Both the Apache DolphinScheduler Master and Worker components support multi-node deployment with a decentralized design.
-
The Master is mainly responsible for splitting the DAG workflow and distributing tasks to Worker nodes through RPC, as well as handling task status updates from the Worker.
-
The worker is responsible for executing tasks and reporting the task status back to the Master, which processes this information.
But what happens in case of failure?
-
What if the Master fails? Since it’s responsible for managing workflow instances, the Worker can no longer report task statuses, and the Master can’t process them either.
-
What if the Worker fails? Since it’s the one executing the actual tasks, how does the Master handle this situation?
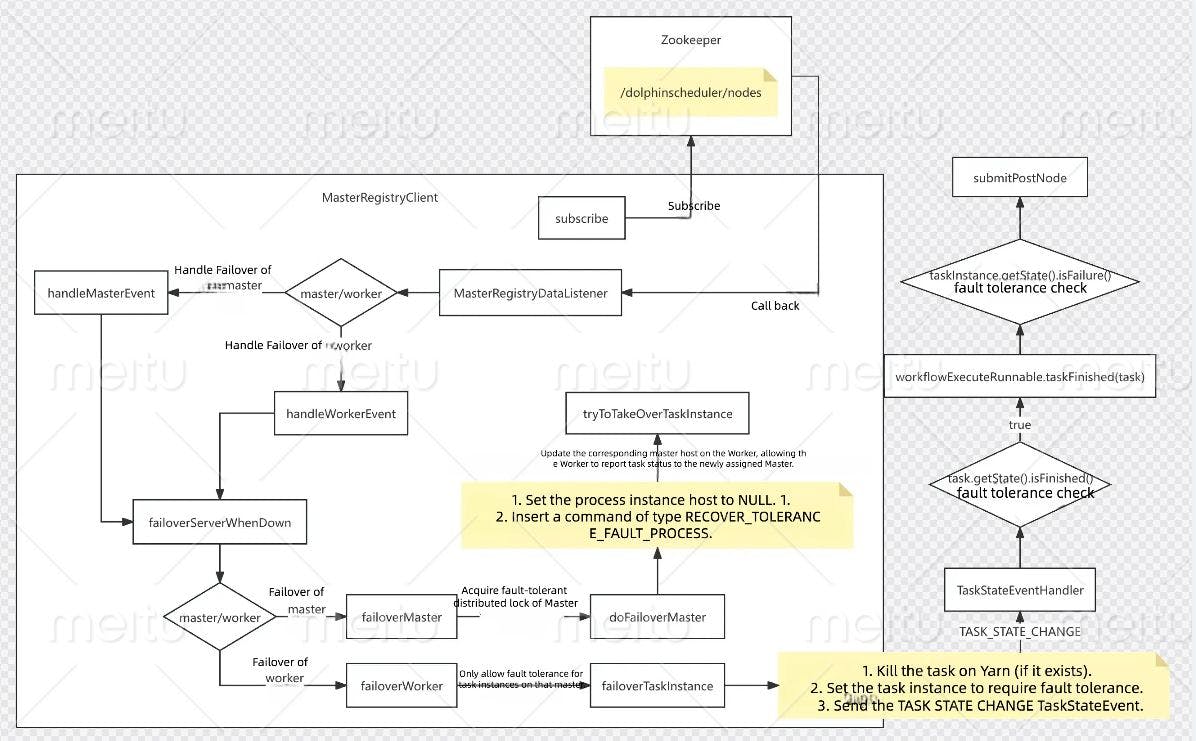
Let’s dive into the fault tolerance mechanism with the help of an illustration:
Fault Tolerance
Here’s a breakdown of how DolphinScheduler handles failures:
- If the Master fails: Other Master nodes will handle the failover using a distributed lock. The workflow instance will switch from the failed Master to a new Master. In this case, the system will issue the new Master’s host address to the Worker, enabling it to report the task status to the new Master.
-
If the Worker fails: The system retries the task. However, before retrying, it needs to kill the task that is still running on YARN. Currently, DolphinScheduler does not support this out-of-the-box, because in a non-client-separated mode, the
ProcessBuilder.waitFormethod waits for the client process to exit. TheapplicationIdis parsed only after this process exits, meaning the system can only obtain theapplicationIdafter the program has finished running.
In other words, you can’t get the applicationIduntil the process is completed.
Here’s the relevant code section:
org.apache.dolphinscheduler.server.master.service.WorkerFailoverService#killYarnTask
private void killYarnTask(TaskInstance taskInstance, ProcessInstance processInstance) {
try {
if (!masterConfig.isKillApplicationWhenTaskFailover()) {
return;
}
if (StringUtils.isEmpty(taskInstance.getHost()) || StringUtils.isEmpty(taskInstance.getLogPath())) {
return;
}
TaskExecutionContext taskExecutionContext = TaskExecutionContextBuilder.get()
.buildWorkflowInstanceHost(masterConfig.getMasterAddress())
.buildTaskInstanceRelatedInfo(taskInstance)
.buildProcessInstanceRelatedInfo(processInstance)
.buildProcessDefinitionRelatedInfo(processInstance.getProcessDefinition())
.create();
log.info("TaskInstance failover begin kill the task related yarn or k8s job");
ILogService iLogService =
SingletonJdkDynamicRpcClientProxyFactory.getProxyClient(taskInstance.getHost(), ILogService.class);
GetAppIdResponse getAppIdResponse =
iLogService.getAppId(new GetAppIdRequest(taskInstance.getId(), taskInstance.getLogPath()));
ProcessUtils.killApplication(getAppIdResponse.getAppIds(), taskExecutionContext);
} catch (Exception ex) {
log.error("Kill yarn task error", ex);
}
}
What can be done?
In version 1.3.3, the LoggerServer and Masterwere separated, allowing the Master node (if it had the YARN client) to kill the applicationId running on YARN. So what now?
Two Possible Solutions:
- Master kills the task using the YARN REST API:
curl -X PUT -d '{"state":"KILLED"}' \
-H "Content-Type: application/json" \
http://xx.xx.xx.xx:8088/ws/v1/cluster/apps/application_1694766249884_1098/state?user.name=hdfs
Note: You need to specify the user.
2. Worker kills the task:
In this case, the task should be marked as a failover task. During retry, the task should be scheduled on a designated Worker node. Before retrying, the runningapplicationId needs to be killed. One optimization would be to first check the YARN status before killing. If the status is abnormal, then kill it. If it's RUNNING, you can wait for a set timeout period.