RAG is everywhere—and that’s not surprising. It’s one of the most practical ways to make large document collections queryable without building brittle, domain-specific parsers for every question type. The catch is that what works in a controlled demo often degrades quickly when you put it in front of real enterprise PDFs: scanned contracts, compliance filings, medical records, policies, and the long tail of layout and quality issues that come with them. In production, the “RAG problem” is less about clever prompting and more about repeatability: traceability, security, quality controls, and the ability to explain why an answer is correct (or why the system refused).
When teams get stuck, it’s rarely because vector search “doesn’t work.” It’s because the system can’t consistently ground answers to the right evidence, can’t enforce entitlements reliably, or can’t be evaluated and improved without breaking things. If you can’t tell a stakeholder which version of which document supported a claim—or prove the user was authorized to see it—you don’t have a product yet. You have an experiment.
The Demo Trap
Most prototypes follow the same path: drop documents into a vector store, retrieve top-k chunks, and ask an LLM to synthesize. On clean, well-structured text, that can look excellent. The issue is what happens next. Scanned PDFs come in rotated or skewed. Multi-column reading order gets scrambled. Tables lose structure during extraction. Chunking splits mid-argument. Retrieval returns “close enough” context that reads plausibly but doesn’t actually support the claim. And the model, doing what it’s optimized to do, answers fluently anyway.
In production, you’re optimizing for different properties than a demo. You want the system to be reliable over messy inputs, reproducible across pipeline changes, and defensible under scrutiny. That means being able to trace an answer back to specific evidence, and having strong defaults when evidence is weak: clarifying questions, refusal behavior, or presenting “best available evidence” with explicit uncertainty. It also means treating access control as part of retrieval—not as an afterthought layered onto UI.
Ingestion: Where Quality Is Won or Lost
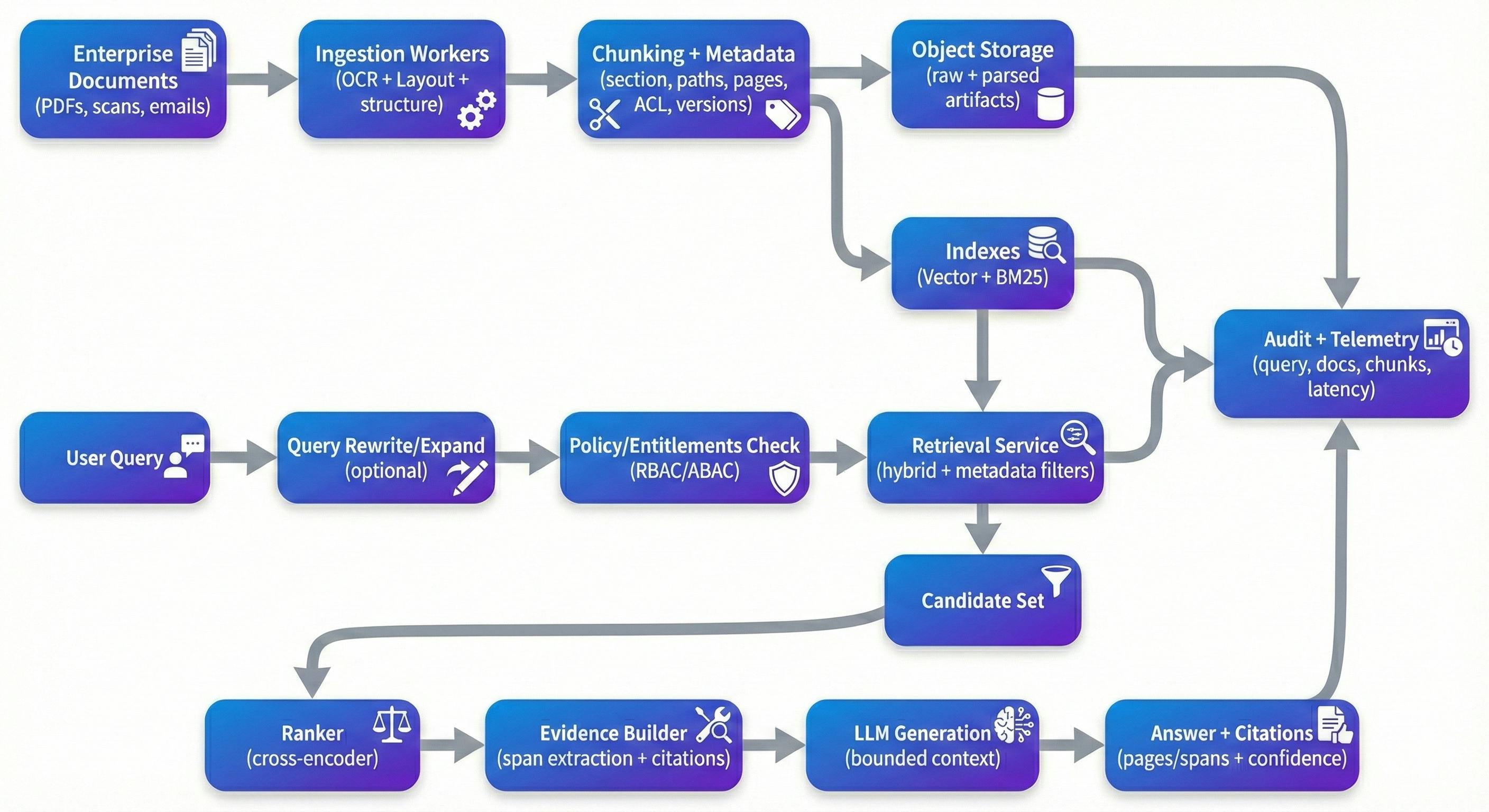
If you’ve built a few of these systems, you learn quickly that ingestion determines retrieval quality more than most downstream tricks. Document AI preprocessing isn’t glamorous, but it is where you either preserve structure—or lose it permanently. For enterprise documents, OCR alone isn’t enough; you typically need OCR with layout detection, reading-order reconstruction, and structure extraction that keeps headings, sections, and tables meaningful. Managed tools like Google Document AI, Azure Document Intelligence, and Amazon Textract can cover a lot of ground. Open-source pipelines like Unstructured and GROBID are common when you need transparency or tighter control over parsing decisions.
Chunking is where teams often underestimate the complexity. A simple character or token split is fast, but it tends to cut across semantic boundaries—exactly the boundaries users care about in contracts and policies. Adaptive chunking that follows headings, section boundaries, and table boundaries usually improves both retrieval and downstream grounding. It also makes provenance feel natural to the end user: instead of surfacing an opaque internal ID like chunk_4892, you can point to something a reviewer can immediately verify—“MSA v3.2 → Section 9 (Termination) → 9.2 (Termination for Cause), page 12, lines 14–22.”
Metadata is another area that tends to look optional until you need it. In practice, metadata is what makes filtering, traceability, and reproducibility possible. Useful chunk-level metadata commonly includes document IDs, section paths, page numbers, timestamps (effective date, last modified, ingested at), extraction confidence signals, and version identifiers (document hash, chunking version, embedding model version). In enterprise contexts, access-control attributes (tenant, department, confidentiality, role tags) need to be first-class, because they directly constrain retrieval and audits.
The Retrieval Stack That Actually Works
Vector similarity search is a good baseline, but it’s rarely sufficient on its own for enterprise documents. In practice, hybrid retrieval—dense embeddings plus sparse lexical retrieval like BM25—tends to be more robust, especially when users query with clause numbers, identifiers, acronyms, or exact phrasing. Dense retrieval handles semantic intent well; sparse retrieval anchors you to exact terms and rare tokens that embeddings often smooth over.
Reranking is often where systems make the biggest leap in perceived quality, not because it’s magical, but because it fixes a common failure mode: the initial retrieval set contains “kinda relevant” chunks, and you need to promote the truly relevant ones to the top. Cross-encoder re-rankers (open models like bge-reranker or managed APIs like Cohere ranker) rescore candidate chunks using deeper query–passage interaction. Teams usually see a noticeable lift in context precision when reranking is measured properly (for example, on a golden set with expected sources). If you keep a quantitative claim here, it’s best to tie it to a metric (“context precision” or “citation precision”) and an evaluation setup, rather than a broad “accuracy” number.
Query rewriting and expansion is another lever that’s easy to skip early and then rediscover later. Users don’t naturally phrase questions the way documents are written. A rewrite step can expand acronyms, normalize entities, and split multi-part questions into retrieval-friendly sub-queries. It doesn’t need to be fancy—but it does need observability, because uncontrolled rewriting can drift away from user intent.
Security: The Layer Everyone Forgets
Most RAG demos ignore access control because it slows down the prototype. In production, it’s a primary constraint. If your system indexes HR documents, legal contracts, and engineering specs together, you need a deterministic entitlement path from user → allowed chunks, and retrieval must be constrained by that path before any content reaches an LLM.
The pattern that tends to scale is pre-filtered retrieval: compute entitlements (RBAC/ABAC), retrieve only from chunks with compatible ACL attributes, rerank within the authorized candidate set, and log what evidence was accessed. This is also where the “metadata isn’t optional” point shows up in practice—without chunk-level tagging, you end up with leaky boundaries or expensive, brittle post-filters.
Beyond ACL, enterprise deployments typically need some combination of PII detection/masking, encryption at rest, short-lived tokens for source access, and audit logging that captures query, retrieved chunk IDs, citations, and document versions. One more modern concern worth taking seriously is prompt injection content inside documents. You don’t need to treat every document as hostile, but you do need basic guardrails so instructions embedded in source text can’t supersede your system’s rules—especially around access control, disclosure, and how the model is allowed to behave.
Monitoring: Closing the Loop
If you operate one of these systems for more than a few weeks, you’ll see drift. Documents change, the query distribution changes, the ingestion pipeline changes, and model components get updated. Without monitoring and evaluation, quality degrades quietly until users stop trusting the tool.
Practically, you want to track retrieval health (recall@k against a golden set, context precision, reranker lift), generation health (citation precision, groundedness/faithfulness checks, refusal rates), and operational health (p50/p95 latency, cost per query, ingestion lag from document update to searchable index). The most effective teams I’ve seen maintain a golden evaluation dataset—curated questions with expected source documents—and run it on a schedule and on change events (new embeddings, new chunking logic, new document batches). Tooling like Phoenix, TruLens, or commercial platforms can help, but the bigger differentiator is the discipline to keep evaluation current and to treat regressions like real production incidents.
One area that’s frequently underestimated is versioning and reproducibility. When you change OCR models, chunking logic, embedding models, rerankers, or generation prompts, you need a way to trace which versions produced which answers. That’s what makes debugging and audits feasible months later.
Choosing Your Stack
Stack decisions matter, but capabilities matter more. For many teams, a managed-leaning setup is attractive: ingestion via a managed Document AI tool or Unstructured-based pipeline, a hosted vector database, an orchestration layer such as LlamaIndex or LangChain, and a reranker (open or managed). Others prefer open-source deployments using Qdrant/Weaviate/OpenSearch, Haystack or similar orchestration, and self-hosted models for control and cost predictability. Either approach can work if it supports the fundamentals: document-aware ingestion, hybrid retrieval, entitlement enforcement, provenance-friendly citations, evaluation pipelines, and versioning.
On the architecture side, systems tend to become easier to operate when they’re split cleanly: ingestion workers that run asynchronously and can be retried safely; a stateless retrieval service that enforces policies and returns evidence; and a generation service that operates with bounded context and clear provenance. A typical reference deployment includes an API gateway, a job queue (Kafka/RabbitMQ), object storage for raw documents and parsed artifacts, the index layer (dense + sparse), plus centralized logging/metrics and an audit trail.