A Humble Disclaimer
I’m not a machine learning researcher, and I’m definitely not a Rust core contributor. I spend my weekdays writing TypeScript for React frontends and Go for gRPC microservices. My formal ML experience is mostly limited to linear regression, logistic regression, decision trees, and maybe a naive Bayes classifier—the kind of stuff you’d learn in a 10-week bootcamp or an intro university course.
So when I say I “built GPT-2 from scratch,” I don’t mean I invented anything new. What I actually did was implement the GPT-2 architecture from OpenAI’s 2019 paper, using Rust on my Ubuntu desktop, and eventually Candle, after a bit of trial and error—all fueled by curiosity and weekend tinkering.
This isn’t a tutorial for experts. Think of it as a field report from the trenches: my failed first attempt with tch-rs on Linux, why I switched to Candle, and the lessons I picked up along the way.
Why This Project? The Spark Behind the Code
Few weeks ago, I watched Andrej Karpathy’s legendary video, “Let’s build GPT”. For 90 minutes, he coded a working GPT in Python, explaining every line with calm clarity. At the end, his model generated Shakespearean prose from scratch.
I was mesmerized but also frustrated.
Because while I understood the concepts - embeddings, attention, feed-forward networks, I had never felt them. In my day job, I use APIs and get results. It’s powerful, but it’s passive.
I wanted to build, not just consume.
And since I’ve been slowly learning Rust in my spare time - not because I need it, but because I love its rigor - I asked a dangerous question:
“What if I tried to build GPT-2… in Rust?”
Not for performance. Not for production.Just to see if I could.
The Tools: My Journey from tch-rs to Candle (on Ubuntu)
When I first started, I reached for what seemed like the obvious choice: tch-rs, the official Rust bindings to PyTorch.
After all, PyTorch powers most modern ML research. If I used tch-rs, I’d get:
- Battle-tested tensor ops
- GPU support (in theory)
- Autograd that “just works”
- Familiar APIs if I ever read PyTorch code
So I dove in—on my Ubuntu 22.04 computer, with a RTX 5060ti and Ryzen 5
The tch-rs Phase: Fighting CUDA, Not Models
I started with tch-rs, but ran into a wall:
- It ships with precompiled libtorch tied to a specific PyTorch / CUDA combo.
- My system (CUDA 12.8) didn’t match the expected version.
- The "fix"? Setting obscure env vars like
LIBTORCH_BYPASS_VERSION_CHECK=1and living with deprecation warnings. (Btw, this didn't fixed the problem)
So instead of training GPT-2, I was debugging library mismatches and praying that my build would finally run.
The Switch to Candle: Pure Rust, Zero Friction
Then I tried Candle (pure Rust, Hugging Face). The difference was night and day:
- No libtorch, no CUDA mismatch: just
cargo add candle-core candle-nn. - Readable Rust source: I could actually inspect
matmulorsoftmaxin minutes. - Learning-first: enough to build GPT-2 without PyTorch baggage.
- Cross-platform: Ubuntu, macOS, Windows—no setup headaches.
With tch-rs, I was debugging linker errors.With Candle, I debugged attention masks—the real problem I wanted to solve.
A compact blueprint: GPT‑2 as a stack of clear responsibilities
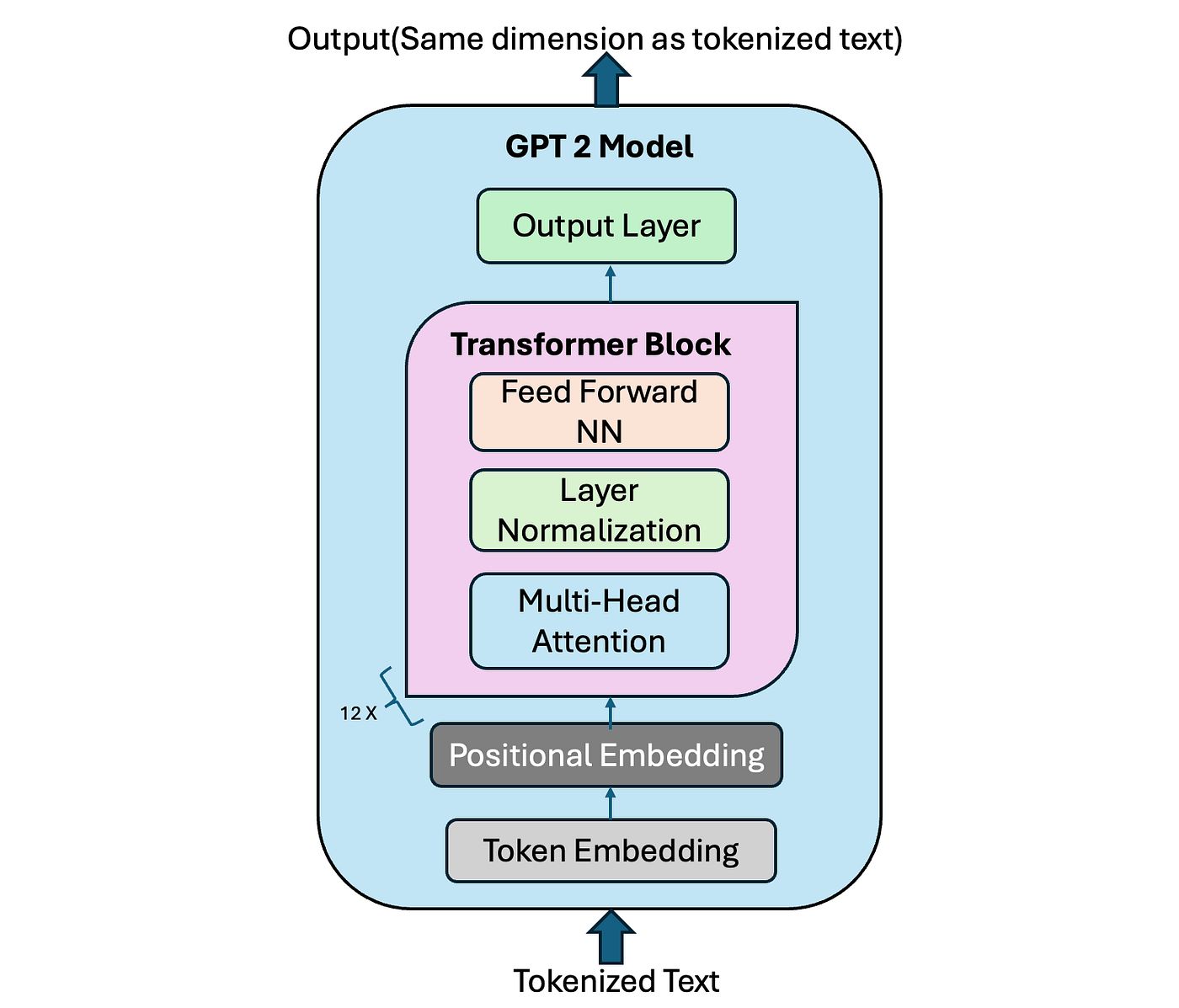
GPT‑2 is an orchestration of these parts:
- Tokenization → discrete IDs
- Token + Positional Embeddings → geometry
- LayerNorm → stabilize activations
- Masked Multi‑Head Self‑Attention → weighted memory
- Residual connections → gradient highways
- Position‑wise Feed‑Forward → per‑token processing
- Dropout → regularization
- Output head / projection → logits over vocabulary
Below I show why each is there and include the relevant snippets from your gpt.rs to make the mapping explicit.
Tokenization - the first translation
Why tokenization exists:Language is continuous; computers need discrete symbols. Tokenization breaks text into subword units that balance vocabulary size, coverage, and generalization.
Example usage:
let tokenizer = get_bpe_from_model("gpt2")?;
let encoded = tokenizer.encode_with_special_tokens("Hello, I am"); // -> [15496, 11, 314, 257]
These IDs are the indices the embedding layer maps into vectors.
Embeddings — where symbols become vectors
Why it exists: Token IDs are discrete points; embeddings map them into a dense, continuous vector space where relationships become geometric (similar words → nearby vectors). GPT‑2 uses both token embeddings and learned positional embeddings (added to token embeddings).
Key excerpt (from gpt.rs forward pass):
let token_emb = self.token_emb.forward(xs)?; // [batch, seq, emb_dim]
let pos_ids = Tensor::arange(0, seq_len as u32, xs.device())?;
let pos_embed = self.pos_emb.embeddings().index_select(&pos_ids, 0)?;
let mut x = token_emb.broadcast_add(&pos_embed)?;
x = self.dropout.forward(&x, train)?;
Why positional embeddings? Transformers are permutation‑invariant; positional embeddings inject order information so the model knows where a token sits in the sequence.
Layer Normalization - the silent stabilizer
Why it exists: LayerNorm keeps each token's activations well‑scaled and centered across the embedding dimension so deep stacks don't blow up or collapse. It's applied per token (not per batch), which suits variable sequence lengths.
Implementation (from gpt.rs):
impl Module for LayerNorm {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
let mean = xs.mean_keepdim(D::Minus1)?;
let variance = xs.var_keepdim(D::Minus1)?;
// prevent division by zero
let eps = Tensor::new(&[self.eps], xs.device())?;
// (x - mean) / (var + epsilon)
let dividend = xs.broadcast_sub(&mean)?;
let divisor = variance.broadcast_add(&eps)?;
let divisor_sqrt = divisor.sqrt()?;
let normed = dividend.broadcast_div(&divisor_sqrt)?;
let scaled_shifted = normed
.broadcast_mul(&self.scale)?
.broadcast_add(&self.shift)?;
Ok(scaled_shifted)
}
}
Practical note: Without LayerNorm the model’s loss quickly explodes. It's conceptually similar to feature standardization in classical ML but applied repeatedly inside the network to internal representations.
Masked Multi‑Head Self‑Attention — the engine of context
Why masked attention exists:To predict the next word, the model must attend only to what came before. Masked attention enforces causality—so the model never cheats by peeking at the future.
Key steps (and why):
- Project input into queries (Q), keys (K), values (V).
- Split into
num_headsand compute scaled dot‑products:Q · Kᵀ / √d_k. Scaling prevents softmax saturation. - Apply a causal mask (set future positions to −∞) so attention can't peek forward.
- Softmax → attention weights → weighted sum with V.
- Reassemble heads, linear projection.
Implementation (abridged from gpt.rs):
pub fn forward(&self, xs: &Tensor, train: bool) -> Result<Tensor> {
let (b, num_tokens, _d_in) = xs.dims3()?;
let query = self.w_query.forward_t(xs, train)?;
let key = self.w_key.forward_t(xs, train)?;
let values = self.w_value.forward_t(xs, train)?;
// Split matrices into multiple heads
let query = query
.reshape((b, num_tokens, self.num_heads, self.head_dim))?
.transpose(1, 2)?
.contiguous()?;
let key = key
.reshape((b, num_tokens, self.num_heads, self.head_dim))?
.transpose(1, 2)?
.contiguous()?;
// (values reshape is similar)
let values = values
.reshape((b, num_tokens, self.num_heads, self.head_dim))?
.transpose(1, 2)?
.contiguous()?;
let key_t = &key.transpose(D::Minus2, D::Minus1)?;
let attention_scores = query.matmul(key_t)?;
let mask = get_mask(num_tokens, xs.device())?;
let masked_tensor = masked_fill(
&attention_scores,
&mask.broadcast_left((b, self.num_heads)).unwrap(),
f32::NEG_INFINITY,
)?;
let mut attention_weights = softmax(&(masked_tensor * self.scaling)?, D::Minus1)?;
attention_weights = self.dropout.forward(&attention_weights, train)?;
let context_vec = attention_weights
.matmul(&values)?
.transpose(1, 2)?
.reshape((b, num_tokens, self.dim_out))?
.contiguous()?;
self.out_proj.forward_t(&context_vec, train)
}
Gotcha story: when the mask ate my tokens
I once wired up the causal mask and thought, *“Okay, that’s the easy part.”*Slap on a triangular mask, stop the model from cheating, move on.
Except during training, something weird happened. Every next-token prediction came back as nothing. Empty strings. Just zeroes. It was like the model had been lobotomized overnight.
I dug through the code thinking maybe my embeddings were broken, maybe gradients were exploding. Nope. The real culprit? The mask.
I had accidentally broadcast it across all positions instead of just the “future” ones. Which meant the model wasn’t just blind to tomorrow’s tokens—it was blind to everything. Every attention score got nuked to -∞, the softmax collapsed into uniform noise, and poof: the model literally had no past to attend to.
Lesson learned: when you implement masked attention, don’t just trust the math, print your mask. For a sequence of 5 tokens, you should see a neat little lower-triangular staircase. If you see a solid wall instead, congratulations: you’ve just silenced your entire model.
Feed‑Forward Network (position‑wise) - per‑token processing
Why it exists: Attention mixes information across tokens; the feed‑forward network processes each token independently with a non‑linear transformation. In GPT‑2 it's typically a 4× expansion (e.g., 768 → 3072 → 768) with GeLU activation.
Implementation (from gpt.rs):
impl Module for FeedForward {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
let xs = self.top.forward(xs)?;
let xs = GELU.forward(&xs)?;
let xs = self.bottom.forward(&xs)?;
Ok(xs)
}
}
💡 Why GeLU? It’s smoother than ReLU, which helps with gradient flow in deep networks. The approximation avoids expensive error functions—perfect for Rust’s no_std-friendly ethos.
💡 Insight: This layer is where much of the model’s computation happens. Attention decides what to attend to; the feed-forward network decides what to do with it.
Residual connections — the gradient highway
Why it exists: Deep stacks can suffer vanishing gradients. Residuals (x + f(x)) create shortcut paths that allow gradients to flow directly from later layers to earlier ones, enabling much deeper models to train reliably.
Implementation (transformer block forward):
impl ModuleT for TransformerBlock {
fn forward_t(&self, xs: &Tensor, train: bool) -> Result<Tensor> {
let shortcut = xs.clone();
let mut x = xs.to_owned();
x = self.layer_norm1.forward(&x)?;
x = self.mha.forward(&x, train)?;
x = self.dropout.forward(&x, train)?;
x = (x + shortcut)?;
let shortcut = x.clone();
x = self.layer_norm2.forward(&x)?;
x = self.ff.forward(&x)?;
x = self.dropout.forward(&x, train)?;
x = (x + shortcut)?;
Ok(x)
}
}
Design note: Residuals pair with LayerNorm and dropout. The order (norm → block → dropout → add shortcut) is important and implemented here to match standard transformer variants.
💡 Rust nuance: The + operator in Candle is overloaded for tensors, but it requires identical shapes. One off-by-one in sequence length, and your shortcut becomes a crash site.
Output head & generation — closing the loop
Why it exists: After final normalization, the model must map hidden vectors to logits over the vocabulary. Many implementations tie the output weights with token embeddings; your implementation leaves the projection as a separate Linear for flexibility.
GPT forward (embeddings → transformer → final norm → projection):
impl ModuleT for GPTModel {
fn forward_t(&self, xs: &Tensor, train: bool) -> Result<Tensor> {
let (_batch_size, seq_len) = xs.dims2()?;
let token_emb = self.token_emb.forward(xs)?;
let pos_ids = Tensor::arange(0, seq_len as u32, xs.device())?;
let pos_embed = self.pos_emb.embeddings().index_select(&pos_ids, 0)?;
let mut x = token_emb.broadcast_add(&pos_embed)?;
x = self.dropout.forward(&x, train)?;
x = self.transformer_blocks.forward_t(&x, train)?;
x = self.final_layer_norm.forward(&x)?;
let result = self.linear_output_layer.forward(&x)?;
Ok(result)
}
}
Text Generation
The example sticks to greedy decoding (taking the argmax at each step). For richer and more varied text generation, techniques like sampling, top-k, or nucleus (top-p) sampling are usually preferred in real applications. I left those out here since this was meant to stay a small weekend project, and diving into decoding strategies felt like it would stretch the scope too far.
pub fn generate_text_simple<M: GPT + ModuleT>(
model: &M,
mut tokens: Tensor, // the "story so far" (starting sequence of token IDs)
max_new_tokens: usize, // how many more words we want to add
context_size: usize, // how much memory the model has (how many words it can "see")
) -> Result<Tensor> {
// We will add words one by one until we reach max_new_tokens
for _ in 0..max_new_tokens {
// Find out how many words we already have
let (_batch, seq_len) = tokens.dims2()?;
// The model can only remember `context_size` words at a time,
// so if our story is longer, we cut it to just the recent part.
let start = seq_len.saturating_sub(context_size);
let context = tokens.i((.., start..seq_len))?;
// Ask the model: "What do you think comes next after this context?"
// The model replies with scores (logits) for every word in its dictionary.
let logits = model.forward_t(&context, false)?;
// We only care about the scores for the very last word position,
// because that's where the model guesses the "next" word.
let (_batch, seq_len, _vocab) = logits.dims3()?;
let last_logits = logits.i((.., seq_len - 1, ..))?;
// Turn those scores into probabilities (like dice odds).
// Example: word A = 80% chance, word B = 15%, word C = 5%.
let probs = softmax(&last_logits, 1)?;
// Pick the most likely word (greedy = always choose the biggest number).
// This makes the story very predictable, like always choosing
// vanilla ice cream instead of trying new flavors.
let next_token = probs.argmax_keepdim(D::Minus1)?;
// Stick that new word onto the end of our story.
tokens = Tensor::cat(&[&tokens, &next_token], D::Minus1)?;
}
// When we're done, return the whole story (original + new words).
Ok(tokens)
}
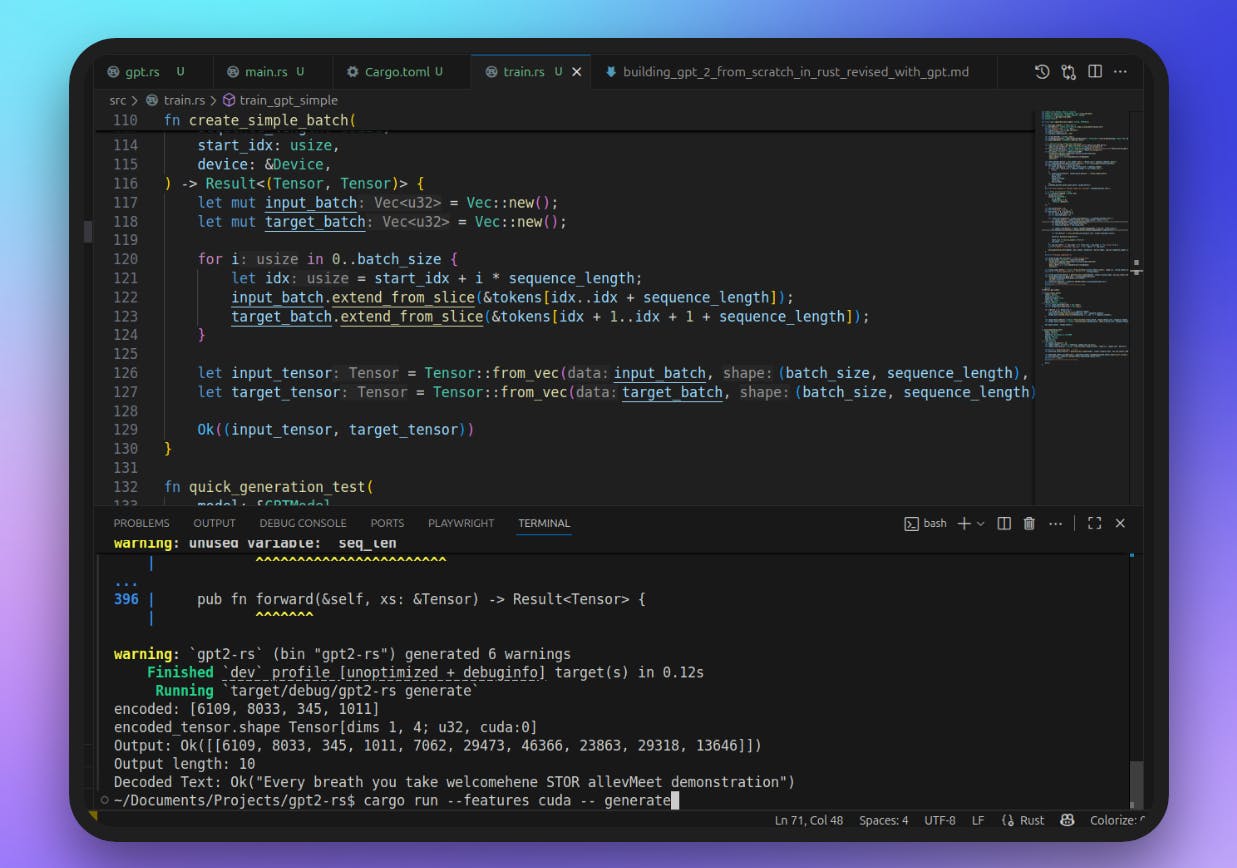
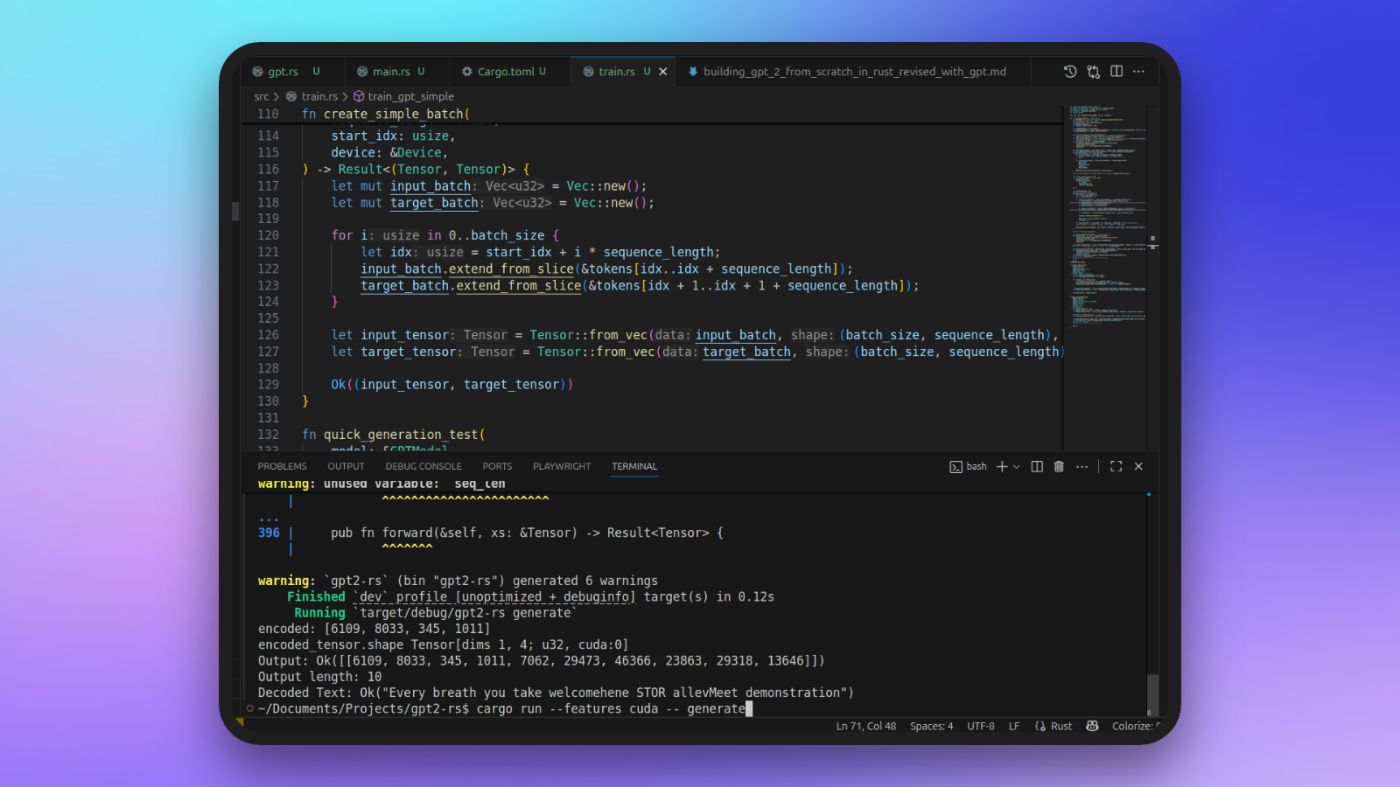
Training
Once the model was built, I moved on to training — and honestly, this was where things started to feel tough. Not because the code was complicated (most of it was just setting up batches, feeding them through the model, and applying AdamW), but because training is a totally different beast compared to writing code.
And here’s me being fully honest: I didn’t hand-craft the training loop myself. I GPT-ed most of it. It was faster, and honestly, I wasn’t here to reinvent the wheel. I just wanted something that worked so I could see my model actually train. The point of this project (for me) wasn’t to become a production-ready model, it was to understand GPT-2 better.
Video:
https://marbelona.com/static/images/gpt2-from-scratch-rust-transformers/gpt2train.mp4?embedable=true
🔑 What the Training Loop Does (in plain terms)
Here’s the heart of the training code, stripped down to the essentials:
for (input_batch, target_batch) in prebaked_batches.iter() {
// 1. Forward pass — get model predictions (logits)
let logits = model.forward_t(input_batch, true)?;
// 2. Flatten predictions and targets for cross-entropy
let logits_flat = logits.reshape((batch_size * seq_len, vocab_size))?;
let targets_flat = target_batch.reshape((batch_size * seq_len,))?;
// 3. Compute loss
let loss = cross_entropy(&logits_flat, &targets_flat)?;
// 4. Backpropagation + optimizer step
optimizer.backward_step(&loss)?;
}
Forward pass: run input tokens through the model.
Reshape: make tensors fit the loss function.
Loss: measure how wrong the predictions were.
Backprop + optimizer: adjust weights to improve next time.
That’s training in a nutshell. GPT helped me scaffold this loop, but I still had to wrestle with the details (tensor shapes, batching, optimizer parameters).
I didn’t spend weeks fine-tuning or pushing it to convergence — this was meant to be a weekend project after all. So the training I ran was short, the loss didn’t drop much, and the generations that came out of it were basically trash. But that was expected. I wasn’t aiming for SOTA performance, just the satisfaction of seeing the whole pipeline run end-to-end.
Here’s a real example of what my “trained” model produced after just a little bit of training:
What This Taught Me - Beyond the Code
1. Tooling matters.
Pure‑Rust Candle removed the build friction from Ubuntu and let you focus on model bugs (masks, shapes, scaling).
2. Deep learning builds on classical ML
- Overfitting → Dropout
- Feature scaling → LayerNorm
- Sequential prediction → Autoregressive generation
- Ensemble refinement → Residual connections
The math is more complex, but the principles are the same.
3. Rust rewards patience
- The borrow checker forced me to think deeply about data ownership.
Resulttypes made errors explicit - no silent NaNs.cargo clippycaught performance anti-patterns early.
It’s frustrating at first—but once you “get” it, you write safer, clearer code.
4. Understanding comes from doing
I’d read about attention a dozen times. But only when I forgot the causal mask and saw the model break did I truly understand its purpose.
5. You don’t need to be an expert to learn deeply
Curiosity, time, and a willingness to fail are enough—even on a standard Ubuntu setup with mismatched CUDA.
Final Reflections: Why This Matters
I’ll go back to writing TypeScript tomorrow. I’ll debug Go race conditions and argue about React state management. And that’s okay, those are the skills that pay the bills.
But now, when someone says “GPT-2,” I don’t see a black box.I see:
- A tokenizer slicing “Hello” into
15496 - Embeddings placing it in 768D space
- 12 attention heads whispering about context
- LayerNorm keeping activations sane
- Residual connections carrying gradients home
- GeLU curves adding non-linearity
- All of it compiled, safe, and running in Rust on Ubuntu, with no CUDA drama
And that’s why I did this. Not to build the next AI but to understand the one we already have.
The next steps for this would just probably me learning how to load the official trained weights instead of me training it on a consumer grade machine, 'cause obviously that's kinda dumb to do. Also want to learn how to fine-tuning works, adapter tuning to be exact, so that's on the list.
Resources
LLM From Scratch Github Repo This served as my main code reference on dissecting how to implement a GPT model from the ground up.
https://github.com/rasbt/LLMs-from-scratch
Andrej Karpathy - GPT2
https://www.youtube.com/watch?v=l8pRSuU81PU&pp=ygUUYW5kcmVqIGthcnBhdGh5IGdwdDI%3D
Repository Link for this GPT2 Clone
[story continues]
tags