation lacks a music cue. A forest scene has no rustling leaves or ambient birdsong. A character speaks with no voice.
The problem isn't technical oversight, it's fundamental. Generating audio and video in synchronized partnership is exponentially harder than either task alone. Video demands massive computational resources to render high-resolution visual information. Audio demands semantic precision where a single misaligned phoneme or sound effect breaks immersion. Most text-to-video systems treat audio as an afterthought, either stripping it out entirely or adding it post-hoc with separate models that lack the context to create genuine coherence.
This leaves a gap between what's technically possible and what actually works. A scene feels incomplete when its emotional and atmospheric dimensions are missing. The viewer's brain knows something is wrong even if they can't articulate why. Sound is half of what makes cinema feel real.
Why unified generation requires thinking differently about architecture
The naive approach to audiovisual generation would be straightforward, build one massive model that generates audio and video with equal capacity. The problem is that audio and video aren't equal problems.
Video is bandwidth-intensive but somewhat forgiving of imperfection. A slightly blurry or temporally inconsistent frame is visually acceptable. It requires enormous computational resources because the output space is enormous, pixels filling high-resolution frames across time. Audio is the opposite. It's lower bandwidth but semantically brittle. A single wrong tone, a misaligned sound effect, or poorly timed dialogue ruins the whole experience. You can't hear a phoneme and then adjust, the moment is already ruined.
This asymmetry means equal computational allocation is wasteful. Pour 14 billion parameters into audio generation and you're solving problems that don't need solving, creating overly complex models that learn spurious relationships. Starve audio of compute and the model can't create coherent soundscapes. Neither approach works.
But there's a deeper issue. Audio and video must stay semantically locked together. When a character's mouth opens, dialogue must begin in that exact frame. When a door creaks in the audio track, the video must show the door moving. If you generate them independently and then try to patch them together afterward, synchronization becomes a post-processing problem with no good solution.
The insight that drives LTX-2 is that this isn't a limitation to work around, it's the design principle that makes unified generation tractable. Allocate resources asymmetrically while building bidirectional attention mechanisms that keep the streams semantically synchronized. Give video the capacity it needs, give audio the capacity it needs, and force them to constantly check in with each other during generation.
The asymmetric dual-stream architecture
The foundation of LTX-2 is elegantly straightforward in principle. Two parallel transformer streams process video and audio simultaneously, but one is significantly larger than the other. The video stream contains 14 billion parameters while the audio stream contains 5 billion. This 2.7 to 1 ratio isn't arbitrary, it reflects the computational demands of each modality.
But size alone wouldn't solve the synchronization problem. The architecture's real innovation is how the streams communicate.
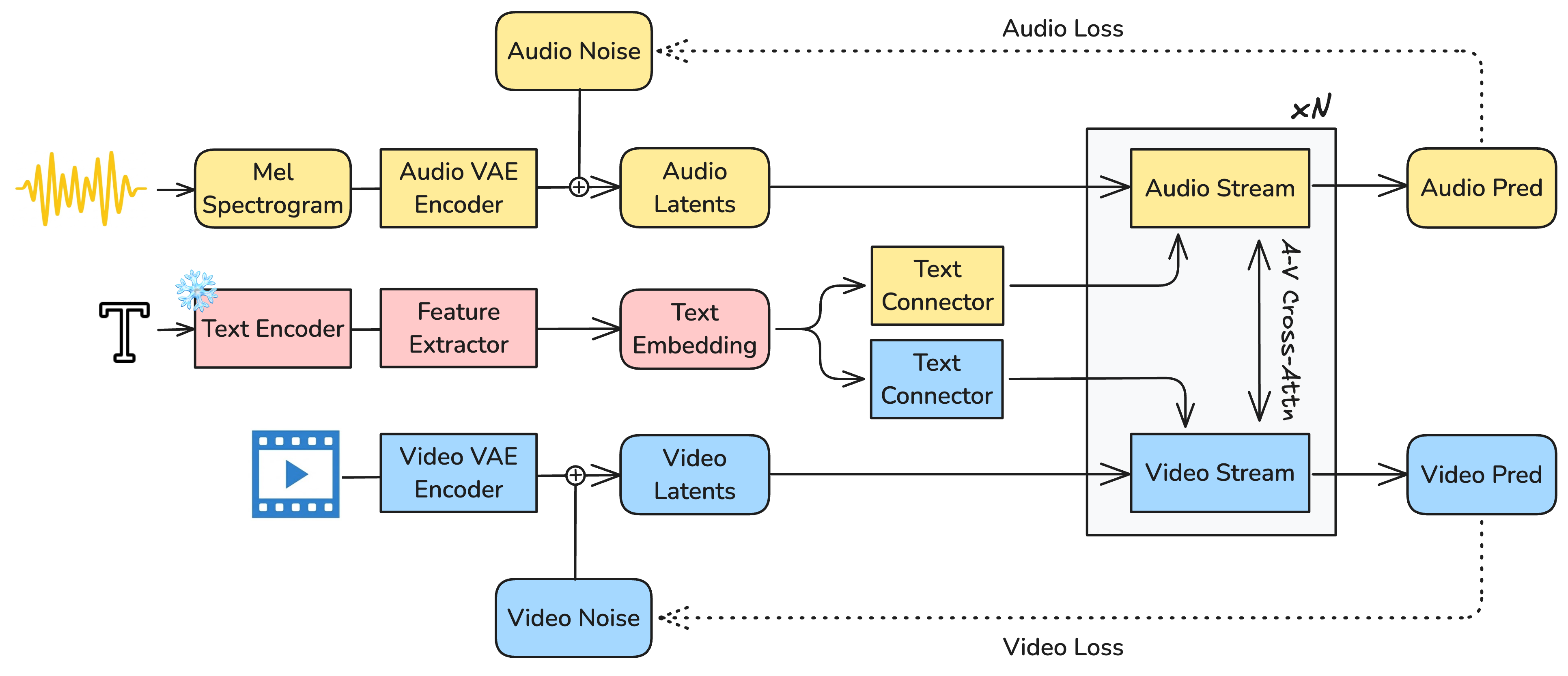
Overview of the LTX-2 architecture showing dual-stream processing with bidirectional cross-attention. Raw video and audio are encoded via causal VAEs while text flows through a feature extraction pipeline. The streams remain synchronized through cross-attention layers and shared timestep conditioning.
Between the video and audio streams run bidirectional cross-attention layers. These aren't bottlenecks where information squeezes through, they're dedicated communication channels. During generation, the video stream produces intermediate representations and attends to what the audio stream has generated at corresponding timepoints. Simultaneously, the audio stream pays attention to the video stream's progress. This happens repeatedly across the entire generation process, not just at the end. The streams are in constant dialogue with each other.
Both streams are internally identical in architecture, just different sizes. Each uses the transformer structure detailed in Figure A2, applied to their respective modalities.
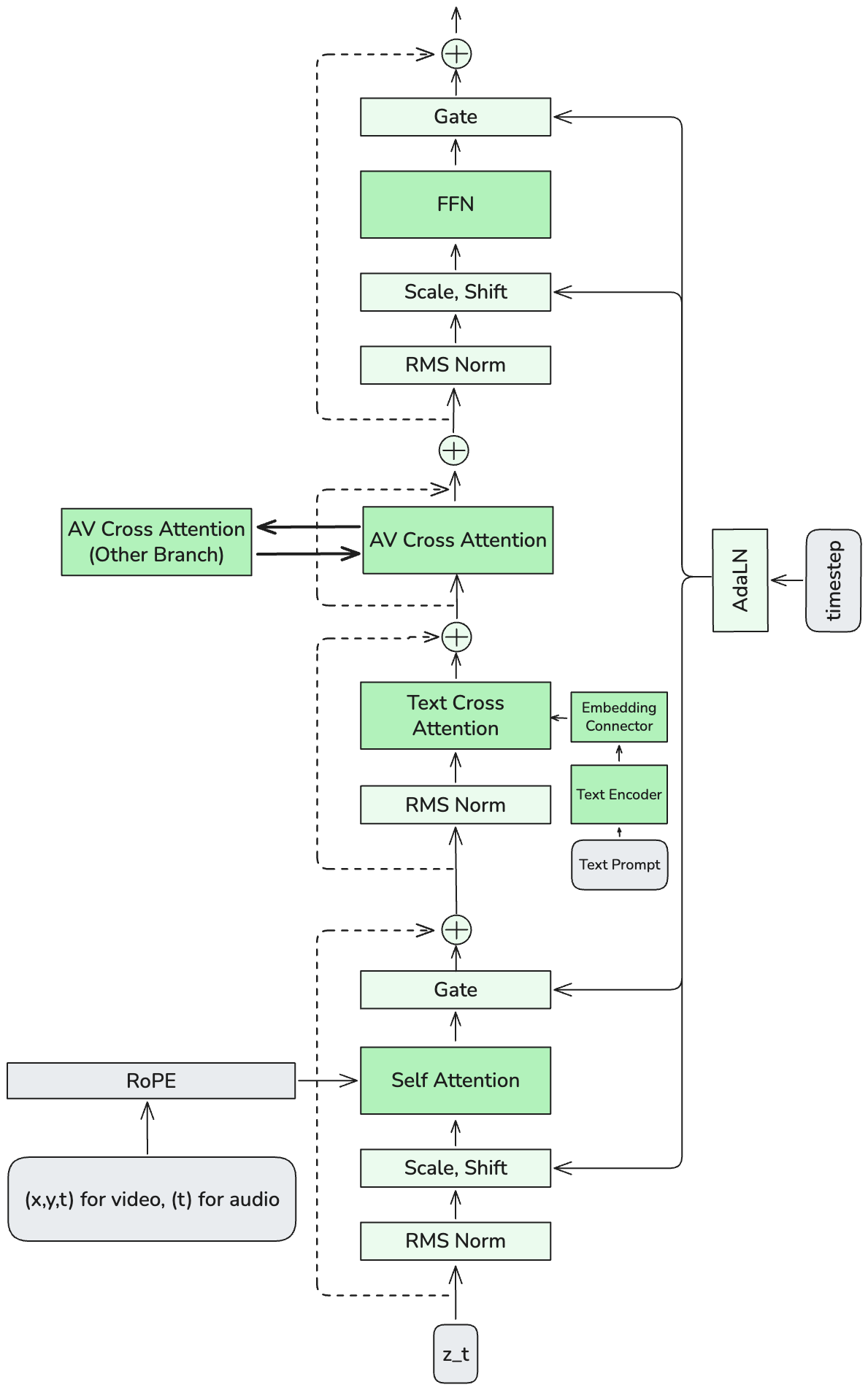
Detailed view of a single stream architecture. Both audio and video streams use identical internal structure, with the difference being parameter count.
The synchronization mechanisms include temporal positional embeddings that encode where each step sits in the sequence. When generating a 10-second clip, the model needs to know whether it's at the 2-second mark or the 8-second mark so it can coordinate the mouth movements in video with dialogue timing in audio. These embeddings give both streams a shared sense of temporal position.
Cross-modality Adaptive Layer Normalization ensures both streams receive the same timestep conditioning simultaneously. Think of this as a metronome both musicians listen to during performance. When the diffusion process takes a denoising step, both streams adjust together, maintaining lock-step progression. This shared conditioning is what prevents drift over long generation sequences.
The asymmetry feels counterintuitive until you realize its elegance. You're not forcing two different problems into one equally-sized box. You're building two boxes sized to the actual problems, then designing robust communication channels between them. The result is a system that stays synchronized while remaining computationally efficient.
Training for synchronization
The architecture enables synchronization, but training is what teaches the model to actually achieve it. The process teaches two very different tasks to develop together.
LTX-2 processes text through a multilingual text encoder, Gemma3, that understands prompts across languages. Raw text embeddings alone don't work though. The text must be refined through a feature extraction process and a text connector that prepares it to work with modality-specific components.
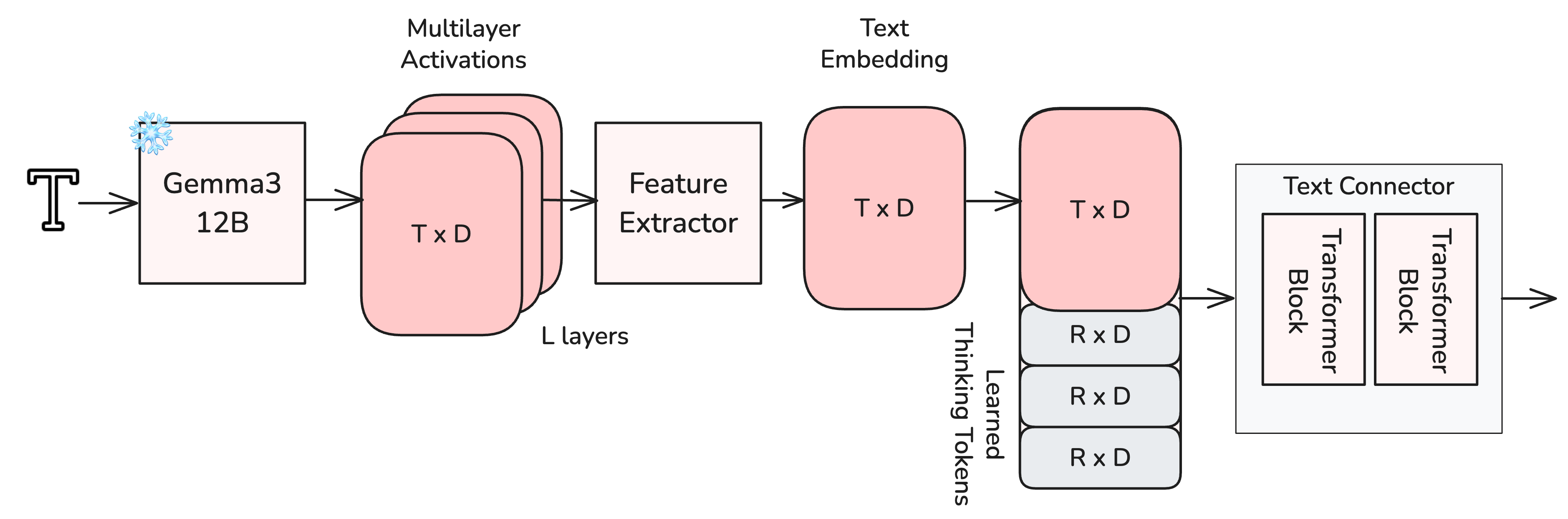
Text understanding pipeline showing how raw prompts are encoded and refined for modality-specific conditioning. Features are extracted and connected to guide both audio and video generation appropriately.
This pipeline is crucial because the same text needs to guide two generators with very different information requirements. When a prompt says "dark and mysterious," it means different things for video (low lighting, shadows, muted colors) and audio (minor key, sparse instrumentation, unsettling tones). The feature extractor learns which aspects of the text matter for each modality, and the text connector translates this into modality-specific conditioning signals that each stream can use effectively.
During training, both streams are denoising noisy audio-video pairs at the same timestep in parallel. If they took different paths or received different conditioning signals, they would naturally drift apart over a generation sequence. By sharing timestep information through AdaLN and forcing them to attend to each other at multiple points, the training process creates a constraint that teaches synchronization by necessity. The model learns that staying aligned isn't optional, it's how the loss decreases.
Before the streams process anything, raw signals get compressed. Audio and video are encoded into latent representations using causal variational autoencoders. "Causal" means the encoding respects temporal ordering, earlier frames don't depend on future information. This is crucial for stable training because it prevents information leakage across time. Both streams then work in compressed latent space rather than raw pixels and waveforms, which reduces computational demands and makes patterns easier to learn.
Controlling generation with modality-aware guidance
At generation time, users want control. "Make the dialogue more prominent." "Increase the ambient music." "Make the audio feel more tied to visual action." But naive guidance mechanisms fail in multimodal settings.
If you try to guide audio and video together with a single control signal, they often fight each other. Push toward text adherence and audio might become overly literal while video stays natural, or vice versa. The solution is modality-aware classifier-free guidance, which treats guidance as having multiple independent components.
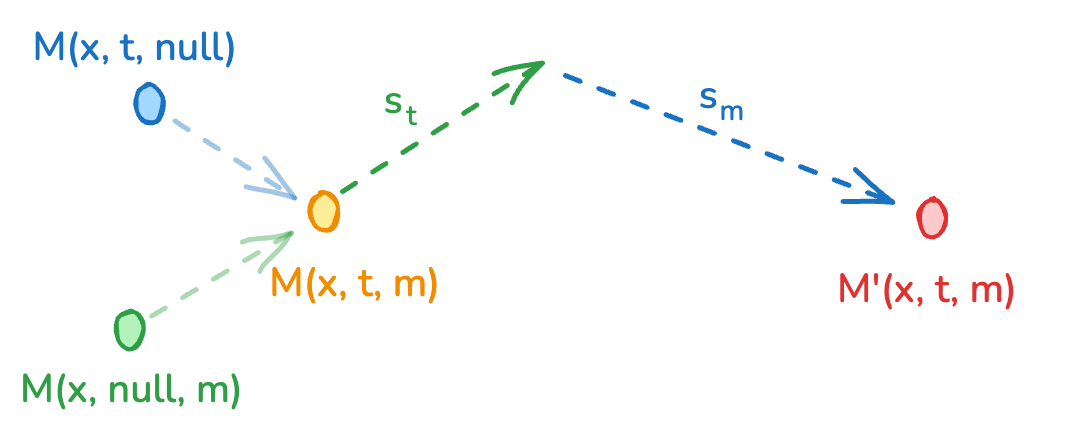
Multimodal classifier-free guidance combining three components: baseline generation, text adherence, and cross-modal synchronization. Each can be controlled independently to shape both the quality and alignment of the output.
The mechanism works by combining three signals. The first is the fully conditioned model output, generated with both text and cross-modal information. The second is a text guidance direction that pushes the output toward following the text description more closely. The third is a cross-modal guidance direction that pushes audio and video toward better alignment with each other.
The final prediction blends all three components with independent control weights. This separation is what makes the mechanism powerful. You can increase text guidance without affecting how tightly audio and video coordinate. Or you can increase cross-modal guidance to make audio follow visual action more closely while keeping text adherence constant.
Without this independence, increasing guidance strength could actually decrease audio-visual alignment as one modality overshoots. Modality-CFG prevents this by treating alignment as its own optimization objective, separate from text adherence. A user can think in high-level terms: "Make the audio follow the visual action more closely" or "Let the audio develop its own emotional atmosphere while still supporting the visuals," and the guidance mechanism translates that into changes to the generation process.
What synchronized audiovisual generation actually means
The engineering complexity serves a purpose beyond technical novelty. LTX-2 generates audio tracks that feel like they were created by someone who watched the video first.
This goes far beyond dialogue. While speech is important, the real achievement is coherent background audio. When a character opens a door in the video, the audio includes a realistic door-opening sound at the precise moment the door moves. When they walk into a forest, the audio shifts to environmental ambience with wind through trees and distant birdsong. When they interact with objects, foley elements respond to their actions.
Semantic coherence emerges naturally. The model learns that video actions should trigger corresponding audio responses. A punch throw should produce wind sound and impact. A character running should have footsteps that match stride length and surface. A conversation should have dialogue that matches lip movements and emotional subtext.
Emotional alignment extends beyond individual sounds. Dark, shadowy scenes receive tense audio. Bright, open spaces receive lighter, more spacious soundscapes. The model learns that the emotional arc of the video should feel reflected in the audio's progression. A scene building toward a climax receives audio that builds tension. A resolution brings audio that resolves alongside it.
The temporal synchronization is where the architecture's constraints pay off. Mouth movements align with dialogue phonemes. Footstep sounds land exactly when feet touch ground. Music swells coordinate with visual intensity increases. This is difficult to achieve through post-processing but falls out naturally from an architecture built for real-time synchronization.
Figure 3 provides evidence that this is actually happening during generation.

Visualization of audio-visual cross-attention maps showing which parts of the video the audio stream attends to at different stages of generation, and vice versa. The maps demonstrate learned synchronization relationships.
The attention maps are averaged across attention heads and layers, showing which regions of the audio the video stream focuses on and which regions of the video the audio stream focuses on. Early stages of inference (V2A and A2V maps shown) reveal that the streams are learning meaningful alignments, not random attention patterns.
Practical efficiency
Building a unified audiovisual model sounds computationally expensive. The outcome is that LTX-2 is actually more efficient than separate models while achieving quality comparable to proprietary systems that use vastly more compute.
The parameter count is 14 billion for video plus 5 billion for audio, totaling 19 billion. This is significant but not massive for a foundation model. The asymmetric allocation prevents wasting capacity on either modality. A symmetric approach would require either duplicating the 19 billion parameters to handle both modalities equally, or running two entirely separate models, each with its own redundancy.
Inference is practical. The model generates audiovisual content at speeds competitive with or faster than proprietary alternatives while using less computational resources. This means the system is deployable, not a research artifact requiring specialized hardware or prohibitive latency.
All model weights and code are publicly released, which means the efficiency translates into accessibility. Researchers can build on the foundation, fine-tune for specific applications, and deploy without licensing restrictions. The computational tractability makes experimentation feasible.
The asymmetric design with bidirectional cross-attention achieves better results with less redundancy than alternatives. You're not solving the same problems twice or duplicating effort. You're specializing each stream for what it actually needs to do while maintaining tight synchronization. That principle, allocating resources asymmetrically while keeping modalities tightly synchronized, extends beyond this specific paper. It's a useful heuristic for any multimodal generation problem where the different modalities have fundamentally different demands.
Original post: Read on AIModels.fyi
[story continues]
tags