Authors:
(1) Ze Wang, Holistic AI and University College London;
(2) Zekun Wu, Holistic AI and University College London;
(3) Jeremy Zhang, Emory University;
(4) Navya Jain, University College London;
(5) Xin Guan, Holistic AI;
(6) Adriano Koshiyama.
Table of Links
A. Mathematical Formulation of WMLE
C Qualitative Bias Analysis Framework and Example of Bias Amplification Across Generations
D Distribution of Text Quality Index Across Generations
E Average Perplexity Across Generations
F Example of Quality Deterioration Across Generations
Abstract
As Large Language Models (LLMs) become increasingly integrated into various facets of society, a significant portion of online text consequently become synthetic. This raises concerns about bias amplification, a phenomenon where models trained on synthetic data amplify the pre-existing biases over successive training iterations. Previous literature seldom discusses bias amplification as an independent issue from model collapse. In this work, we address the gap in understanding the bias amplification of LLMs with four main contributions. Firstly, we propose a theoretical framework, defining the necessary and sufficient conditions for its occurrence, and emphasizing that it occurs independently of model collapse. Using statistical simulations with weighted maximum likelihood estimation, we demonstrate the framework and show how bias amplification arises without the sampling and functional form issues that typically drive model collapse. Secondly, we conduct experiments with GPT2 to empirically demonstrate bias amplification, specifically examining open-ended generational political bias with a benchmark we developed. We observe that GPT-2 exhibits a rightleaning bias in sentence continuation tasks and that the bias progressively increases with iterative fine-tuning on synthetic data generated by previous iterations. Thirdly, we explore three potential mitigation strategies: Overfitting, Preservation, and Accumulation. We find that both Preservation and Accumulation effectively mitigate bias amplification and model collapse. Finally, using novel mechanistic interpretation techniques, we demonstrate that in the GPT-2 experiments, bias amplification and model collapse are driven by distinct sets of neurons, which aligns with our theoretical framework.
1 Introduction
Large language models (LLMs) are trained on vast amounts of text scraped from the internet, which plays a crucial role in improving their capabilities, whether through emergent abilities (Wei et al., 2022) or scaling laws (Kaplan et al., 2020). However, as LLMs become more widely integrated into human society—for example, in content creation and summarization in media, academia, and business (Maslej et al., 2024)—concerns are mounting that a significant portion of online text in the future may be generated, either entirely or partially, by LLMs (Peña-Fernández et al., 2023; Porlezza and Ferri, 2022; Nishal and Diakopoulos, 2024). This highlights a significant and underexplored risk: bias amplification, referring to the degradation of fairness within LLMs over self-consuming training loops (Mehrabi et al., 2022; Taori and Hashimoto, 2022), where models progressively amplify the pre-existing biases. This concern initially arises from the tendency of LLMs to learn from biased datasets. For example, Parrish et al. (2022); Wang et al. (2024); Bender et al. (2021) show that LLMs absorb inherent stereotypes, such as racial and gender discrimination, embedded in human-generated text. Additionally, Haller et al. (2023); Rettenberger et al. (2024a) demonstrated that LLMs can be aligned with specific political ideologies by finetuning them on biased datasets. Moreover, Wyllie et al. (2024) shows that classifiers trained on synthetic data increasingly favor a particular class label over successive generations, while the shrinking diversity observed by Alemohammad et al. (2023); Hamilton (2024) suggests a risk that certain demographic groups may become progressively underrepresented in the outputs of LLMs.
The amplification of biases has profound societal implications. It can lead to the perpetuation of stereotypes, reinforcement of social inequalities, and the marginalization of underrepresented groups. In the context of political bias, this can influence public opinion, skew democratic processes, and exacerbate polarization. Understanding and mitigating bias amplification is therefore crucial to ensure that LLMs contribute positively to society and do not inadvertently cause harm. Nevertheless, despite the literature on bias amplification in discriminative models, there is a notable lack of comprehensive frameworks and empirical studies specifically addressing bias amplification for LLMs, as shown in Section 2. In contrast to discriminative models, where bias amplification can be attributed to overfitting the dominant features in the training dataset, its occurrence in LLMs may stem from a more nuanced issue. As we will show in Sections 3 and 5, even when the training data is unbiased, the model can still amplify its pre-existing biases during the training process.
In this paper, we seek to fill this research gap by proposing a theoretical framework that establishes and explains the causes of bias amplification in LLMs. Additionally, we perform both statistical simulation and LLM experiments to demonstrate and exemplify the theorem. In summary, our main contributions are as follows:
-
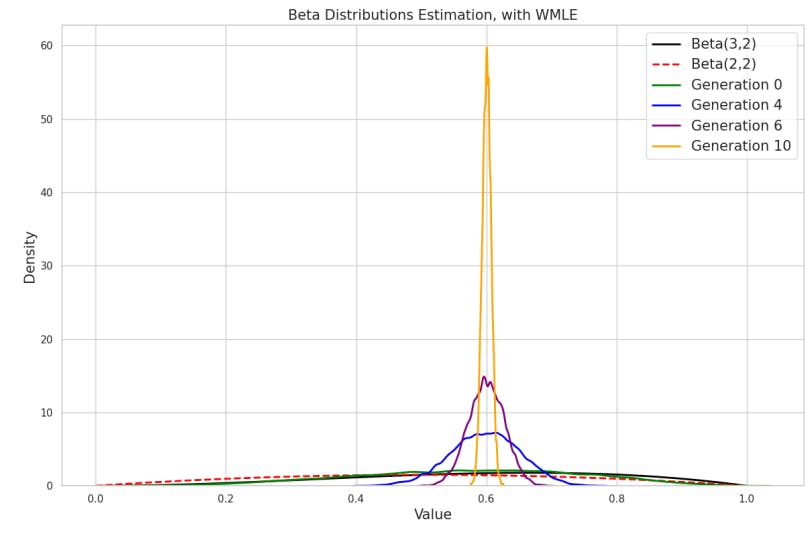
Theoretical Framework: We establish the necessary and sufficient conditions for bias amplification (i.e. Theorem 1). The theorem aids in understanding the cause of bias amplification and in distinguishing between bias amplification and model collapse. We conduct statistical simulations using weighted maximum likelihood estimation to illustrate the theorem (see Section 3.2).
-
Benchmarking Tool: We trained a highly accurate classifier capable of detecting political leaning in long-text content. With this classifier, we offer a benchmark for evaluating political bias in LLMs through open-generation tasks, filling a gap not covered in current bias studies (see Sections 2 and 4.3).
-
Empirical Demonstration and Mitigation Strategies: We demonstrate bias amplification in terms of political bias in GPT-2 using our benchmarking tool: the model exhibits a right-leaning bias in sentence continuation tasks and becomes increasingly right-leaning over successive generations (see Section 5.1). Additionally, we conducted experiments with three potential mitigation strategies, i.e. Overfitting, Preservation, and Accumulation, comparing their effectiveness, and found that some are surprisingly effective (see Section 5.3).
-
Mechanistic Interpretation: Building on our framework, we propose an innovative mechanistic interpretation pipeline that identifies two distinct sets of neurons responsible for bias amplification and model collapse during iterative fine-tuning experiments with GPT-2. We found minimal overlap between these two sets, supporting our theorem that bias amplification can occur independently of model collapse (see Section 5.4).
The rest of the paper is organized as follows: We first discuss related work in Section 2. In Section 3, we present our theoretical framework for bias amplification and conduct a statistical simulation. Section 4 describes the experimental setup for our LLM experiments, including data preparation and model fine-tuning. In Section 5, we present our empirical findings on bias amplification and the effectiveness of mitigation strategies. Finally, in Section 6, we discuss the implications of our work, concluding with limitations in Section 7.
This paper is available on arxiv under CC BY-NC-SA 4.0 license.