
You are just beginning your journey in designing distributed systems. You already have a general understanding of the business for which you need to design the architecture of the future application. You begin to think about how your system will store and transmit data in a distributed environment. And now you come to the business and start asking questions:
— You want a distributed system with many nodes, right?
— Right.— How quickly should the system respond?
— Instantly.— Okay… And the data must always be up-to-date?
— Of course!— And should everything keep working even if half of the servers fail?
— Naturally!— Got it… And what’s the project?
— A local coffee shop on one street… we only have two tables, Wi-Fi doesn’t always work, but we dream big.
An example of such a dialogue immediately raises several red flags that you, as an architect, should notice and realize that it’s necessary to adjust the business’s expectations. Even though the situation is highly exaggerated, in practice, similar conversations happen quite often at the early stages of projects.
And it’s precisely at this moment that it’s important to be able to explain that not all requirements can coexist at the same time — which means it’s time to understand the CAP theorem, which will help you set the right priorities in your conversation with the client and ask the business 5 more appropriate questions that will help you design an architecture that will work.
CAP Theorem 101
So, you see in front of you a list of conflicting requirements from the business — “instant responses,” “up-to-date data,” and “operation during failures.” This is where the CAP theorem comes to the rescue, explaining a fundamental limitation in the world of distributed systems.
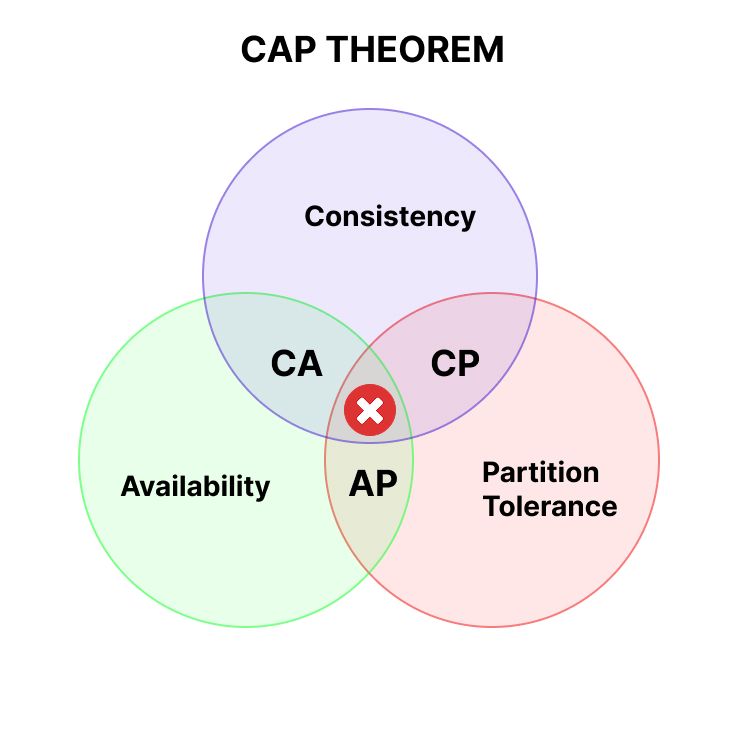
The CAP theorem states that any distributed system has three major properties to consider:
Consistency (C) — all nodes see the same data at the same time. If you read the data immediately after writing, it should be fresh.
Availability (A) — every request to the system receives a valid (even if possibly outdated) response, even when something goes wrong.
Partition tolerance (P) — the system continues to operate even when communication is lost between nodes, that is, during network failures, while Availability is a property of the system to respond with a valid response in principle, regardless of what is happening inside (e.g., service crash, overload)
And out of three properties, you can guarantee only two of the three properties at the same time. The full set is unattainable in a real distributed environment. In 2002, Seth Gilbert and Nancy Lynch of MIT published a formal proof of this theorem.
If the network is reliable, the choice is easier. But as soon as the risk of network partition appears — and it almost always does — the system must “choose a side”:
- A CP system will sacrifice availability for consistency (for example, by refusing to respond to requests during a network partition).
- An AP system will sacrifice strict consistency for availability (for example, responding with stale data so as not to “go down”).
- CA systems are possible only under ideal conditions without network partitions (essentially a myth for real-world production).
Thus, to build an optimal architecture, you need to ask the business several “right” questions to steer the architecture in the right direction. Here, I listed these questions:
Question #1 — Do you really need a distributed architecture?
Distributed architecture is mainstream today. Many businesses want it because they’ve heard that it will solve many problems: provide fault tolerance, increase scalability, and make the system “like the big players”. But behind this desire, there is often an illusion: distributed architecture doesn’t just “make everything better” — it brings additional complexity, new classes of problems, and high maintenance costs.
Therefore, it is important for the architect to ask a simple but critical question:
Do you have real reasons for a distributed architecture? Is such a scale of load or geographic distribution of users expected, where a simple centralized system would no longer cope?
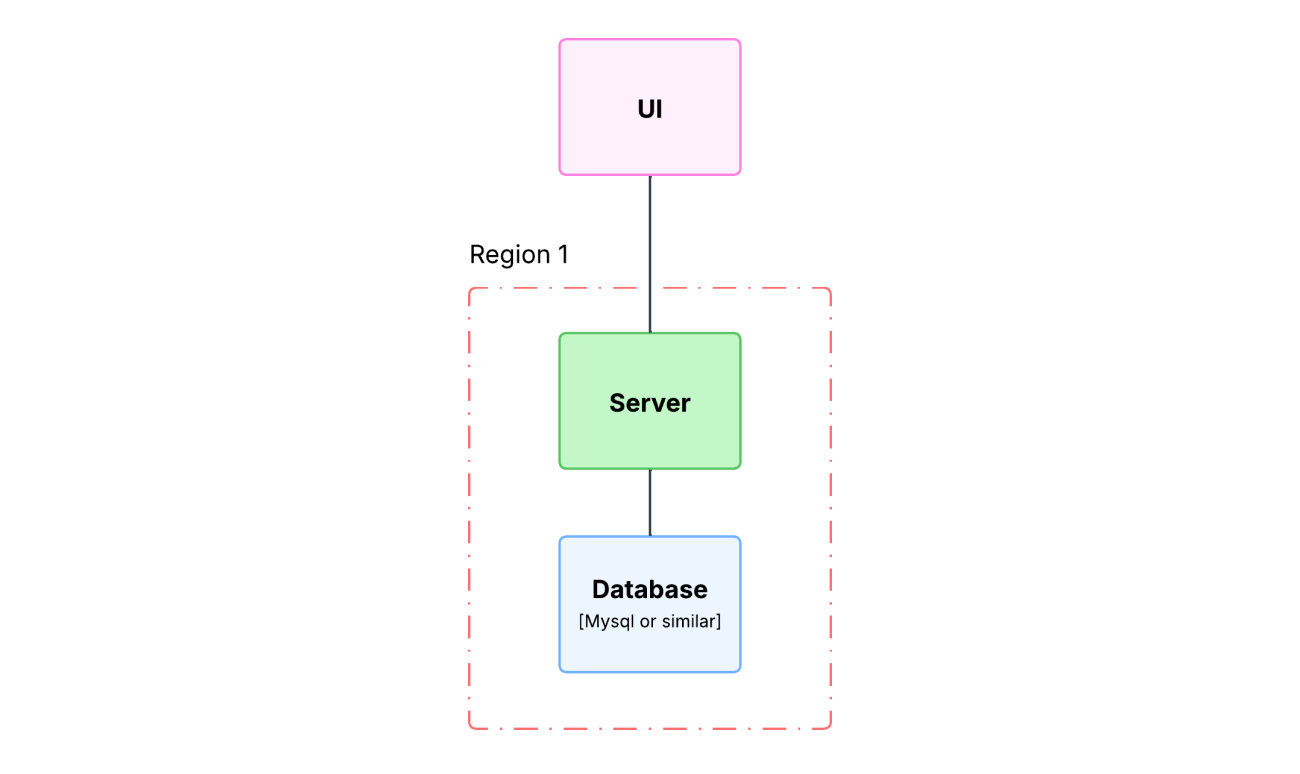
Most often, for a small project or local business, it is simpler, cheaper, and more reliable to use a traditional monolithic architecture deployed in a single data center or region.
For example, for the coffee shop with two tables from the example above, a simple application on a single server with minimal architecture and well-thought-out backup would be sufficient — without unnecessary complexity.
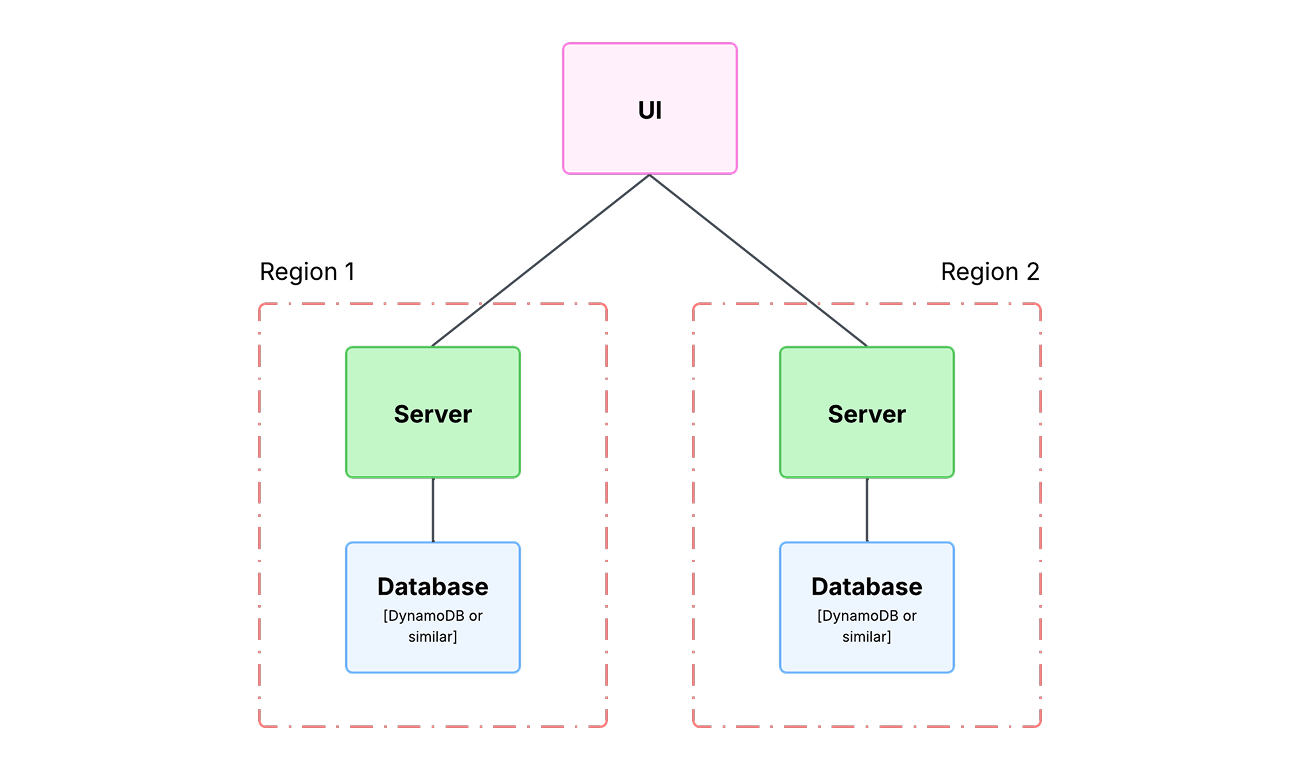
But let’s assume that the coffee shop has opened dozens of locations in different countries. Now, they have a global menu, clients from different time zones, and a need to serve users quickly and correctly all over the world.
In such a situation, a distributed architecture really starts to make sense. And this is where the architect should move on to the second key question:
Question #2 — How critical is data consistency?
If we have determined that a distributed architecture is justified, the next important question for the architect is:
How critical is it for your business that the data is always up-to-date and consistent across all nodes of the system?
Consistency is the guarantee that every user, no matter where they are, sees the same up-to-date version of the data. For some business processes, this is truly critical: for example, when it comes to stock levels in a warehouse or the balance on a customer’s account. For other scenarios, some delay is quite acceptable: it’s not critical if a user in Tokyo sees a new review left by a customer in New York a few seconds later.
Returning to our coffee shop with locations in different countries.
Let’s assume that the business goal is simply to show the menu and news in the app. In that case, it’s perfectly fine to live with eventual consistency: small delays in data synchronization between regions will not harm the business.
In such a situation, our architecture evolves into an AP system, where availability and partition tolerance are more important than strict consistency. For example, we could choose an AP-oriented database — Cassandra DB or DynamoDB.
The answer to the consistency question will allow you, as the architect, to understand how strict consistency guarantees are really needed in a particular business context, and where more flexible and less costly solutions can be used to simplify the architecture.
Question #3 — What level of availability is expected?
After we’ve clarified the data consistency requirements, the next important question for the architect is:
How critical is it for your business that the system remains available to users at any given time?
Availability is the property of the system to respond to user requests even in the case of problems with individual nodes or parts of the infrastructure. But it’s important to understand: a high level of availability always means investments in fault tolerance, replication, and complex infrastructure.
For a coffee shop with several locations in different countries, a dialogue with the business is again needed here. If the coffee shop wants users to be able to view the menu or order delivery at any time of day, even if some data centers are temporarily unavailable, then availability becomes a priority.
If the system can tolerate occasional periods of unavailability (for example, at night local time when there are no orders anyway), then it’s possible to save on infrastructure and simplify the design.
Once the level of availability requirements is clear, the fourth logical question arises:
Question #4 — How should the system behave during network failures (Partition tolerance)?
So, even if the business wants high availability, the architect must ask another important question:
What do you expect from the system in case of network failures between nodes? Should the service continue operating during partial loss of connectivity, even if this means a possible loss of data consistency?
Here is the trick.
In real distributed systems, partition tolerance is not optional: in a global network, failures between segments happen sooner or later.
And at that moment, the system faces the CAP dilemma:
Either continue operating, preserving availability but risking temporary loss of consistency (AP scenario), or suspend processing requests to guarantee consistency after connectivity is restored (CP scenario).
Sometimes, it’s better to "freeze" system operation when connectivity is lost in order to guarantee data integrity and freshness; then this is a choice in favor of Partition tolerance + Consistency (CP).
The answer to this question will help the architect understand how to design the system’s behavior for unpredictable but inevitable real-world conditions — network failures between nodes.
Question #5 — Can we split the system into areas with different requirements?
After you’ve discussed with the business the basic requirements for distributed architecture, consistency, availability, and behavior during failures, it’s important to ask one more strategic question:
Are there different parts of your system with different business requirements for consistency, availability, and fault tolerance? Can we separate them and apply different architectural approaches?
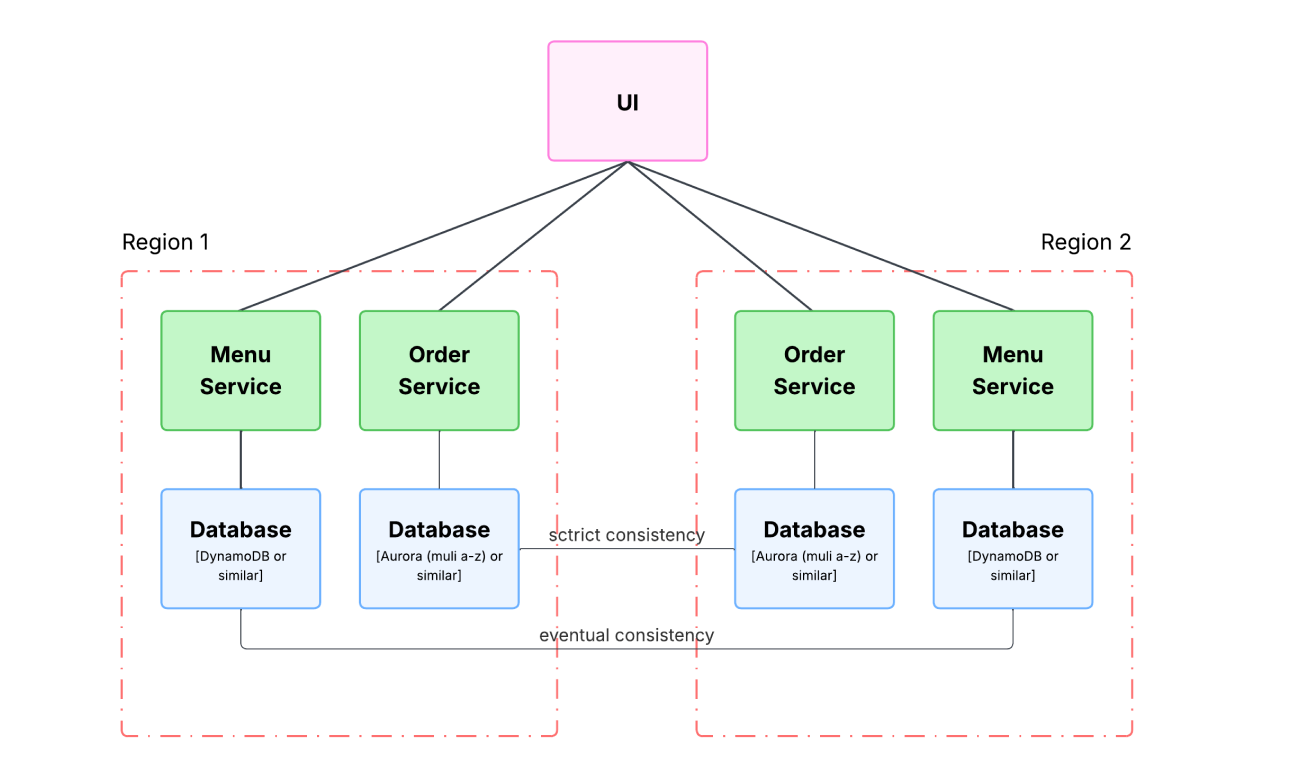
In real life, requirements are almost never uniform. Some functions require strict consistency (for example, calculating loyalty points). For other functions, eventual consistency is acceptable (for example, updating news or promotions in the app).
Different parts of the system may have different types of requirements.
For example:
- Viewing promotions may tolerate short periods of unavailability in certain regions
- Viewing menu is likely to require high availability, but eventual data consistency
- Placing an order requires high data consistency for our case
- Orders and loyalty program management require data strictness (more like CP).
- Posting reviews or updating interior photos can work with eventual consistency (AP).
- Some things can be cached in a CDN.
It’s important to understand here that, according to the CAP theorem, we cannot guarantee availability for the order processing system because we require that data must always be up-to-date. And at the same time, we cannot guarantee data freshness for the menu because we want the menu to always be available.
This question allows the architect to design not a single “monolithic” distributed system, but a hybrid architecture where each component matches its actual business requirements.
This means:
- Optimization of infrastructure costs
- Simplification of maintenance
- Increased reliability
Conclusion
Architecture is not just the ability to beautifully draw diagrams on a whiteboard. It is also the ability to manage business expectations.
As an architect, you need not only to understand technical limitations and trade-offs but also to recognize unrealistic business expectations in time — and properly replace them with realistic ones.
It’s important to remember: business requirements for a system are rarely binary (“yes” or “no”). In practice, it’s always a gradient: the business tends to answer "yes" to all questions (“Do we need high availability?”, “Do we need consistency?”, “Do we need fault tolerance?”), because these qualities sound like obvious values.
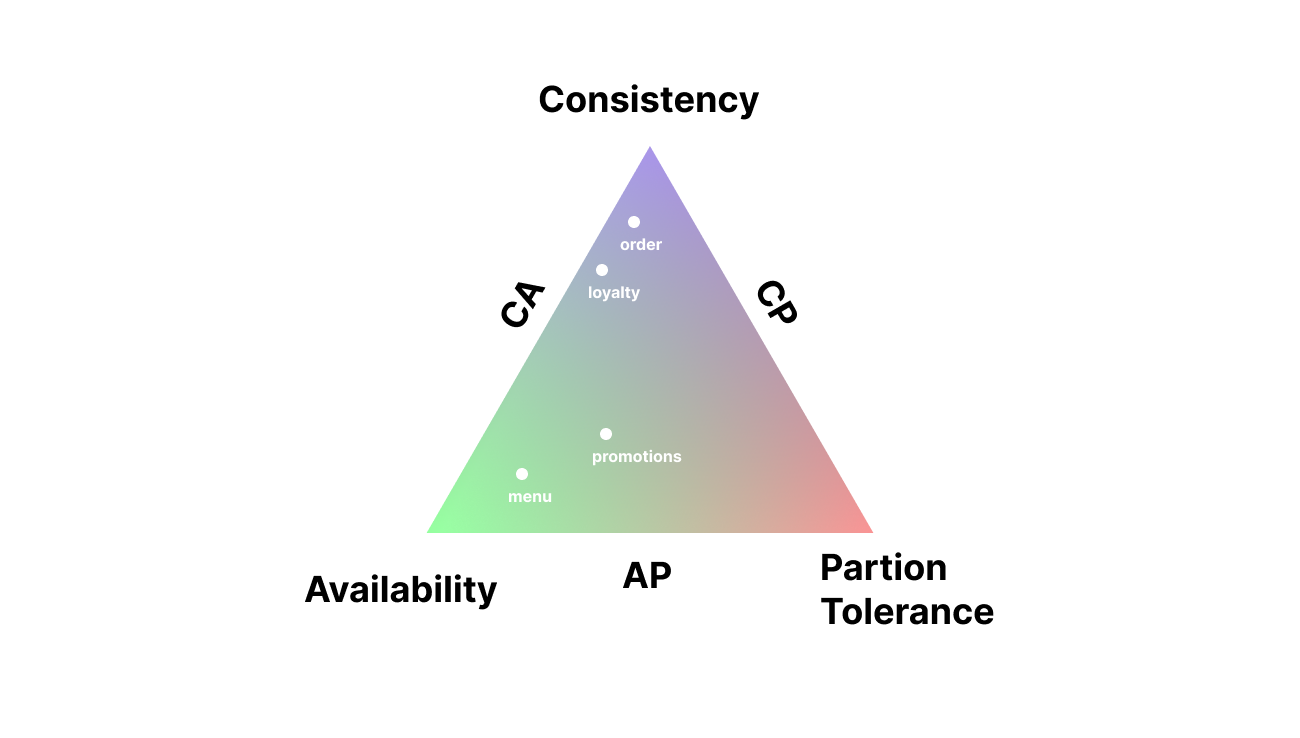
Your task is to help the business see this gradient and find the right place on the requirement scale for each specific system component:
- Where is strict consistency critical?
- Where can we sacrifice it for availability?
- Where is partition tolerance truly required?
- Where is distributed architecture justified?
- What should be extracted as an independent component?
CAP Theorem helps you to build the right set of questions for businesses and for yourself. The answers to these questions are the foundation for building an architecture that not only meets business objectives but also remains manageable, reliable, and economically justified.
[story continues]
tags