
This article presents the design and implementation of a modular command-line interface (CLI) AI agent for speech-to-text workflows, combining real-time audio recording with AI-powered transcription and intelligent content summarization. The system demonstrates a layered architecture approach that separates audio capture, processing, and natural language understanding into distinct, interoperable components. The analysis focused on three primary areas: modular component design, cross-platform compatibility mechanisms, and integration patterns between local and remote processing services. Through examination of implementation patterns and performance characteristics, we show how modular design principles can improve maintainability, cross-platform compatibility, and extensibility in speech processing applications. Our findings indicate that well-structured abstraction layers can reduce integration complexity while maintaining processing efficiency and system reliability.
Introduction
Speech-to-text technology has become foundational to modern computing applications, from voice assistants to meeting transcription services. However, most implementations either prioritize ease of use at the expense of customization, or offer extensive configurability while requiring substantial development effort. The challenge lies in creating systems that balance simplicity, customization, and performance through modular design.
This article examines a CLI-based AI agent that addresses these competing requirements through a modular architecture. The system combines several key technologies: cross-platform audio recording through system utilities, AI-powered speech recognition via OpenAI's Whisper model, and intelligent content summarization using large language models. By analyzing the implementation patterns and architectural decisions, we provide insights into designing maintainable speech processing workflows.
The primary contribution of this work is demonstrating how abstraction layers can isolate platform-specific complexity while preserving system performance and extensibility. We focus on three key areas: the recording subsystem's modular design, the session management approach for handling multiple independent recording workflows, and the integration patterns between local processing and remote API services.
Modern speech processing applications often struggle with platform fragmentation, where different operating systems require distinct audio capture mechanisms. Our analysis shows how a unified interface can abstract these differences while maintaining native performance characteristics. Additionally, we examine how session-based file management can improve workflow organization and enable batch processing scenarios.
Beyond technical considerations, this CLI AI agent addresses a growing need for accessible voice-driven knowledge capture tools. In an era where information overload challenges professionals, students, and researchers alike, the ability to quickly verbalize thoughts and receive structured, summarized output represents a significant productivity enhancement. The system transforms the simple act of speaking into a powerful workflow for organizing and analyzing personal or professional information.
Problem Statement
Traditional speech-to-text implementations face several architectural challenges that limit their practical applicability. First, audio recording mechanisms vary significantly across operating systems, requiring platform-specific code that complicates maintenance and testing. Linux systems typically use ALSA interfaces, macOS relies on Core Audio frameworks, and Windows employs DirectSound or WASAPI. This fragmentation forces developers to either limit platform support or maintain multiple codebases.
Second, most existing solutions tightly couple audio capture with transcription processing, making it difficult to modify recording parameters, switch between different speech recognition services, or add processing steps like noise reduction or speaker identification. This coupling reduces system flexibility and complicates debugging when issues arise in specific pipeline stages.
Third, workflow management in speech processing applications often lacks structure for handling multiple independent recording sessions, organizing output files, or implementing batch processing scenarios. By concurrent sessions, we mean the ability to start new recording workflows while previous recordings are still being processed or stored, preventing file conflicts and maintaining organized output. Users frequently need to manually manage file organization, track processing status, and coordinate between different processing steps.
The gap this paper addresses is the lack of documented architectural patterns for building modular speech processing systems that maintain simplicity while providing extensibility. While academic literature covers speech recognition algorithms extensively, there is limited guidance on system architecture for practical applications that need to integrate multiple technologies and handle real-world operational requirements.
Our approach demonstrates how careful abstraction layer design can resolve these challenges without sacrificing performance or introducing unnecessary complexity. By examining a working implementation, we provide concrete examples of how modular patterns apply to speech processing workflows and identify key design decisions that affect system maintainability and extensibility.
3. Research
Methodology
We analyzed the architecture and implementation patterns of a TypeScript-based CLI AI agent designed for speech-to-text workflows.
The codebase examination involved tracing data flow through the system architecture, identifying abstraction boundaries, and measuring coupling between components. We evaluated the recording subsystem's extensibility by examining how new recorder implementations can be added without modifying existing code. For the transcription pipeline, we analyzed the separation between audio processing and natural language understanding components.
Performance analysis focused on resource utilization patterns during audio recording, file I/O operations, and API communication. We examined memory usage characteristics of the streaming audio processing and evaluated the efficiency of the session-based file management approach.
Architecture Analysis
The system implements a four-layer architecture that separates concerns while maintaining clear data flow paths. Figure 1 illustrates the overall system structure and component relationships.
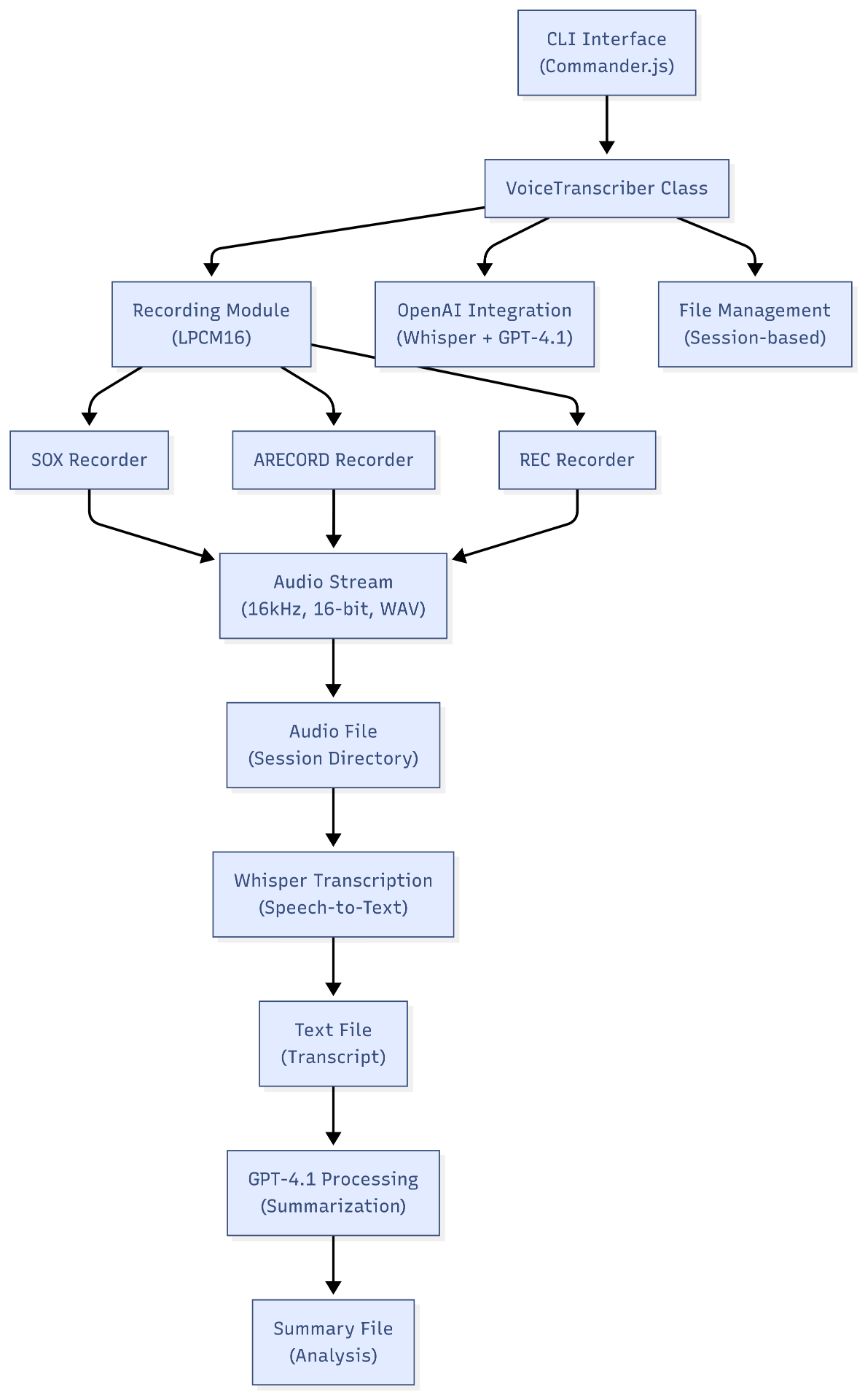
Figure 1: System Architecture Overview
The foundation layer consists of platform-specific recording utilities (SOX, ARECORD, REC) that handle actual audio capture. The SOX recorder provides cross-platform compatibility through a unified command-line interface, while ARECORD and REC offer platform-optimized implementations for Linux and macOS respectively.
The abstraction layer contains the Recording class, which implements the Facade pattern to provide a unified interface to all recorder implementations. This layer handles process lifecycle management, stream processing, and error propagation. By isolating platform differences at this boundary, higher-level components can operate without platform-specific knowledge.
The application layer includes the VoiceTranscriber class and CLI command interface. This layer manages session state, coordinates processing workflows, and handles user interactions. The VoiceTranscriber class maintains recording configuration, output file organization, and processing pipeline coordination.
The processing layer integrates with external AI services for speech recognition and natural language understanding. OpenAI's Whisper model handles AI-powered speech-to-text conversion, while GPT-4.1 provides intelligent content summarization and analysis capabilities.
Data Flow and Processing Pipeline
Figure 2 demonstrates the complete processing workflow from audio capture through final output generation.

Figure 2: Processing Workflow Sequence
The workflow begins when users initiate recording through the CLI interface. The VoiceTranscriber creates a Recording instance with specified configuration parameters, which spawns the appropriate system process for audio capture. Audio data streams continuously from the recorder process through Node.js streams to the output file.
When users terminate recording, the system gracefully shuts down the recording process and waits for file completion. The transcription phase sends the audio file to OpenAI's Whisper API and receives text output. Finally, the summarization phase processes the transcript through GPT-4.1 to generate structured analysis.
Error handling occurs at multiple levels, with the Recording class managing process-related errors, the VoiceTranscriber handling API communication issues, and the CLI interface providing user-friendly error messages. This layered approach ensures that errors are handled at the appropriate abstraction level.
Component Modularity Assessment
The modular design enables independent component evolution and testing. Figure 3 illustrates the layered architecture that enables modular component organization.
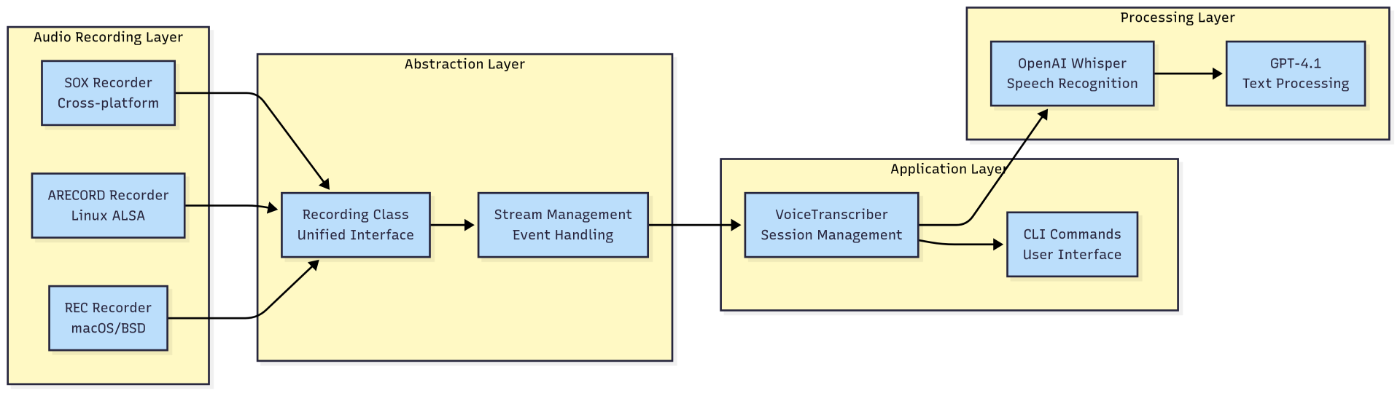
Figure 3: Modular Component Architecture
Table 1 summarizes the coupling characteristics between major system components.
|
Component Pair |
Coupling Type |
Dependency Direction |
Extensibility Impact |
|---|---|---|---|
|
CLI <> VoiceTranscriber |
Interface |
CLI depends on VoiceTranscriber |
Low - interface-based |
|
VoiceTranscriber <> Recording |
Composition |
VoiceTranscriber creates Recording |
Medium - creation dependency |
|
Recording <> Recorders |
Strategy Pattern |
Recording selects recorder |
Low - factory pattern |
|
VoiceTranscriber <> OpenAI |
Service |
VoiceTranscriber calls API |
Low - external service |
|
Recording <> System Process |
Process Control |
Recording manages process |
High - system dependency |
The Recording class demonstrates effective use of the Strategy pattern, allowing new recorder implementations without modifying existing code. Adding support for additional audio capture utilities requires only implementing the RecorderResult interface and updating the recorder selection logic.
Performance Characteristics
Resource utilization analysis reveals efficient memory and processing patterns. Audio streaming through Node.js maintains constant memory usage regardless of recording duration, as data flows directly from the system process to file output without intermediate buffering.
The session-based file organization improves workflow management by creating timestamped directories for each recording session. This approach prevents file conflicts in concurrent usage scenarios and simplifies batch processing operations.
API communication patterns show appropriate error handling and retry logic, though the current implementation uses synchronous processing for transcription and summarization. Future optimizations could implement parallel processing for multiple audio files or streaming transcription for real-time applications.
4. Code Examples
The following code examples illustrate key architectural patterns and implementation techniques used in the modular speech-to-text system.
Recording Abstraction Layer
The Recording class demonstrates how to abstract platform-specific audio capture while maintaining type safety and error handling:

This pattern separates recorder selection from process management, enabling easy addition of new audio capture implementations. The getRecorderCommand() method serves as a factory that returns standardized command configuration regardless of the underlying recorder.
Strategy Pattern for Audio Recorders
The SOX recorder implementation shows how platform-specific logic can be encapsulated while providing a consistent interface:
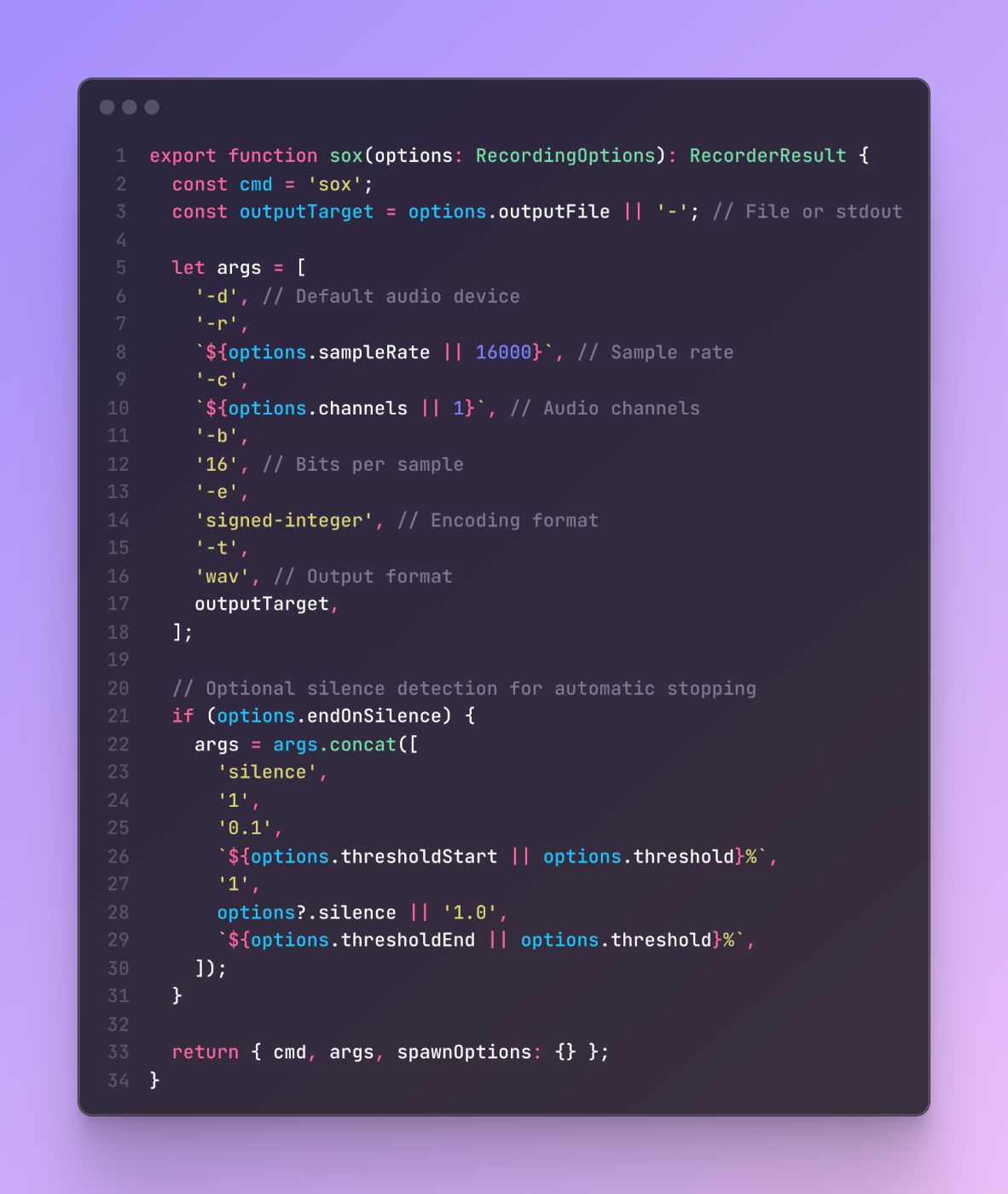
This implementation demonstrates how complex audio processing parameters can be configured through a simple options interface while maintaining compatibility with the underlying system utility.
Session Management and Workflow Coordination
The VoiceTranscriber class shows how to coordinate multiple processing steps while maintaining clean separation of concerns:

The session-based approach prevents file conflicts and provides clear organization for batch processing scenarios. Each recording session creates an isolated directory with consistent file naming conventions.
API Integration Pattern
The transcription method demonstrates effective integration with external services while maintaining error handling and type safety:
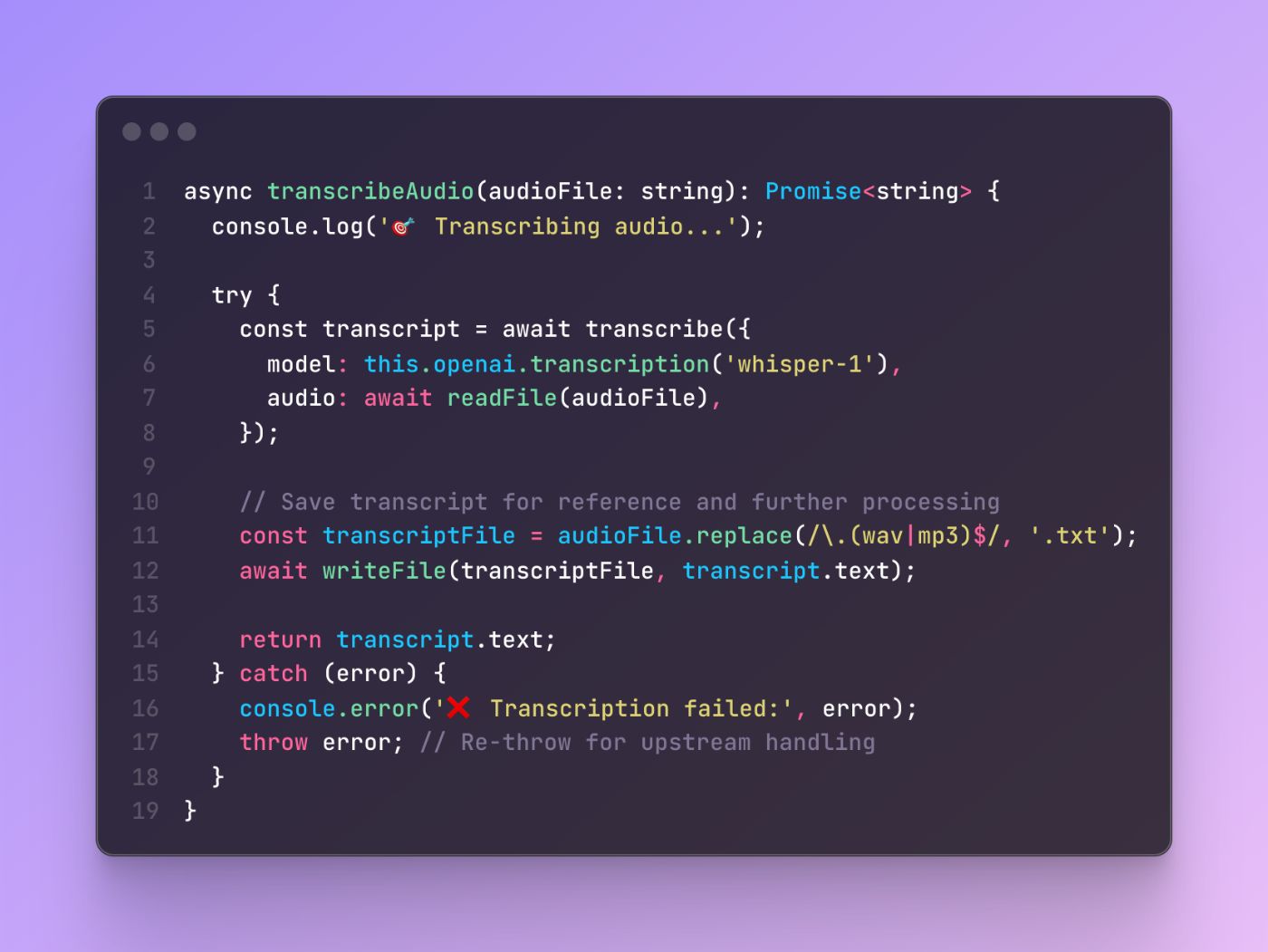
This pattern shows how to integrate with external APIs while providing appropriate error handling and local file management. The method maintains single responsibility by focusing only on transcription while delegating file organization to the session management layer.
5. Conclusion
This analysis demonstrates that modular architecture principles can effectively address the complexity challenges inherent in speech-to-text workflows. The examined CLI AI agent successfully separates platform-specific audio capture from application logic, enabling cross-platform compatibility without sacrificing performance or maintainability.
The key architectural insights include the effectiveness of abstraction layers for isolating system dependencies, the value of strategy patterns for handling platform variations, and the importance of session-based organization for workflow management. The Recording class abstraction proves particularly valuable, allowing the system to support multiple audio capture mechanisms through a unified interface.
The integration patterns between local processing and remote API services provide a template for building applications that combine edge computing with cloud-based artificial intelligence services. The error handling strategies and resource management approaches ensure robust operation in production environments.
However, several limitations warrant consideration. The current implementation processes audio files sequentially, which may not meet performance requirements for high-throughput scenarios. The system dependencies on external audio utilities could complicate deployment in containerized environments. Additionally, the reliance on cloud-based APIs introduces latency and availability considerations for real-time applications.
Practical applications of this architecture extend beyond speech-to-text workflows. The CLI AI agent proves particularly valuable in everyday scenarios where users need to quickly capture, organize, and analyze spoken information. For instance, professionals can use the system to record and automatically summarize meeting notes, researchers can capture interview insights with structured analysis, and students can convert lectures into organized study materials. The voice-driven interface eliminates the friction of manual note-taking, allowing users to simply speak their thoughts, ideas, or observations and receive both accurate transcriptions and intelligent summaries.
The session-based organization makes the system especially useful for personal knowledge management, where users can build a searchable archive of their spoken thoughts and ideas over time. Each recording session creates a timestamped, categorized collection of both raw transcripts and AI-generated summaries, enabling users to review and reference their verbal notes efficiently. This approach transforms the CLI from a simple transcription tool into a comprehensive AI-powered personal assistant for memory augmentation and information processing.
The modular patterns also apply to any system requiring integration between local resources and cloud services, particularly in scenarios involving multimedia processing, data pipeline orchestration, or hybrid computing architectures.
Future research directions include investigating streaming transcription approaches for real-time applications, implementing distributed processing capabilities for handling multiple concurrent sessions, and exploring integration with on-device speech recognition models to reduce cloud dependency. Additionally, extending the recorder abstraction to support advanced audio processing features like noise reduction, speaker separation, and acoustic environment adaptation could enhance the system's applicability to challenging recording environments.
The architecture analysis reveals that thoughtful abstraction layer design can resolve the tension between system simplicity and extensibility. By examining practical implementation patterns, this work provides concrete guidance for building maintainable speech processing applications that can evolve with changing requirements and technological advances.
The session management approach proves particularly valuable for organizational workflows where audio processing is part of larger document management or content creation pipelines. The clear separation between recording, transcription, and summarization stages enables flexible workflow customization and facilitates integration with existing business processes.
This research contributes to the broader understanding of how modular design principles apply to applications that bridge local system resources and cloud-based artificial intelligence services, providing a foundation for future developments in hybrid computing architectures for multimedia processing applications.
[story continues]
tags