The efficiency paradox at scale
Modern AI models have a hidden cost nobody talks about: they get slower as they get smarter. A 400-billion-parameter model is more capable than a 100-billion-parameter model, but it's also about 4 times slower to run. Every token generated requires computation through every parameter, which means massive models inevitably become massive expenses. This creates an impossible choice for anyone deploying language models at scale. Either you use smaller models that are cheap but dumb, or you use large models that are smart but bankrupt you.
Arcee Trinity proposes a different path. What if you could build a 400-billion-parameter model that only uses 13 billion parameters per token? You'd get the reasoning capability of a massive model with the speed of something much smaller. This isn't hypothetical. Trinity Large exists, has been trained, and performs better than competing models while being faster to run. The key insight that makes this possible isn't new in concept but was extremely difficult in practice: not every token needs every expert.
This is the fundamental tension the Trinity research solves. For years, sparse mixture-of-experts models have theoretically offered this advantage but practically failed to deliver because training them was unstable. Models would collapse during training as certain experts became popular while others atrophied. The research presents a system that trains smoothly from start to finish, with zero loss spikes, demonstrating that sparse models can now scale to genuinely massive sizes with the reliability engineers expect from dense models.
How sparse models actually route
Imagine a language model as a library where the "knowledge" is distributed across many small experts rather than concentrated in one big expert. For each token, a router decides which experts to consult. Expert 1 might be specialized in mathematics, expert 2 in coding, expert 3 in natural language reasoning. When a token arrives asking about a Python function, the router learns to send it primarily to the coding expert, secondarily to the mathematics expert. The model doesn't need all its capacity to answer every question, just the relevant capacity.
This is what mixture-of-experts accomplishes. Instead of one massive dense model, you have many smaller experts plus a learned routing function. The router is trained end-to-end alongside the experts, so it learns which experts matter for which patterns. In practice, the router is remarkably simple: just a learned weight matrix that outputs a probability distribution over experts.
The beauty of this approach is that it decouples model capacity from inference cost. A mixture-of-experts model with 400 billion parameters can be designed so that only 13 billion are activated per token. Compare this to a dense model where all 400 billion parameters are used for every single token. The sparse model processes information faster while maintaining access to the same total knowledge.
The training instability problem
This is where the practical complexity emerges, and where most sparse models have historically failed. When you start training a mixture-of-experts model, the router learns very quickly which experts are useful and which aren't. But there's a feedback loop. Suppose expert 1 gets selected frequently for the first 1,000 training steps. Because it's being used, it gets trained intensively and improves. Because it improves, the router prefers it even more. Meanwhile, expert 7, which never got selected, doesn't improve, so the router avoids it further. Suddenly your 400 experts has effectively collapsed into using just 5.
This collapse manifests as catastrophic loss spikes during training. The loss curve becomes unstable and noisy. More critically, you can't train the model for very long before the routing has completely broken down. Previous strategies tried to fix this with heavy-handed constraints: force each expert to handle exactly the same number of tokens, or penalize the router for imbalanced expert usage. These constraints work to some degree but create their own problems, adding complexity to training and sometimes forcing the router to use bad experts just to meet the balance requirement.
The Trinity team's innovation was recognizing that you don't need hard constraints. You need mechanisms that gently prevent runaway success and failure without completely suppressing the router's ability to specialize.
Soft-clamped momentum expert bias updates
The solution is called Soft-clamped Momentum Expert Bias Updates, abbreviated SMEBU. To understand why this works, you need to know that the router has a learned bias term for each expert, a scalar value that influences how likely that expert is to be selected. When an expert gets used frequently, you want to boost its bias to make it even more attractive. When an expert gets ignored, you'd normally suppress its bias further. SMEBU prevents both of these from running away.
The "soft clamp" means you increase or decrease expert biases, but only up to a limit. The router can still develop preferences, but not infinite ones. An expert that's frequently selected gets boosted, but the boost levels off, preventing the feedback loop from accelerating forever. An expert that's rarely selected doesn't get suppressed below a floor, so it remains viable even if it's temporarily unpopular.
The "momentum" part means you don't update biases based on raw selection frequency. Instead, you use an exponential moving average of how often experts are selected. This smooths out temporary fluctuations. If expert 5 happens to get selected a lot in one batch due to random initialization, momentum prevents you from overcommitting to it. You need consistent preference for an expert before the bias strongly favors it.
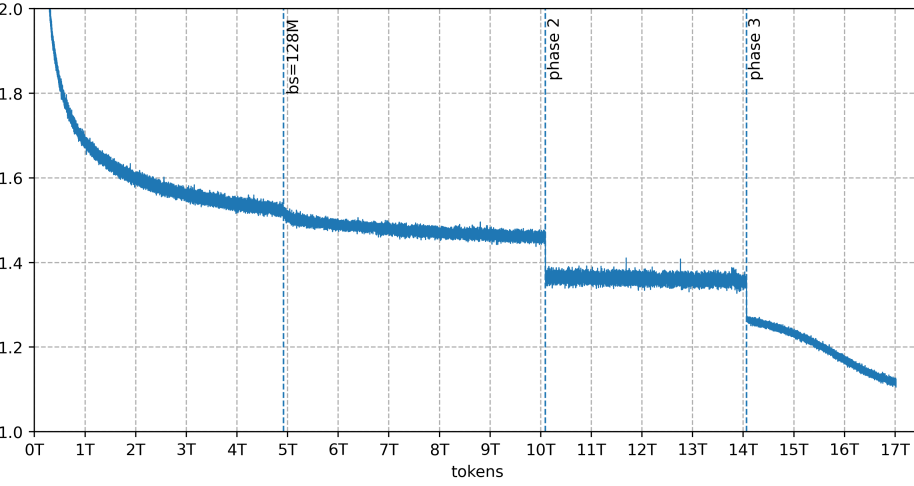
Together, these two mechanisms act as shock absorbers. They allow the router to learn specialization without the system falling apart. Critically, training becomes stable. Looking at the training loss graph for Trinity Large, there are no spikes, no collapses, no moments where the loss suddenly jumps. The curve is smooth from beginning to end, which is visually striking if you've seen other sparse model training runs.
The training loss curve for Trinity Large, showing stable training with zero loss spikes across pre-training on 17 trillion tokens.
The training loss graph for Trinity Large, with no sub-sampling or smoothing. Batch size increases to 128M tokens and data mixture switches are indicated. The smooth curve demonstrates zero loss spikes throughout the entire training run.
Architecture choices for massive scale
Beyond load balancing, building a 400-billion-parameter model requires architectural decisions at every layer. You can't just scale up a smaller model's architecture, you need innovations that specifically address the challenges of extreme scale.
Trinity uses two different attention mechanisms. Local attention keeps each token attending only to nearby tokens in a sliding window, which is computationally fast. Global attention designates specific tokens that attend to the full context, providing long-range coherence. This hybrid approach handles attention without the quadratic cost that would make inference prohibitively slow. You get both efficiency and the global dependencies that large models need.
The model also incorporates gated attention, where learned gates control how strongly each attention relationship activates. This gives the router additional flexibility to selectively use or ignore attention patterns depending on the context. Combined with grouped-query attention in the local layers, this balances expressiveness with efficiency.
Finally, Trinity uses depth-scaled sandwich normalization. In deep networks, signals can become unstable as information flows through many layers. This normalization technique adjusts its strength based on depth, applying more stabilization in layers where it's needed and less where signals are already stable. For a 400-layer model, these stabilization choices compound.
The architecture diagram shows how these pieces fit together:
Trinity model architecture showing local and global attention patterns, routing mechanisms, and normalization placement across the model depth.
The architecture of the Trinity model family. RoPE (rotary position embeddings) appears only in local layers. Grouped-query attention includes a sliding window for local layers.
None of these architectural choices is revolutionary individually. But at the scale of 400 billion parameters, their combination matters tremendously. Each addresses a specific scaling challenge: local/global attention handles computational complexity, gated attention provides routing flexibility, depth-scaled normalization maintains training stability. They work together as a system.
Real-world performance
The practical test is whether Trinity models actually perform better than existing alternatives. Benchmark results answer this definitively.
Trinity Large base model compared to other open-weight base models across multiple evaluation benchmarks.
A comparison of Trinity Large Base to other similar open-weight base models.
Trinity Large outperforms comparable dense models on standard benchmarks. This is crucial because it proves the sparse approach isn't a trade-off where you sacrifice quality for efficiency. You actually get better language models. The 400-billion-parameter model with 13 billion activated outperforms models that have fewer total parameters but activate all of them. The routing mechanism learns genuinely useful specialization.
The speed advantage is equally important. This is where theory becomes practice.
Trinity Large throughput comparison with other models, all quantized to FP8 running on 8xH200 hardware via vLLM.
Throughput comparison of models. All tests were done with models quantized to FP8, using vLLM, on 8xH200.
Trinity Large processes tokens significantly faster than dense alternatives, sometimes by 2x or more depending on the comparison model. This isn't a slight improvement, it's the kind of throughput gain that changes what's economically viable to run. For a company operating inference at scale, this difference directly translates to infrastructure costs.
The practical payoff
Building these models matters because it solves an engineering problem that's becoming increasingly acute. As AI capabilities improve, the models that deliver those capabilities get larger and more expensive. Trinity demonstrates a path where you don't have to choose between capability and cost. The sparse approach gives you both.
The Trinity family comes in three sizes. Trinity Nano has 6 billion total parameters with 1 billion activated per token, trained on 10 trillion tokens. Trinity Mini scales to 26 billion total with 3 billion activated, also on 10 trillion tokens. Trinity Large reaches 400 billion total with 13 billion activated on 17 trillion tokens. This range means practitioners can choose the right model for their constraints rather than being forced to pick between "too small but cheap" and "powerful but unaffordable."
The zero loss spikes during training matter more than might initially appear. Smooth training means you can scale to massive models with the same confidence you'd have with smaller models. There's no risk of hitting instability walls that force you to restart or redesign. The research suggests that sparse models have matured past the point where they're exotic research projects. They're now practical systems for production use.
The connection to work on other sparse model research shows that the broader field is converging on similar solutions. Different teams arriving at comparable architectures and training strategies indicates that sparse models aren't lucky accidents but reflect deeper principles about how to scale language models efficiently.
Why this matters going forward
The fundamental implication is that the future of large language model development probably isn't "make them bigger and slower." It's "make them smarter about which parameters they use." The research proves that you can train sparse models with stability comparable to dense models while gaining substantial efficiency and performance benefits.
For researchers building models above 10 billion parameters, the SMEBU strategy and architectural choices are directly applicable. For deployment teams, Trinity's throughput performance shows what's achievable with current sparse model technology. For the open-source community, having these models available on Hugging Face means the advances aren't locked behind proprietary systems.
The training curve without loss spikes is the clearest signal that something has fundamentally shifted. For years, the stability problems with sparse models were presented as inevitable tradeoffs. This research indicates they were actually solvable engineering problems that required the right combination of load balancing strategy, architecture design, and optimizer choice. That matters because it redefines what's possible at scale.
This is a Plain English Papers summary of a research paper called Arcee Trinity Large Technical Report. If you like these kinds of analysis, join AIModels.fyi or follow us on Twitter.