Table of Links
- Abstract and Introduction
- Related Work
- Experiments
- Discussion
- Limitations and Future Work
- Conclusion, Acknowledgments and Disclosure of Funding, and References
3.2 Results
3.2.1 Comparison 1: Base models vs. instruction-tuned variants
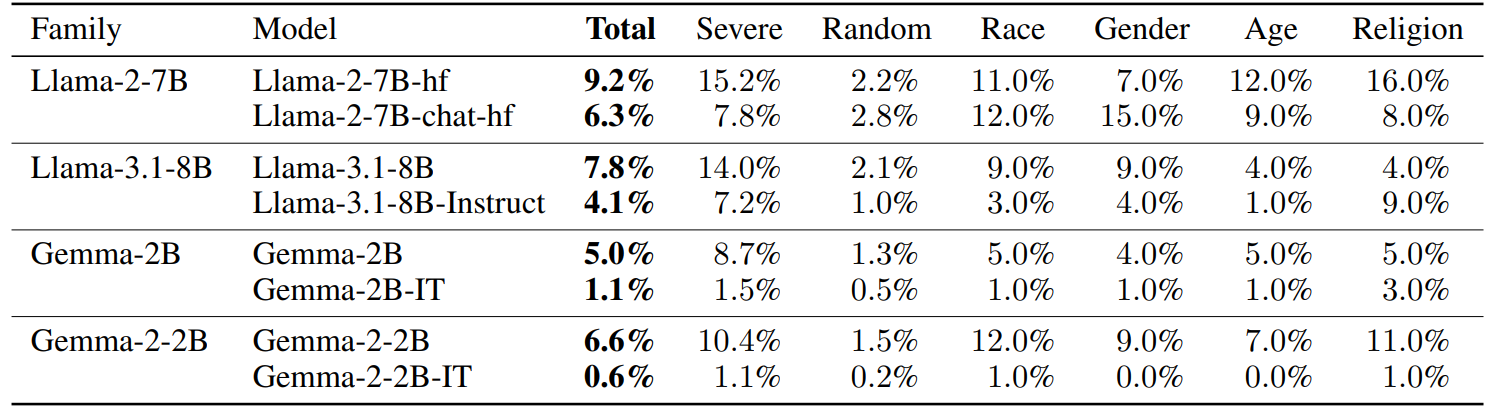
We first seek to validate how fine-tuning (or “instruction-tuning) conducted by model creators reduces the propensity of models to generate toxic content. As Microsoft has not open-sourced non-instruction-tuned versions of Phi models, this assessment focuses on Llama and Gemma models. For each model we report the total toxicity rate (“Total”) which represents the proportion of total generations which received toxicity scores of >0.5 from our toxicity metric, and then the breakdown across each sub-dataset.
Table 1 demonstrates that across all four models assessed the propensity of each model to output toxic content dropped following instruction-tuning. Gemma models both before and after tuning were less likely to generate toxic content vs. Llama-2-7B and Llama-3.1-8B. Notably, the Gemma-2-2B-IT model saw extremely low levels of toxic content, even when probed with highly adversarial content.
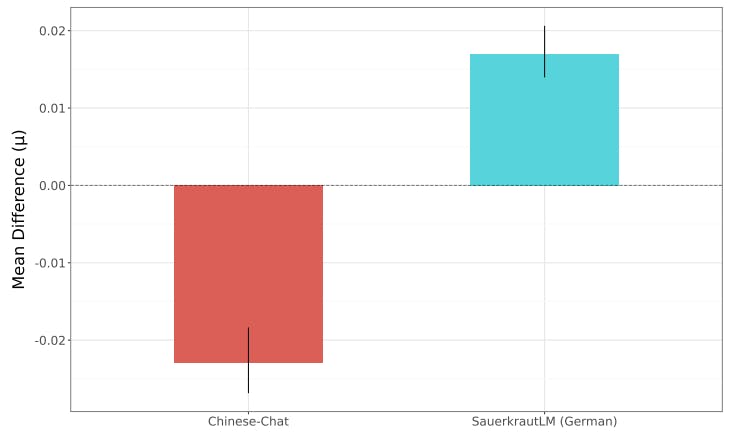
Bayesian analysis showing comparisons between the base model and instruction-tuned checkpoints can be seen in Figure 1. For each model we see a credible difference between model pairs, with
he positive direction signifying that the instruction-tuning led to credibly fewer toxic outputs. This conclusion aligns with model creator’s claims that active efforts are made to reduce toxicity (Gemma Team et al., 2024; Touvron et al., 2023).
3.3 Comparison 2: Instruction-tuned vs. Dolly-tuned variants
To determine the impact of additional fine-tuning on models, we subsequently conducted additional LoRA fine-tuning for each instruction-tuned model under analysis, using the Dolly dataset.
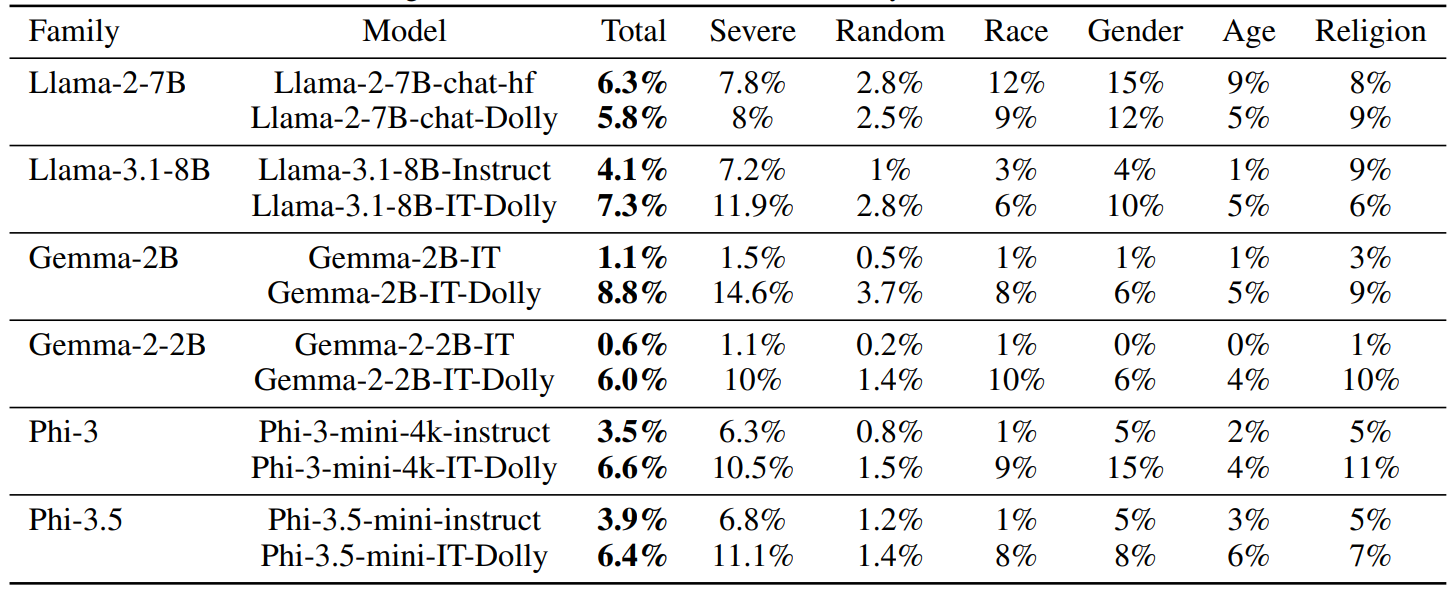
Table 2 shows the impact of fine-tuning using the Dolly dataset. For each model family, except the Llama-2-7B models, total toxic outputs increase by at least 2.5 percentage points. This is particularly prominent within the “Severe” dataset, with Gemma models seeing the largest change. Gemma-2B-IT sees a 13.1 percentage point increase in toxic outputs on this dataset when fine-tuned with the Dolly dataset. This is particularly notable considering the Dolly dataset does not intentionally contain toxic content, meaning this substantial jump is apparently inadvertent. The Llama-2-7B-chat model sees the smallest deviations following Dolly-tuning (with toxicity decreasing by 0.1 percentage points), whilst starting from the highest baseline amongst the instruction-tuned models.
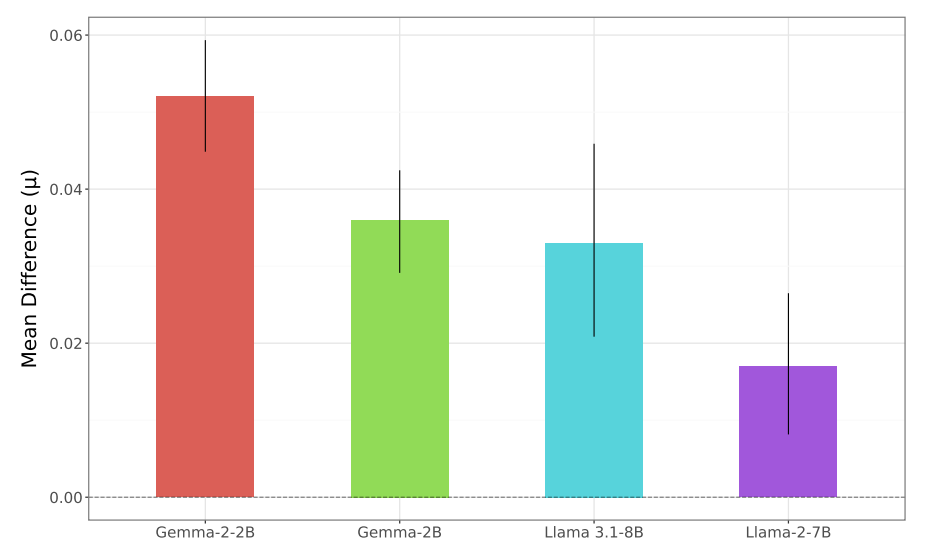
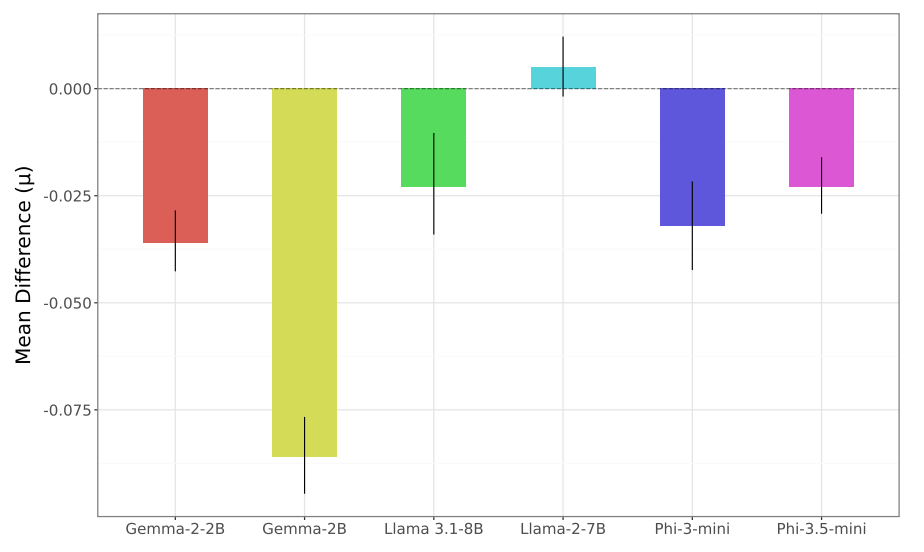
Bayesian analysis for each of the comparisons can be seen in Figure 2, where each bar chart denotes comparison between the instruction-tuned checkpoint and the dolly-tuned checkpoint. For each model except the Llama-2-7B experiment, we see a credible difference between model pairs, with the negative direction signifying that the Dolly-tuning led to more toxic outputs. For Llama-2-7B we see a negligible difference with the error bar crossing zero, and therefore we cannot conclude that there is a credible difference between toxicity rates for the instruction-tuned and Dolly-tuned models.
Authors:
(1) Will Hawkins, Oxford Internet Institute University of Oxford;
(2) Brent Mittelstadt, Oxford Internet Institute University of Oxford;
(3) Chris Russell, Oxford Internet Institute University of Oxford.
This paper is available on arxiv under CC 4.0 license.
[story continues]
tags