
Welcome to the world of Apache SeaTunnel! This guide helps beginners quickly understand SeaTunnel’s core features, architecture, and run their first data sync job.
1. What is Apache SeaTunnel?
Apache SeaTunnel is a high-performance, easy-to-use data integration platform supporting both real-time streaming and offline batch processing. It solves common data integration challenges such as diverse data sources, complex sync scenarios, and high resource consumption.
Core Features
- Wide Data Source Support: 100+ connectors covering databases, cloud storage, SaaS services, etc.
- Batch & Stream Unified: Same connector code supports both batch and streaming processing.
- High Performance: Supports multiple engines (Zeta, Flink, Spark) for high throughput and low latency.
- Easy to Use: Define complex sync tasks with simple configuration files.
2. Architecture & Environment
2.1 Architecture
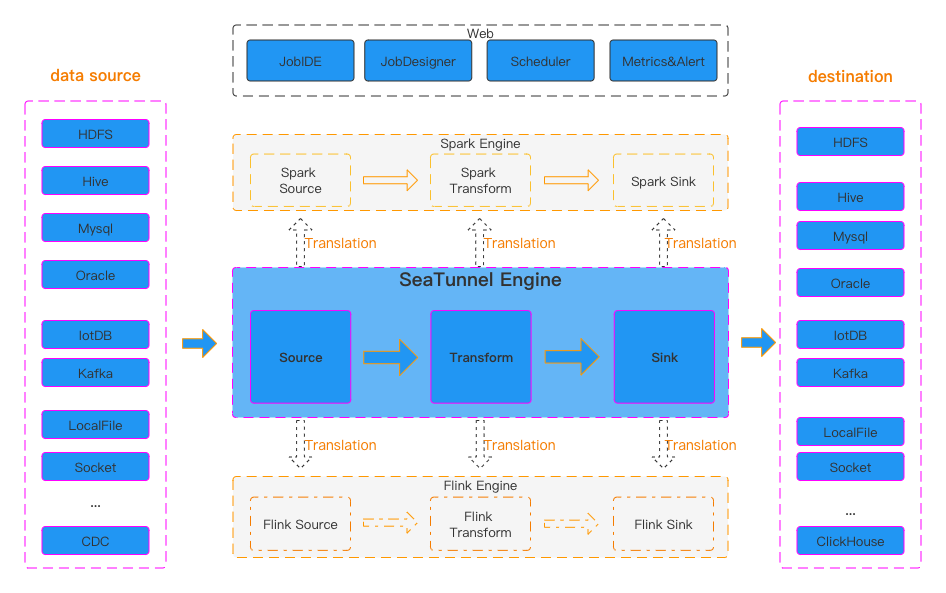
SeaTunnel uses a decoupled design: Source, Transform, Sink plugins are separated from execution engines.
2.2 OS Support
| OS | Use Case | Notes |
|---|---|---|
| Linux(CentOS, Ubuntu, etc.) | Production(recommended) | Stable, suitable for long-running services. |
| macOS | Development/Test | Suitable for local debugging and config development. |
2.3 Environment Preparation
Before installation, ensure:
- JDK Version: Java 8 or 11 installed.
- Check with
java -version. - Set
JAVA_HOMEenvironment variable.
3. Core Components Deep Dive
3.1 Source
Reads external data and converts it into SeaTunnel’s internal row format (SeaTunnelRow).
- Enumerator: Runs on Master, discovers data splits. For JDBC, calculates query ranges based on
partition_column. - Reader: Runs on Worker, processes assigned splits. Parallel readers improve throughput.
- Checkpoint Support: For streaming jobs, stores state (e.g., Kafka offsets) for fault recovery.
3.2 Transform
Processes data between Source and Sink.
- Stateless: Most transforms (
Sql,Filter,Replace) don’t rely on other rows. - Schema Changes: Transform can modify schema; downstream Sink detects these changes.
3.3 Sink
Writes processed data to external systems.
- Writer: Runs on Worker, writes data in batches for throughput.
- Committer: Optional, runs on Master for transactional Sinks. Supports Exactly-Once semantics.
3.4 Execution Flow
- Parse config → build logical plan.
- Master allocates resources.
- Enumerator generates splits → Reader processes them.
- Data flows:
Reader -> Transform -> Writer. - Periodic checkpoints save state & commit transactions.
4. Supported Connectors & Analysis
4.1 Relational Databases (JDBC)
Supported: MySQL, PostgreSQL, Oracle, SQLServer, DB2, Teradata, Dameng, OceanBase, TiDB, etc.
- Pros: Universal via JDBC, parallel reads, auto table creation, Exactly-Once support.
- Cons: JDBC limitations may affect performance; high parallelism can stress source DB.
4.2 Message Queues
Supported: Kafka, Pulsar, RocketMQ, DynamoDB Streams.
- Pros: High throughput, multiple serialization formats, Exactly-Once support.
- Cons: Complex config (offsets, schemas, consumer groups); debugging less intuitive.
4.3 Change Data Capture (CDC)
Supported: MySQL-CDC, PostgreSQL-CDC, Oracle-CDC, MongoDB-CDC, SQLServer-CDC, TiDB-CDC.
- Pros: Millisecond-level capture, lock-free snapshot, supports resume & schema evolution.
- Cons: Requires high DB privileges, relies on Binlog/WAL.
4.4 File Systems & Cloud Storage
Supported: LocalFile, HDFS, S3, OSS, GCS, FTP, SFTP.
- Pros: Massive storage, supports multiple formats & compression.
- Cons: Small file problem in streaming; merging adds complexity.
4.5 NoSQL & Others
Supported: Elasticsearch, Redis, MongoDB, Cassandra, HBase, InfluxDB, ClickHouse, Doris, StarRocks.
- Optimized for each DB, e.g., Stream Load for ClickHouse/StarRocks, batch writes for Elasticsearch.
5. Transform Hands-On
5.1 SQL Transform
transform {
Sql {
plugin_input = "fake"
plugin_output = "fake_transformed"
query = "select name, age, 'new_field_val' as new_field from fake"
}
}
5.2 Filter Transform
transform {
Filter {
plugin_input = "fake"
plugin_output = "fake_filter"
include_fields = ["name", "age"]
}
}
5.3 Replace Transform
transform {
Replace {
plugin_input = "fake"
plugin_output = "fake_replace"
replace_field = "name"
pattern = " "
replacement = "_"
is_regex = true
replace_first = true
}
}
5.4 Split Transform
transform {
Split {
plugin_input = "fake"
plugin_output = "fake_split"
separator = " "
split_field = "name"
output_fields = ["first_name", "last_name"]
}
}
6. Quick Installation
- Download latest SeaTunnel binary.
- Extract & enter folder:
tar -xzvf apache-seatunnel-2.3.x-bin.tar.gz
cd apache-seatunnel-2.3.x
- Install plugins:
sh bin/install-plugin.sh
💡 Tip: Configure Maven mirror (e.g., Aliyun) for faster downloads.
7. First SeaTunnel Job
Create hello_world.conf under config folder. Example config generates fake data and prints to console.
Run locally using Zeta engine:
./bin/seatunnel.sh --config ./config/hello_world.conf -e local
- Monitor logs:
Job execution started,SeaTunnelRowoutputs, andJob Execution Status: FINISHED.
8. Troubleshooting
command not found: java→ Check Java installation &JAVA_HOME.ClassNotFoundException→ Connector plugin not installed.Config file not valid→ Check HOCON syntax.- Task hangs → Check resources or streaming mode.
9. Advanced Resources
- Official Docs
- Connector list:
docs/en/connector-v2 - Example configs:
config/*.template
Apache SeaTunnel unifies batch & streaming, supports rich connectors, and is easy to deploy. Dive in, explore, and make your data flow effortlessly!
[story continues]
tags