Modern distributed systems often face a fundamental challenge, the need for geographic resilience and low latency access, while maintaining transactional consistency and data freshness across globally dispersed data centers. This article explains a sophisticated architectural pattern developed to enable true active-active deployment of a mission critical Oracle based system, which addresses the unique challenges posed by highly distributed data ownership, concurrent multi user mutations, and replication lag variability.
The Problem Space
System Architecture and Constraints
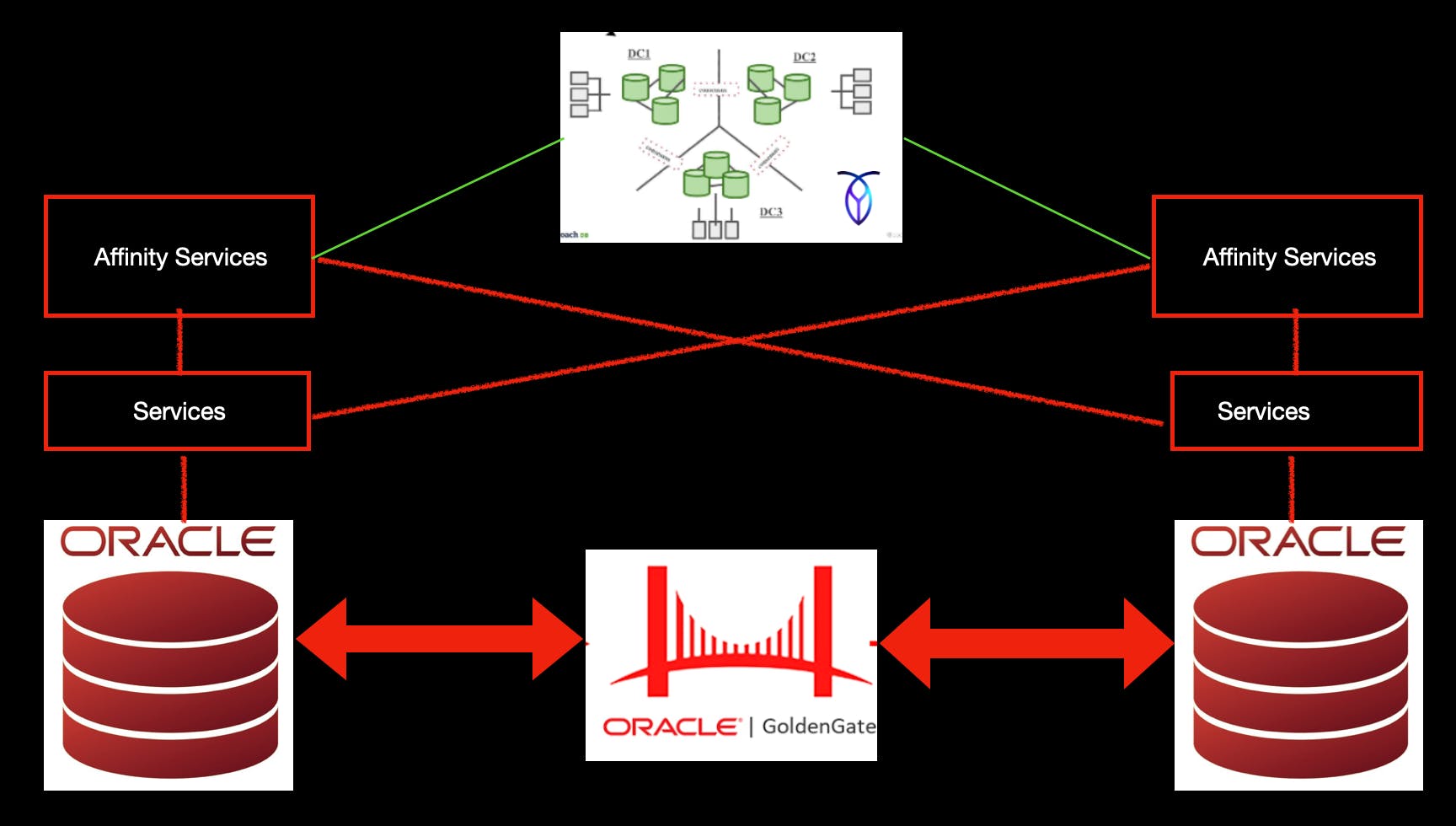
One of our critical system operates with Oracle Database as the primary transactional persistence layer and deployed across two geographically distant data centers with asynchronous replication via Oracle GoldenGate. While this architecture provides high availability and disaster recovery capabilities, but it introduced significant challenges when attempting to achieve true active-active (bidirectional) read-write capability.
The Distributed Data Ownership challange
Three interconnected constraints made this particular problem space uniquely challenging:
1. Highly distributed ownership model : Data records lack clear ownership boundaries. An individual records are authored by one user but accessible by all users globally, at any time. This pattern fundamentally conflicts with traditional sharding strategies that rely on ownership affinity. eg: A record created/updated in west region will be accessed immediately by user in east region based on push notifications.
2. Concurrent mutation contention : The same record undergoes simultaneous read and write operations across multiple distributed clients. This creates inevitable write-write conflicts that demand complex conflict detection and resolution mechanisms. Even after sophisticated CDR, in many cases it ends up in data loss or delayed resolution with manual interventions.
3. Absence of reliable partitioning strategies
- Hash partitioning on entity identifiers offers no natural separation. Data access from remote regions introduces unacceptable latency penalties for ever.
- Any pod based architecture has to contend with network replication delays, which create data staleness issues. Records created in one datacenter are not immediately available to requests served from remote data centers.
- Geographic data distribution across global ownership patterns eliminates viable shard key candidates.
Why Not Adopt Alternative Technologies?
You may now ask, why not other technologies evaluated? The architectural decision to remain within the Oracle ecosystem was driven by constraints like the system's transactional complexity, relational data model dependencies, and years of accumulated application logic rendered technology migration considerably expensive. Which effectively requiring complete system rewrite rather than evolution.
The Solution: Dynamic Affinity Based Routing
After evaluating industry patterns for active-active database systems, we adopted a proven approach, ie introducing an external coordination layer called the Affinity Service. This layer will orchestrate routing decisions based on record level affinity with its origin datacenter.
Core Design Philosophy
The Affinity Service operates as a lightweight, distributed coordinator with two critical responsibilities:
- Track record provenance: Maintain metadata about each record's origin datacenter and mutation timestamp
- Enforce affinity based routing: Route all subsequent read and write operations to the origin datacenter until replication completes and staleness guarantees expire
This pattern ensures:
- Conflict avoidance: Eliminating concurrent mutations by serializing all operations for a given record to its origin datacenter
- Data freshness: At any point in time, users get up-to-date data from it’s origin data center until the replication is complete
Tech Stack: CockroachDB as the Coordination Layer
The Affinity Service required a datastore combining two properties rarely found together:
- Strong consistency : ACID transactions with serializable isolation to maintain correctness under concurrent coordination requests
- Native geographic distribution: Multi region deployment with automatic consensus protocols, enabling the coordination layer itself to be geo-resilient
CockroachDB satisfied both requirements. It provides ACID semantics with Raft based consensus across regions, offering a highly consistent distributed database appropriate for coordination logic. You may wonder doesn’t this additional layer add latency to overall API response time? You are right! But the delay it adds is negligible compared to the power unleashed by making system active-active. Working with CockroachDB cluster itself is a topic for another article(s). One of the related article you can refer to is The Geographic-Imperative: How CockroachdDB Turns Maps into Architecture
Operational Mechanics
The Affinity Service maintains a tuple for each entity:
(entityId, originDatacenter, createdTimestamp, ttl)
Below table describe the event and action taken by affinity service :
|
Event |
Action |
|---|---|
|
Initial Creation |
Insert metadata with TTL = createdTimestamp + (replicationLatency + bufferTime) |
|
Read from Origin data center |
Serve immediately |
|
Read from Remote data center(TTL unexpired) |
Route to origin datacenter to ensure consistency |
|
Read from Remote data center( TTL expired) |
Serve locally |
|
Write Operation(TTL unexpired) |
Route to Origin data center to avid conflict |
|
Write Operation (TTL expired) |
Write to local data center metadata with TTL = updatedTimestamp + (replicationLatency + bufferTime) |
During initial deployment we went with very conservative TTL value ie 5 minutes ( includes typical GoldenGate replication latency of 30- 40 seconds plus substantial buffer time) ensuring high confidence that data has propagated before local data center serving.
The Replication Lag Challange
Our implementation worked seamlessly until operational reality intervened. That is GoldenGate replication channels started showing highly variable latency profiles. Numerous factors induce replication lag within the channels.
- Network infrastructure congestion or degradation between data centers
- Very large transactional batches which exceed the channel throughput capacity
- GoldenGate process restarts or maintenance activities
- Upstream application load surges creating extract / replicat bottlenecks
Our highly conservative static TTL values proved insufficient during elevated lag periods and ended in system unknowingly serving the stale data from remote data center by assuming replication has completed.
Dynamic Lag Observation via GoldenGate Heartbeat Monitoring
The solution to this problem is also residing in Golden Gate metadata infrastructure itself! We tapped into the GG_LAG view.
This view exposes current replication lag (measured in seconds) between local and remote databases, providing near real-time observability into replication channel health.
SELECT LOCAL_DATABASE,OUTGOING_PATH, OUTGOING_LAG FROM GG_LAG;
Self-Healing Adaptive TTL Management
We implemented a self correcting mechanism within the Affinity Service to dynamically adjust TTL values based on observed replication lag.
The Adaptive Algorithm:
-
Every minute query GoldenGate replication channel metadata
- Fetch OUTGOING_PATH and OUTGOING_LAG for all monitored channels
- Identify channels where OUTGOING_LAG > systemDefaultTTL
-
Escalate TTL for new records
-
If OUTGOING_LAG > systemDafultTTL:
- Set effectiveTTL = OUTGOING_LAG + 120 seconds ( buffer for lag fluctuation)
- Apply effectiveTTL for all newly created records
-
This step will ensure the records which are not yet replicated are served from origin data center
-
-
Retroactively update unexpired records
- Scan CockroachDB for all records with ttl > now() (unexpired records)
- Update their TTL to effectiveTTL
- Records created before the lag escalation may have insufficient TTL. So, proactively updatng such records prevents premature local serving of un replicated data.
-
Revert to default TTL when lag normalizes
-
When OUTGOING_LAG < systemDefaultTTL:
- Set effectiveTTL = systemDefaultTTL
-
Optional secondary step to update all unexpired TTL to systemDefaultTTL to leverage geography based routing for already replicated and unmodified records, which will reduce unnecessary affinity lookup remote data center routing.
-
This self healing mechanism provided several desirable outcomes including fully automated ( no human intervention required) handling of maintenance windows and handling the replication degradation gracefully without even support teams noticing.
Deployment Experience
The self-healing adaptive TTL mechanism has proven robust in production across various failure scenarios:
- Oracle database maintenance: Transient replication lag during maintenance is automatically detected and TTL expansion ensures continued consistency. Adjusting the TTL back to normal automatically post-maintenance window.
- Golden Gate channel maintenance: Channel restarts or software updates trigger lag escalation, which the system accommodates transparently.
- Network degradation events: Temporary connectivity issues causing elevated lag are handled without manual involvement.
- Large batch transaction Lag Spikes: High volume transaction periods trigger adaptive TTL expansion, preventing stale data serves
The system has operated without manual TTL tuning intervention for extended periods, demonstrating the viability of adaptive coordination for complex distributed consistency challenges.
Conclusion
Achieving active-active consistency in geographically distributed systems requires moving beyond static architectural patterns toward adaptive, observation driven coordination mechanisms. By adding affinity service and adaptive TTL logic we demonstrate that legacy transactional systems can evolve to meet modern distributed requirements without complete technology replacement. The result is a highly available, consistent, true active-active deployed system that manages its own consistency guarantees and requiring minimal operational overhead.