Most automation products do not fail because their model is weak.
They fail because orchestration is too expensive to run at the pace users expect.
If you are building a browser-native automation engine on Supabase and Vercel free tier, the default architecture usually looks rational on paper and catastrophic in operation: decision logic in Edge Functions, state transitions logged on every micro-step, and a browser client reduced to a remote actuator.
That pattern collapses under three pressures:
- invocation volume,
- write amplification,
- retry storms.
I built the system behind this article while working on YouxAI, so the examples come from code I authored. AI was used to help draft and edit the article structure, but the technical claims, implementation details, and examples were checked against the codebase. This is not a product announcement; the useful part is the architecture pattern and the trade-offs that made it hold under resource constraints.
1) The Resource Trap: Server-Side Orchestration Is the Wrong Default for Browser Automation
There is a seductive architecture many teams start with:
- Content script snapshots page state.
- Edge Function decides next action.
- Decision is persisted.
- Client executes one step.
- Client reports back.
- Repeat.
It gives a false sense of control. You centralize the "brain" but decentralize the cost.
Why this explodes compute budget
Automation is inherently high-frequency and stateful. A single multi-page application can emit dozens of state events:
- detected field groups,
- candidate value proposals,
- required-field failures,
- corrective retries,
- page transition checks,
- completion verifications.
If each event touches Edge runtime and database writes, infra spend is dominated by coordination, not business logic.
The rough cost shape is:
total_orchestration_cost ~= events_per_job * (function_invocation + db_write + retry_multiplier)
Free tiers tolerate light burst workloads. They do not tolerate chatty control planes.
Why this also hurts reliability
A server cannot directly manipulate browser reality. It cannot introspect transient DOM states, observe rendering races, or recover from portal-specific timing behavior without client round-trips.
So the server "controller" still depends on a client executor, and you get a fragile ping-pong loop:
server decide -> client attempt -> server reconcile -> client attempt
Under real-world latency and portal variability, that creates familiar failure modes:
- stale decisions after navigation races,
- duplicate work after uncertain acknowledgements,
- conflicting state writes from retries,
- noisy trigger chains from over-granular persistence.
What looks like a coordination strategy becomes a distributed systems tax.
For browser automation, especially on free-tier infrastructure, server-centric orchestration is often the wrong default because it pays premium prices for low-leverage work.
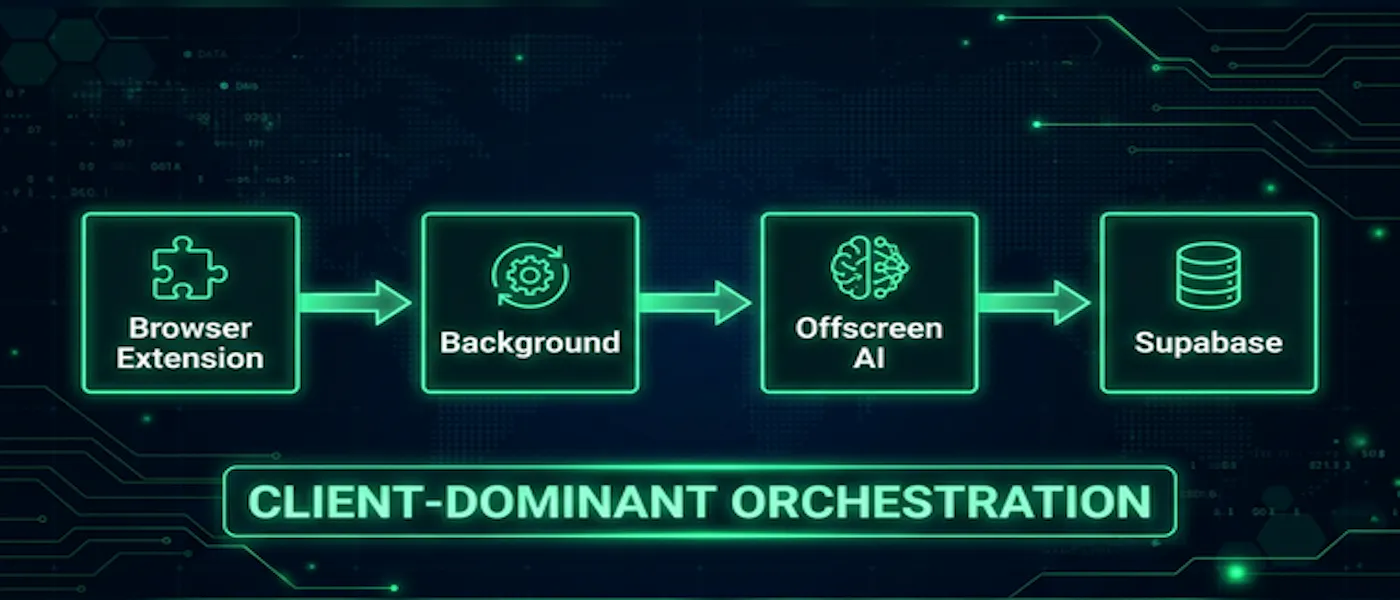
2) Client-Dominant Execution: Put the Control Loop Where State Is Observable
I flipped the architecture around a single rule:
The component that can observe and act on browser state should own the execution loop.
In practice:
- extension background script orchestrates,
- content scripts perform portal interaction,
- offscreen runtime handles local inference,
- Supabase stores durable state and synchronization artifacts.
Responsibility split
Extension side (hot path):
- tab lifecycle and navigation gating,
- page-context detection,
- local AI request dispatch,
- retry decisioning,
- pending-state recovery.
Supabase side (durable path):
- persistent entities,
- long-lived progress snapshots,
- cross-surface synchronization,
- event ingestion at coarse checkpoints.
This is not just a separation-of-concerns exercise. It directly removes network round-trips from the critical path.
Message flow that keeps the loop local
The execution pattern is intentionally asymmetric:
sidepanel/content -> background (ack pending)
background -> offscreen/local engine or content action
background -> commit durable transition to Supabase
The first acknowledgement is immediate to avoid message-channel timeout behavior in extension runtime. Work completes asynchronously. Results are routed back to the requester tab or runtime channel.
That "pending first, resolve later" contract keeps UI responsive while preserving deterministic completion behavior.
Why this scales better on free-tier plans
- You eliminate step-level server invocations for local decisions.
- You reduce control-plane write volume by committing only meaningful state boundaries.
- You align computation with active user sessions, where browser context is already loaded.
- You recover from service-worker churn via local cached pending state instead of server rehydration loops.
In one production save path, pending application data is cached in extension storage, deduplicated against existing database records, and only then persisted. If conditions are transient, such as auth or network instability, status remains pending for retry rather than forcing noisy partial commits.
Trade-off: no illusion of always-on workers
Client-dominant systems are session-bound. If the extension is inactive, the orchestration loop is inactive.
For browser-native automation, that is usually acceptable and often desirable. The product is not pretending to be a headless backend job engine; it is optimizing real-time assistance where browser state exists.
3) The "Ghost Runner" Offline Queue: Decouple Review From Live Tab Execution
Review flows become expensive when they require reopening full portal sessions for every pending item.
The solution I settled on was a Ghost Runner model: capture a structured form snapshot once, then review asynchronously from stored data.
Snapshot model
At discovery time, serialize form structure into JSON artifacts containing:
- normalized field identities,
- labels and semantic category hints,
- control type such as text, select, radio, file, or date,
- requiredness and validation hints,
- option sets where relevant,
- capture metadata such as portal, timestamp, and confidence signals.
This artifact is enough to drive a pending-review workflow without maintaining live tabs for every queue item.
Why this is a free-tier multiplier
It separates three concerns that are usually tightly coupled:
- Discovery: expensive, DOM-dependent, timing-sensitive.
- Review: user-facing, asynchronous, often non-urgent.
- Execution: high-confidence action phase.
Without decoupling, each review interaction re-pays the full browser orchestration cost. With snapshots, review becomes cheap and mostly read-oriented.
Engineering constraints you cannot skip
Offline queue review is only safe with replay guards:
- snapshot freshness windows,
- schema versioning,
- selector drift detection,
- confidence thresholds for automatic replay,
- forced recapture when drift exceeds tolerance.
Otherwise, "offline review" degrades into stale-plan execution.
The broader pattern
Ghost Runner is not just a user-interface feature. It is a resource strategy.
Capture expensive context once. Reuse it across control surfaces. Execute only when you have enough confidence and active runtime context.
That pattern applies beyond job applications to any browser automation workflow with intermittent human approval.
4) Batch Persistence Strategy: Control Write Rate or Lose the System
Even after moving orchestration client-side, you can still fail by writing too frequently.
The governing principle is simple:
Event granularity should not dictate persistence granularity.
Problem: write amplification and trigger pressure
If every micro-event is persisted, you accumulate:
- high-frequency writes,
- trigger fan-out,
- hot-row contention,
- rate-limit collisions,
- retry cascades that generate even more writes.
This compounds fast on free-tier databases.
Tactic 1: local buffering, threshold-based flush
Keep high-resolution activity local and persist summarized checkpoints.
A practical strategy:
- append granular events to local buffer,
- flush on thresholds such as count, time, or terminal state,
- coalesce duplicate intermediate states before commit.
Conceptually:
append(event);
if (bufferSize >= MAX || elapsed >= FLUSH_MS || state.isTerminal) {
pushBatch(compact(buffer));
clear();
}
This turns a noisy event stream into a manageable write pattern.
Tactic 2: exponential backoff with jitter on transient failures
Retries should reduce pressure, not amplify it.
Transient responses such as 429, 503, or network interruptions need:
- bounded retry counts,
- exponential delays,
- jitter to avoid synchronized retry spikes,
- terminal fallback when attempts are exhausted.
In one extraction path, this pattern was necessary to avoid thundering-herd behavior when upstream services degraded.
Tactic 3: circuit breaking for unstable dependencies
When local AI or remote extraction dependencies repeatedly fail, continued retries across the entire pipeline create cascading instability.
Circuit breakers provide a controlled pause:
- open after failure threshold,
- cooldown window,
- half-open probe,
- close on success.
This prevents error bursts from becoming persistent write storms.
Tactic 4: idempotency and dedupe at write boundaries
Batching and retries only work if replays are safe.
You need explicit replay-safe semantics:
- operation IDs,
- canonical identity keys such as normalized URL or job ID,
- dedupe checks before insert or update,
- monotonic state transitions.
Without idempotency, retries are indistinguishable from duplication.
With idempotency, retries become a resilience tool instead of a data-quality risk.
5) Conclusion: Free-Tier Viability Is an Architecture Decision
If your product is browser-native and orchestration-heavy, infrastructure limits are not a late-stage optimization problem. They are first-order architecture constraints.
Client-dominant orchestration works because it aligns control with observability:
- browser logic executes where browser state is available,
- backend stores durable truth instead of micromanaging control flow,
- persistence is batched and replay-safe,
- retries are adaptive, bounded, and pressure-aware.
This is the difference between "we can demo automation" and "we can operate automation economically."
For bootstrapped teams on Supabase and Vercel free tier, that distinction is existential.
The durable lesson is straightforward: stop treating your backend like a puppeteer for tab state. Use it as a durable coordination layer. Let the client run the loop.
That architecture is not just cheaper. It is usually more correct.