Introduction
From version 2.0.3, Cisco Webex has been using Apache DolphinScheduler to establish its big data scheduling platform for nearly three years.
Recently, the Webex team shared their experience of using Apache DolphinScheduler of version 3.1.1 to develop new features not included in the community version, which is mainly about how they use Apache DolphinScheduler to build a big data platform and deploy our tasks to AWS, the challenges they encountered, and the solutions implemented.
The summary of the Webex’s practice on Apache DolphinScheduler is shown below:
Architecture Design and Adjustments
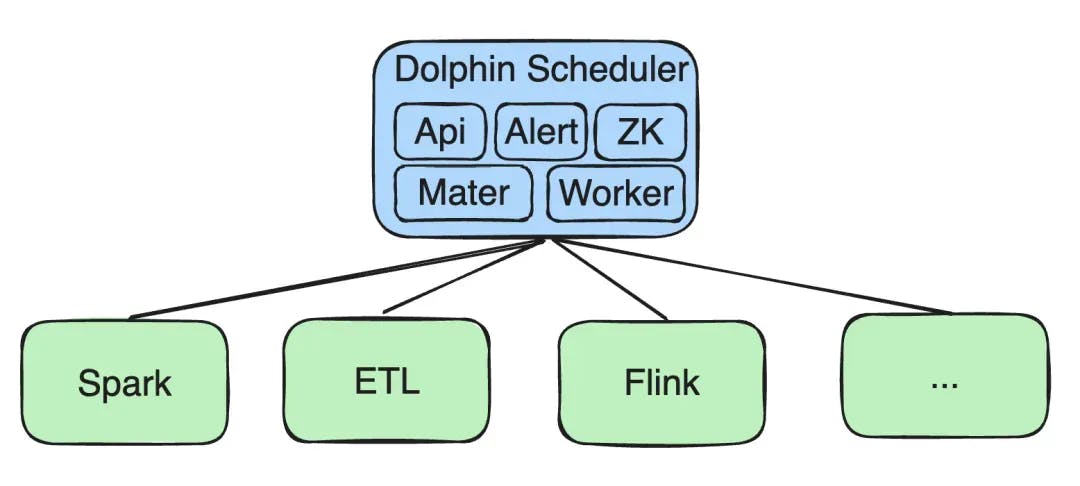
All our services were initially deployed on Kubernetes (K8s), including components like API, Alert, Zookeeper (ZK), Master, and Worker.
Big Data Processing Tasks
We carried out re-development for tasks such as Spark, ETL, and Flink:
- ETL Task: Our team developed a simple drag-and-drop tool that allows users to quickly create ETL tasks.
- Spark Support: Early versions only supported Spark running on Yarn. We extended it to support Spark on K8s. The latest version in the community now supports Spark on K8s.
- Flink re-development: Similarly, we added support for Flink On K8s streaming tasks, as well as SQL tasks and Python tasks on K8s.
Supporting Jobs on AWS
As our business expanded and data policies required, we faced the challenge of running data tasks in different regions. This necessitated building an architecture capable of supporting multiple clusters. Below is a detailed description of our solution and implementation process.
Our current architecture includes a centralized control terminal, which is a single instance of the Apache DolphinScheduler service that manages multiple clusters. These clusters are distributed in different geographical locations, such as the EU and the US, to comply with local data policies and isolation requirements.
Architecture Adjustments
To meet these requirements, we made the following adjustments:
- Centralized Management of Apache DolphinScheduler Service: Our DolphinScheduler service remains deployed in our self-built Cisco Webex DC, maintaining centralized and consistent management.
- Support for AWS EKS Clusters: At the same time, we extended the architecture’s capabilities to support multiple AWS EKS clusters. This meets the new business requirements of running tasks on EKS clusters without affecting the operation and data isolation of other Webex DC clusters.
With this design, we can flexibly respond to different business needs and technical challenges while ensuring data isolation and policy compliance.
Next, let me introduce the technical implementation and resource dependencies when running tasks with Apache DolphinScheduler in Cisco Webex DC.
Resource Dependencies and Storage
Since all our tasks run on Kubernetes (K8s), the following points are crucial to us:
- Docker Images
- Storage Location: Previously, all our Docker images were stored in Cisco’s Docker repository.
- Resource Files and Dependencies:
- JAR files and configuration files: We use Amazon S3 Bucket as the resource storage center, storing users’ JAR files and possible dependency configuration files.
- Security Resource Management: Sensitive information, such as database passwords, Kafka encryption information, and user-dependent keys, is stored in Cisco’s Vault service.
Secure Access and Permission Management
To access the S3 Bucket, we need to configure and manage AWS credentials:
- IAM Account Configuration
- Credential Management: We manage access to AWS resources through IAM accounts, including access keys and secret keys.
- K8s Integration: These credentials are stored in Kubernetes Secrets and referenced by the API Service to securely access the S3 Bucket.
- Permission Control and Resource Isolation: Through IAM accounts, we achieve fine-grained permission control, ensuring data security and business compliance.
IAM Account Access Key Expiration Issues and Countermeasures
In the process of managing AWS resources with IAM accounts, we encountered the issue of access key expiration. Here’s how we addressed this challenge.
- Access Key Expiration
- Key Lifecycle: The AWS key for an IAM account is typically set to expire automatically every 90 days to enhance system security.
- Task Impact: Once the key expires, all tasks relying on these keys to access AWS resources will fail, requiring us to update the keys promptly to maintain business continuity.
To handle this, we set tasks to restart periodically and configured corresponding monitoring. If the AWS account has issues before the expiration time, it will notify the relevant developers for handling.
Supporting AWS EKS
As our business expands to AWS EKS, we need to make a series of adjustments to the existing architecture and security measures.
For example, the Docker image mentioned earlier, which was previously stored in Cisco’s Docker repo, now needs to be pushed to ECR.
Support for Multiple S3 Buckets
Due to the decentralization of AWS clusters and the data isolation requirements of different businesses, we need to support multiple S3 Buckets to meet the data storage needs of different clusters:
- Cluster and Bucket Mapping: Each cluster accesses its corresponding S3 Bucket to ensure data locality and compliance.
- Policy Modification: We need to adjust our storage access policies to support reading and writing data from multiple S3 Buckets. Different business parties should access their corresponding S3 Bucket.
Password Management Tool Change
To enhance security, we migrated from Cisco’s self-built Vault service to AWS Secrets Manager (ASM):
- Using ASM: ASM provides a more integrated solution for managing AWS resource passwords and keys.
- IAM Role and Service Account Approach: We adopted an approach using IAM Roles and Service Accounts to enhance Pod security.
- Creating IAM Roles and Policies: First, create an IAM Role and bind the necessary policies to ensure only the necessary permissions are granted.
- Binding K8s Service Accounts: Then, create a Kubernetes Service Account and associate it with the IAM Role.
- Pod Permission Integration: When running a Pod, it can directly obtain the required AWS credentials through the IAM Role associated with the Service Account to access necessary AWS resources.
These adjustments not only enhance the scalability and flexibility of our system but also strengthen the overall security architecture, ensuring efficient and secure operation in the AWS environment. At the same time, they avoid the issue of automatic key expiration requiring a restart.
Implementation of Changes
- Code-Level Adjustments: We made modifications to the DolphinScheduler code to support multiple S3 Clients and added cache management for multiple S3 Clients.
- Resource Management UI Adjustments: Allow users to select different AWS Bucket names through the interface.
- Resource Access: The modified Apache DolphinScheduler service can now access multiple S3 Buckets, allowing for flexible data management between different AWS clusters.
AWS Resource Management and Permission Isolation
Integration with AWS Secrets Manager (ASM)
We extended Apache DolphinScheduler to support AWS Secrets Manager, allowing users to select keys in different types of clusters:
ASM Function Integration:
- User Interface Improvements: In the DolphinScheduler UI, we added the functionality to display and select different types of secrets.
- Automatic Key Management: During runtime, the file path of the user-selected secret is mapped to the actual Pod environment variable, ensuring secure use of the key.
Dynamic Resource Configuration and Initialization Service (Init Container)
To manage and initialize AWS resources more flexibly, we implemented a service called Init Container:
- Resource Pulling: Before the Pod executes, the Init Container automatically pulls the user-configured S3 resources and places them in the specified directory.
- Key and Configuration Management: According to the configuration, the Init Container checks and pulls password information from ASM, then stores it in a file and maps it through environment variables for Pod use.
Application of Terraform in Resource Creation and Management
We automated the configuration and management process of AWS resources through Terraform, simplifying resource allocation and permission settings:
- Resource Automation Configuration: Use Terraform to create the required AWS resources, such as S3 Buckets and ECR Repos.
- IAM Policy and Role Management: Automatically create IAM policies and roles to ensure each business unit can access the resources they need.
Permission Isolation and Security
We ensured the isolation of resources and the management of security risks by implementing fine-grained permission isolation strategies:
- Implementation Details
- Service Account Creation and Binding: Create independent Service Accounts for each business unit and bind them with IAM roles.
- Namespace Isolation: Each Service Account operates within a designated namespace, accessing its corresponding AWS resources through IAM roles.
Cluster Support and Permission Control Improvements
Cluster Type Expansion
We added a new field called cluster type to support different types of K8s clusters, including standard Webex DC clusters and AWS EKS clusters, as well as clusters with higher security requirements.
Cluster Type Management
- Cluster Type Field: By introducing the cluster type field, we can easily manage and extend support for different K8s clusters.
- Code-Level Customization: For the unique needs of specific clusters, we can make code-level modifications to ensure that jobs run on these clusters meet their security and configuration requirements.
Enhanced Permission Control System (Auth System)
We developed an Auth System specifically for fine-grained permission control, including project, resource, and namespace permissions management:
- Permission Management Functionality
- Project and Resource Permissions: Users can control permissions through the project dimension. Once they have project permissions, they have access to all resources under that project.
- Namespace Permission Control: Ensure that specific teams can only run their projects’ jobs in designated namespaces, thus ensuring operational resource isolation.
For example, if team A has A namespace, only certain project jobs can run in that namespace. User B cannot see or run team A’s job configurations.
AWS Resource Management and Permission Requests
We manage AWS resource permissions and access control through the Auth system and other tools, making resource allocation more flexible and secure:
- Support for Multiple AWS Accounts: The Auth system can manage multiple AWS accounts and bind them to different AWS resources, such as S3 Buckets, ECR, and ASM.
- Resource Mapping and Permission Requests: Users can map existing AWS resources in the system and request permissions, allowing them to easily select the necessary resources when running jobs.
Service Account Management and Permission Binding
To better manage service accounts and their permissions, we have implemented the following features:
Service Account Binding and Management
- Service accounts uniqueness: service accounts are uniquely distinguished by binding them to specific clusters, namespaces, and project names, ensuring their uniqueness.
- Permission Binding Interface: Users can bind service accounts to specific AWS resources, such as S3, ASM, or ECR, through the interface, achieving precise control over permissions.
Simplified Operations and Resource Synchronization
Although I’ve covered a lot, the actual process for users is quite simple, as the entire application process is typically a one-time task. To further enhance the user experience of Apache DolphinScheduler in the AWS environment, we have implemented several measures to simplify the operation process and enhance resource synchronization functionality.
Summary:
- Simplified User Interface: In DolphinScheduler, users can easily configure the specific clusters and namespaces in which their jobs will run.
- Cluster and Namespace Selection:
- Cluster Selection: Users can select the desired cluster for their jobs when submitting them.
- Namespace Configuration: Based on the selected cluster, users also need to specify the namespace where the job will run.
- Service Account and Resource Selection:
- Service Account Display: The page will automatically display the corresponding Service Accounts based on the selected project, cluster, and namespace.
- Resource Access Configuration: Users can select the S3 Bucket, ECR address, and ASM secrets associated with the Service Account from a dropdown menu.
Future Outlook:
Several areas in the current design could be optimized to improve job submission and ease of operations:
- Image Push Optimization: Consider skipping the Cisco intermediate packaging process and directly pushing the package to ECR, especially for image modifications specific to EKS.
- One-Click Synchronization: We plan to develop a one-click synchronization feature that allows users to automatically sync a resource package uploaded to an S3 Bucket to other S3 Buckets, reducing the need for repeated uploads.
- Automatic Mapping to Auth System: After AWS resources are created via Terraform, the system will automatically map these resources to the permission management system, avoiding manual resource entry by users.
- Permission Control Optimization: By automating resource and permission management, user operations become more streamlined, reducing the complexity of setup and management.
Through these improvements, we aim to help users deploy and manage their jobs more effectively with Apache DolphinScheduler, whether in Webex DC or on EKS, while enhancing the efficiency and security of resource management.