Research Evaluation
After a month of working, the full research report is finally done!
Being that it’s 40 pages long in total, you can find it on GitHub either in rendered Mark-Down or PDF format. I recommend reading the main paper, but I’ve included a quick summary below.
Summary
This report evaluates a six-month live trading experiment in which a large language model (ChatGPT) managed a micro-cap equity portfolio under strict, forward-only constraints. Rather than optimizing for performance, the experiment was designed to study decision behavior: how the model reacted to gains and losses, how often it re-entered positions, how it handled risk through stop-losses, and how its decisions evolved over time. All trades, portfolio states, prompts, and outcomes were logged and preserved to ensure transparency and auditability.
Overall analysis was mixed. While the portfolio failed to outperform major benchmarks over the full period, the results revealed several consistent behavioral patterns. The model demonstrated persistence in certain position-level theses, frequently re-entering previously traded securities even after poor realized outcomes. At FIFO lot and pure PnL level, removing a single extreme outlier (ATYR) materially altered aggregate metrics such as profit factor and expectancy, highlighting the sensitivity of short-horizon micro-cap strategies to tail events. These findings reinforce the importance of the structure and stability of decision-making.
Importantly, this analysis reflects a single experimental run and does not attempt to generalize performance claims. Instead, the value of the experiment lies in what it reveals about how large language models behave when placed in environments with irreversible consequences and limited human guidance. The full report documents methodology, failure modes, and limitations in detail, and serves as a foundation for future experiments focused on understanding LLM decision-making under risk. Future work will extend this framework to additional market regimes and repeated trials to better separate behavioral tendencies from noise.
LLM Investor Behavior Benchmark — LIBB
After noticing a lack of a flexible, open-source standard research library for LLM experiments, I changed my focus from a generic LLM trading benchmark to powerful library for researchers.
Just create your prompts and schedule and LIBB can automatically create the predictable filesystem, handle all portfolio processing, analyze sentiment, behavior, and performance, and graph your collected data.
Because of its simplicity and flexibility, use future experiments will use LIBB for experimental setup.
Code Example
from libb.model import LIBBmodel
from .prompt_models import prompt_daily_report
from libb.other.parse import parse_json
import pandas as pd
MODELS = ["deepseek", "gpt-4.1"]
def daily_flow(date):
for model in MODELS:
libb = LIBBmodel(f"user_side/runs/run_v1/{model}", run_date=date)
libb.process_portfolio()
daily_report = prompt_daily_report(libb)
libb.analyze_sentiment(daily_report)
libb.save_daily_update(daily_report)
orders_json = parse_json(daily_report, "ORDERS_JSON")
libb.save_orders(orders_json)
return
With only one user created function, LIBB allows a simple workflow to automatically create identical file systems for different models, process pending orders, save future orders and raw reports, and analyze and log sentiment from the given reports.
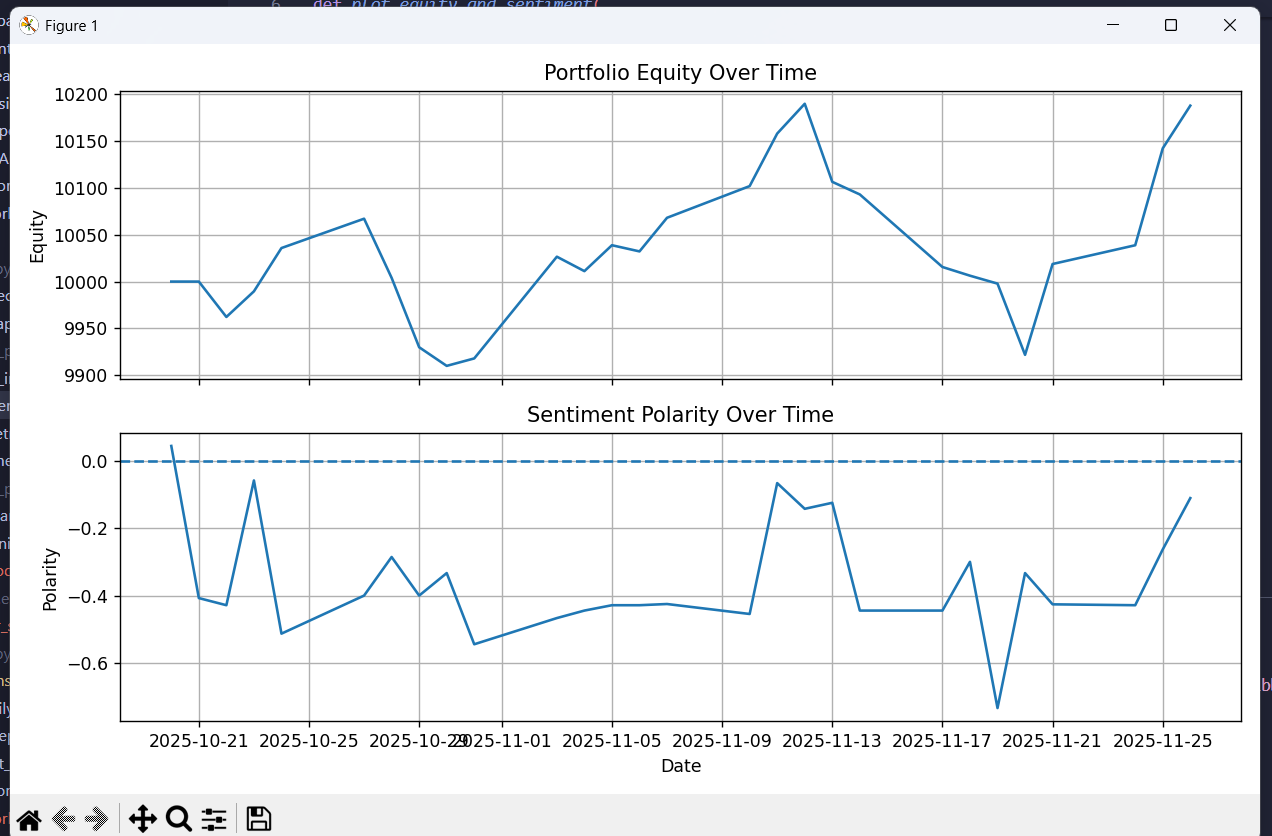
Example Graph
LIBB also allows ease for graphing. By saving report sentiment over a month of back-testing, I can call a function and LIBB generates:
Sooo.. What’s Next?
Right now I’m focusing my attention on LIBB and making sure it provides a stable foundation for my future experiment over new IPOs. After that, I’ll begin developing the experiment’s workflow and create a blog finalizing rules and explaining the setup.
As always, I post more frequent updates on both X and LinkedIn.
Let me know what you guys think of the report and the new project!