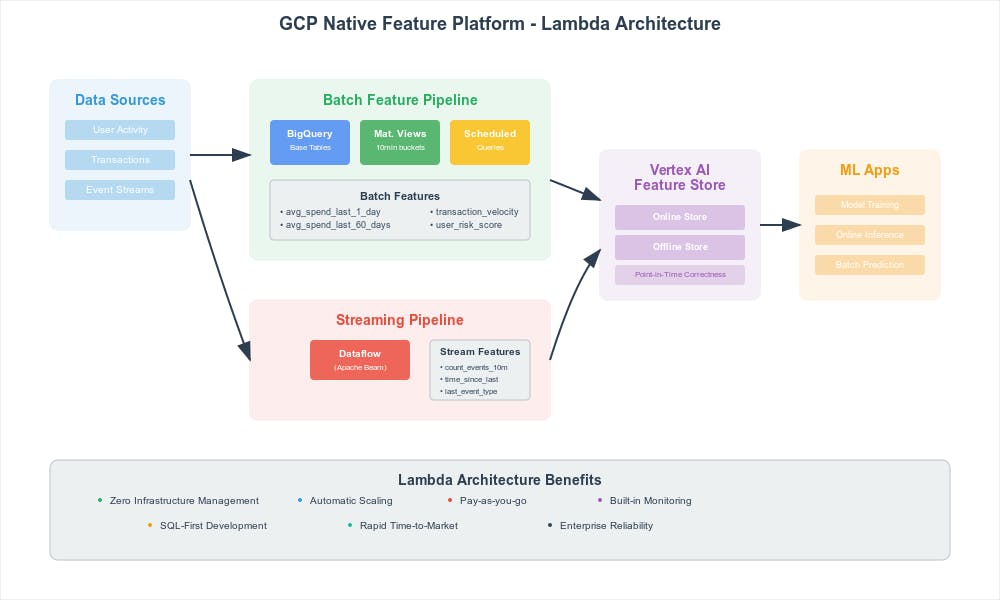
The landscape of machine learning is changing quickly, leaving organizations with a critical decision: build a feature platform from scratch or leverage cloud-native services? This post examines a pure lambda-style feature platform built entirely on Google Cloud Platform's native services - a solution we've implemented in production that delivers enterprise-scale feature engineering capabilities with surprisingly minimal operational overhead.
The Zero-Ops Feature Engineering Vision
The architecture we'll explore embodies the serverless philosophy applied to feature engineering. By combining BigQuery Materialized Views, Scheduled Queries, Dataflow pipelines, and Vertex AI Feature Store, this solution aims to eliminate the operational complexity typically associated with feature platforms while maintaining production-grade performance and reliability.
Architecture Overview
Figure 1: Lambda-style architecture leveraging GCP managed services for both batch and streaming feature pipelines
The platform operates on two distinct but complementary pipelines:
Batch Feature Pipeline: SQL-Driven Aggregations
The batch pipeline leverages BigQuery's native capabilities for time-window aggregations:
Data Source → Materialized Views → Scheduled Queries → Vertex AI Feature Store
Streaming Feature Pipeline: Real-Time Event Processing
The streaming pipeline uses Dataflow for low-latency feature computation:
Event Streams → Dataflow (Apache Beam) → Vertex AI Feature Store
Batch Feature Engineering
The Power of Materialized Views
The batch pipeline's foundation lies in BigQuery Materialized Views (MVs), which solve a critical scaling challenge and create cascading benefits across the entire feature platform. In our production implementation, we battle-tested this design using 15-minute aggregate materialized views—the 10-minute interval shown in examples is just a parameter to tweak based on your desired refresh cadence for batch pipelines and also you the amount of money you want to spend.
The Fundamental Problem: Computing large window features (1-day, 60-day averages) directly from raw event data means scanning massive datasets repeatedly—potentially terabytes of data for each feature calculation.
The MV Solution: We've found that pre-aggregating raw events into 10-minute buckets reduces downstream data processing by ~600x:
Why This Transforms the Entire System:
- Batch Feature Speed: Large window aggregations compute in seconds instead of minutes
- Cost Efficiency: Query costs drop dramatically (scanning MB instead of TB)
- Faster Forward Fill: Historical feature backfilling becomes practical at enterprise scale
- Streaming Optimization: Since batch handles long windows efficiently, streaming can focus on short-term features (≤10 minutes), avoiding expensive long-term state management
- System Simplicity: Clear separation of concerns between batch (long windows) and streaming (immediate features)
CREATE MATERIALIZED VIEW user_features_by_10min_bucket_mv
PARTITION BY feature_timestamp
CLUSTER BY entity_id
OPTIONS (
enable_refresh = true,
refresh_interval_minutes = 10
)
AS
SELECT
TIMESTAMP_BUCKET(source.event_timestamp, INTERVAL 10 MINUTE) AS feature_timestamp,
source.userid AS entity_id,
AVG(source.activity_value) AS avg_value_last_10_mins,
SUM(source.activity_value) AS sum_value_for_sliding_avg,
COUNT(source.activity_value) AS count_for_sliding_avg
FROM my_project.my_dataset.user_activity AS source
WHERE TIMESTAMP_TRUNC(source.event_timestamp, HOUR) >= TIMESTAMP('2000-01-01T00:00:00Z')
GROUP BY feature_timestamp, entity_id
Key Benefits:
- Automatic Refresh: MVs incrementally update every 10 minutes
- Query Optimization: Subsequent queries leverage pre-computed results
- Historical Coverage: Broad time filters enable comprehensive backfilling
Leveraging MV Efficiency
Building upon the MVs, scheduled queries compute complex sliding window features with remarkable efficiency. Key insight we discovered: Instead of spanning across raw events, these queries operate on the pre-aggregated 10-minute buckets, which makes a world of difference. For refresh cadences, we implemented a 1/5 rule truncated to a maximum of every 5 hours: 1-hour window features refresh every 15 minutes, 3-hour windows at 45 minutes, 24-hour windows every 5 hours, and 60-day windows at 5 hours.
Important caveat: This MV optimization only works for simple aggregations (SUM, COUNT, AVG). We learned this the hard way when dealing with complex aggregations requiring sorting and ROW_NUMBER() functions—the MV optimizations were not applicable to these, and we had to run the entire aggregation logic in scheduled queries instead.
Figure 2: Window function-based computation of 1-day and 60-day sliding averages using 10-minute bucket aggregates
-- Window frame: Last 144 buckets (1 day) ending at current bucket
SUM(sum_value_for_sliding_avg) OVER (
PARTITION BY entity_id
ORDER BY feature_timestamp ASC
ROWS BETWEEN 143 PRECEDING AND CURRENT ROW
) AS sum_1_day_sliding
The Efficiency Multiplier:
- Traditional Approach: 60-day sliding window = scan 60 days of raw events (potentially 1TB+ per query)
- MV-Powered Approach: 60-day sliding window = scan 8,640 pre-aggregated buckets (~1MB per query)
This ~1000x data reduction enables:
- Sub-second Feature Computation: Large window features that previously took minutes now complete in seconds
- Cost-Effective Backfilling: Historical feature generation becomes economically viable
- Real-time Forward Fill: Fresh features can be computed continuously without breaking the budget
- Streaming Focus: Stream processing freed from long-window state management, enabling cost-effective real-time features
Feature Examples Enabled:
- Average spending over 1 hour, 12 hours, 24 hours (computed from 6, 72, 144 buckets respectively)
- Transaction velocity across 1-day, 7-day, 30-day windows
- User engagement trends spanning weeks or months
Streaming Feature Engineering
Real-Time Processing with Dataflow
The streaming pipeline handles low-latency features that require immediate computation:
Figure 3: Dataflow pipeline processing real-time events with windowing and state management
Streaming Pipeline Optimization Through MV Design:
The materialized view strategy fundamentally changes what the streaming pipeline needs to handle:
Before MV Optimization:
- Streaming pipeline manages state for long windows (hours, days)
- Expensive persistent state storage for millions of entities
- Complex checkpointing for multi-day windows
- High memory requirements and operational overhead
After MV Optimization:
- Streaming focused on immediate features (≤10 minutes)
- Lightweight state management for short windows
- Reduced operational complexity and costs
- Clear architectural boundaries
Key Streaming Features (Optimized Scope):
- Count Events Last N Minutes: Only short windows (≤10 min), since batch handles longer periods efficiently
- Time Since Last Event: Stateful processing per entity, reset frequently
- Last Event Type: State-based feature tracking with minimal memory footprint
- Real-time Anomaly Flags: Immediate detection requiring sub-second latency
Streaming Feature Backfilling
For streaming features, we use a unified Beam pipeline approach that reuses the exact streaming logic for historical data. This ensures identical computation semantics and eliminates any discrepancies between batch and streaming feature calculations.
In our implementation, all streaming features are simple aggregations needed in real-time—things like event counts, sums, and basic statistical measures over short windows. The streaming pipeline handles the "last mile" features, specifically the latest 15-minute window aggregations. These streaming features are then augmented with the longer-term batch features before being sent to our models, giving us both real-time responsiveness and historical context.
Vertex AI Feature Store Integration
The platform culminates in Vertex AI Feature Store V2, which we chose after careful consideration. Vertex AI Feature Store's batch export functionality just opened for general adoption, and we tested it out on a smaller scale—it looks promising so far. The high-maintenance alternative would be the battle-tested Feast feature store open source solution, but we decided to bet on Google's managed offering to reduce our operational overhead.
The integration provides:
Figure 4: Unified feature serving with point-in-time correctness for both batch and streaming features
Key Capabilities:
- Point-in-Time Correctness: Accurate training data generation
- Online Serving: Low-latency feature retrieval
- Mixed Feature Types: Batch and streaming features co-exist
- Automatic Versioning: Feature schema evolution support
Strengths of this Approach
Operational Excellence
- Zero Infrastructure Management: Fully managed services eliminate operational overhead
- Automatic Scaling: Services scale based on demand without intervention
- Built-in Monitoring: Native GCP monitoring and alerting
- Simplified Deployments: No cluster management or resource provisioning
Cost Efficiency Through MV-Driven Design
- Pay-as-you-go: Only pay for actual compute and storage usage
- Dramatic Query Cost Reduction: MVs reduce data scanning by ~1000x (TB→MB per query)
- Streaming Cost Optimization: Short-window focus eliminates expensive long-term state management
- Efficient Forward Fill: Historical feature generation becomes economically viable
Developer Productivity
- SQL-First Approach: Familiar tooling for data practitioners
- Rapid Prototyping: Quick iteration on feature definitions
- IDE Integration: Native BigQuery and Dataflow tooling
Technical Advantages
- Proven Scalability: BigQuery handles petabyte-scale datasets
- Automatic Optimization: Query optimizer handles performance tuning
- Data Freshness: Near real-time updates through MVs and streaming
- Backup and Recovery: Built-in data protection and disaster recovery
Limitations and Trade-offs
Platform Lock-in Concerns
- Vendor Dependency: Heavy reliance on GCP-specific services
- Migration Complexity: Difficult to port to other cloud providers
- Pricing Volatility: Subject to GCP pricing changes
- Feature Parity: Limited by GCP service capabilities and roadmap
Architectural Constraints
- Limited Flexibility: Constrained by BigQuery and Dataflow capabilities
- Complex Features: Some ML features may not map well to SQL
- Cross-Service Dependencies: Failures cascade across multiple services
- Consistency Challenges: Eventual consistency between batch and streaming
Data Engineering Limitations
- Transformation Complexity: Complex business logic harder to express in SQL
- Schema Evolution: Changes require careful coordination across services
What We've Learned About Lambda-Style Feature Engineering
After implementing this GCP Native Feature Platform in production, we've found it represents a compelling vision of infrastructure-as-code applied to feature engineering. By embracing the lambda architecture paradigm and leveraging managed services, we've been able to dramatically reduce operational complexity while maintaining enterprise-scale capabilities.
This approach excels when:
- Teams want to focus on feature logic rather than infrastructure
- Operational simplicity is prioritized over maximum flexibility
- Organizations already have significant GCP investments
- Time-to-market is critical for competitive advantage
Consider alternatives when:
- Maximum control over processing logic is required
- Multi-cloud or hybrid deployment strategies are needed
- Complex, non-SQL-friendly feature transformations are common
- Vendor lock-in presents significant business risks
The lambda-style approach fundamentally shifts the feature platform paradigm from "infrastructure management" to "feature logic optimization." For many organizations, this trade-off represents a strategic advantage, enabling data science teams to focus on what matters most: creating features that drive business value.
As cloud-native services continue to mature, we can expect this architectural pattern to become increasingly prevalent, making sophisticated feature engineering capabilities accessible to organizations without large platform engineering teams.