
30% of the world's piped water is lost to leaks before it ever reaches a tap.
In software terms, that is a memory leak so massive it would crash production in seconds. In the physical world, it costs billions of dollars and wastes a critical resource. Add to that inefficient pumps burning 30% more energy than needed, and you have a legacy infrastructure system begging for a refactor.
We cannot just "patch" the pipes physically. We need to patch the logic.
In this guide, we are going to architect a Smart Water Management Framework. We will move beyond simple thresholds and implement four distinct Machine Learning models to handle:
- Leak Detection (AutoEncoders)
- Pump Maintenance (Random Forest)
- Water Quality (SVM)
- Usage Forecasting (LSTM)
We will use Python (Scikit-learn, TensorFlow), IoT sensors, and real-time messaging (MQTT) to build this. Let’s dive in.
The Architecture: Edge-to-Cloud
Before we write code, we need to understand the data pipeline. We aren't just logging data; we are processing streams.
We are simulating a system where Edge Nodes (ESP32/Raspberry Pi) collect data and lightweight ML inference happens either at the edge or via a cloud processing layer.
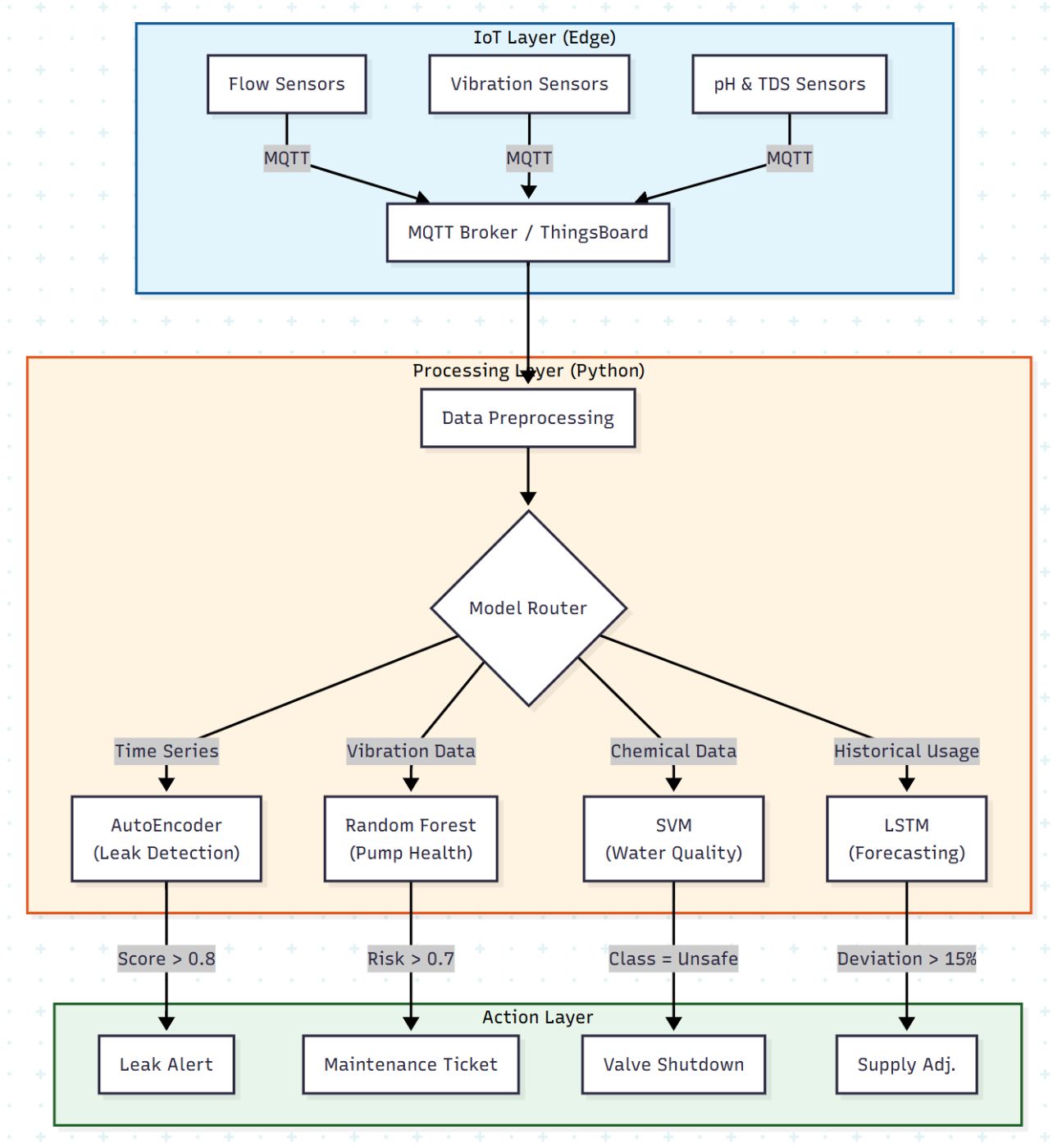
The Data Stack
- Ingestion: ThingsBoard (for visualization) & MQTT.
- Preprocessing: Median imputation, IQR outlier removal, MinMaxScaler.
- ML Libraries: Scikit-learn, Keras/TensorFlow.
Use Case 1: Leak Detection (The AutoEncoder)
The Problem:Traditional leak detection waits for a user to report a puddle.
The Solution: Anomaly detection on time-series flow data.
We use an AutoEncoder. This is an unsupervised neural network that learns the "normal" pattern of water flow. If the reconstruction error is high, it means the current pattern (a leak) doesn't match the normal baseline.
The Logic: If AutoEncoder(x) > 0.8 Threshold -> Trigger Alert
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
# 1. Define the AutoEncoder Architecture
model = Sequential([
# Encoder: Compress the input (flow rate time-series)
Dense(32, activation='relu', input_shape=(100,)),
Dense(16, activation='relu'),
# Bottleneck: The "Latent Space"
Dense(8, activation='relu'),
# Decoder: Reconstruct the input
Dense(16, activation='relu'),
Dense(32, activation='relu'),
Dense(100, activation='sigmoid') # Output matches input shape
])
model.compile(optimizer='adam', loss='mse')
# 2. Detect Anomalies
def detect_leak(new_data, threshold=0.8):
# Try to reconstruct the input
reconstruction = model.predict(new_data)
# Calculate Mean Squared Error (Reconstruction Loss)
loss = np.mean(np.power(new_data - reconstruction, 2), axis=1)
if loss > threshold:
return True, loss
return False, loss
# Result from Research: 80% faster detection than manual inspection.
Use Case 2: Predictive Maintenance (Random Forest)
The Problem:Pumps fail unexpectedly. Reactive maintenance is expensive.
The Solution: Predict failure before it happens using vibration, pressure, and motor current.
We use a Random Forest Regressor. It’s excellent for handling non-linear boundaries and is robust against the noise often found in industrial sensors.
The Logic: If Failure_Risk_Score > 0.7 -> Schedule Maintenance
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
# Features: Vibration (Hz), Pressure (Psi), Motor Current (Amps)
X = sensor_data[['vibration', 'pressure', 'current']]
y = sensor_data['failure_risk_score'] # Historical labels
# Initialize and Train
rf_model = RandomForestRegressor(n_estimators=100, max_depth=10)
rf_model.fit(X, y)
def check_pump_health(live_readings):
# live_readings = [[0.45, 120, 15.5]]
risk_score = rf_model.predict(live_readings)
print(f"Current Failure Risk: {risk_score[0]}")
if risk_score[0] > 0.7:
trigger_mqtt_alert("PUMP_MAINTENANCE_REQUIRED")
# Result from Research: Reduced energy usage by 25% and downtime by ~60%.
Use Case 3: Water Quality Monitoring (SVM)
The Problem:Contamination events are often detected too late (lab tests take days).
The Solution: Real-time classification using Support Vector Machines (SVM).
SVMs are powerful for binary classification (Safe vs. Unsafe) in high-dimensional spaces. We feed it pH, Hardness (TDS), and Chloramines data.
The Logic: Classify as SAFE (1) or UNSAFE (0)
from sklearn.svm import SVC
from sklearn.preprocessing import StandardScaler
# 1. Pipeline for Preprocessing
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X_raw) # pH, TDS, Solids, Chloramines
# 2. SVM Classifier
# Kernel 'rbf' allows for non-linear separation boundaries
svm_model = SVC(kernel='rbf', probability=True)
svm_model.fit(X_scaled, y_labels)
def monitor_quality(sensor_array):
# Standardize input exactly like training data
clean_input = scaler.transform([sensor_array])
prediction = svm_model.predict(clean_input)
if prediction[0] == 0: # 0 represents 'Unsafe'
return "CRITICAL: CONTAMINATION DETECTED"
return "Water Quality: Optimal"
# Result from Research: 90% accuracy in real-time monitoring.
Use Case 4: Usage Forecasting (LSTM)
The Problem:Water supply doesn't match demand, leading to wasted pressure or shortages.
The Solution: Predict tomorrow's usage based on last month's data.
LSTMs (Long Short-Term Memory) networks are the gold standard for this. Unlike standard regression, LSTMs have "memory" and can understand sequential dependencies (e.g., higher usage on weekends or during heatwaves).
The Logic: If (Actual - Forecast) > 15% -> Trigger Supply Adjustment
import tensorflow as tf
from tensorflow.keras.layers import LSTM, Dense
# Architecture for Sequence Prediction
model = tf.keras.Sequential([
# Input shape: (Time Steps, Features) e.g., (30 days, 1 feature)
LSTM(50, return_sequences=True, input_shape=(30, 1)),
LSTM(50, return_sequences=False),
Dense(25),
Dense(1) # Predicted usage for next timestamp
])
model.compile(optimizer='adam', loss='mean_squared_error')
# Training with early stopping to prevent overfitting
callback = tf.keras.callbacks.EarlyStopping(monitor='loss', patience=3)
model.fit(X_train, y_train, epochs=50, batch_size=64, callbacks=[callback])
# Result from Research: Alerts generated when usage deviates >15% from norms.
Visualization: The "Control Room"
A model is useless if no one sees the output. In this framework, we use ThingsBoard, an open-source IoT platform, to visualize the JSON payloads sent by our Python scripts.
Sample Alert Payload (JSON) for MQTT:
{
"device_id": "sensor_pump_04",
"timestamp": "2025-11-29T10:00:00Z",
"telemetry": {
"vibration": 4.2,
"pressure": 110
},
"ml_inference": {
"model": "RandomForest_v1",
"risk_score": 0.72,
"status": "CRITICAL"
}
}
The dashboard listens to these topics and updates gauges in real-time.
Conclusion: The Modular Future
By moving from reactive hardware to proactive code, we achieve massive efficiency gains:
- Leak Detection: <1 hour (vs 4-12 hours manually).
- Energy: 25% savings on pumping costs.
- Accuracy: 90% confidence in water potability.
The best part? This stack is modular. You can swap the Random Forest for an XGBoost model, or replace the vibration sensors with acoustic sensors, without rewriting the entire pipeline.
This is how we build Smart Cities not with concrete, but with Code.
[story continues]
tags