Table of Links
- Abstract and Introduction
- Related Work
- Feedback Mechanisms
- The NewsUnfold Platform
- Results
- Discussion
- Conclusion
- Acknowledgments and References
A. Feedback Mechanism Study Texts
B. Detailed UX Survey Results for NewsUnfold
C. Material Bias and Demographics of Feedback Mechanism Study
3 Feedback Mechanisms
As the evaluation of feedback mechanisms for media bias re- mains unexplored, in a preliminary study, we design and as- sess two HITL feedback mechanisms for their suitability for data collection. Using sentences from news articles labeled by the classifier from Spinde, Hamborg, and Gipp (2020), we compare the mechanisms Highlights, Comparison, and a control group without visual highlights. Our analysis focuses on (1) dataset quality, assessed using Krippendorff’s α; (2) engagement, quantified by feedback given on each sentence6; (3) agreement with expert annotations, evaluated through F1 scores; and (4) feedback efficiency, measured by the time required in combination with engagement and agreement.
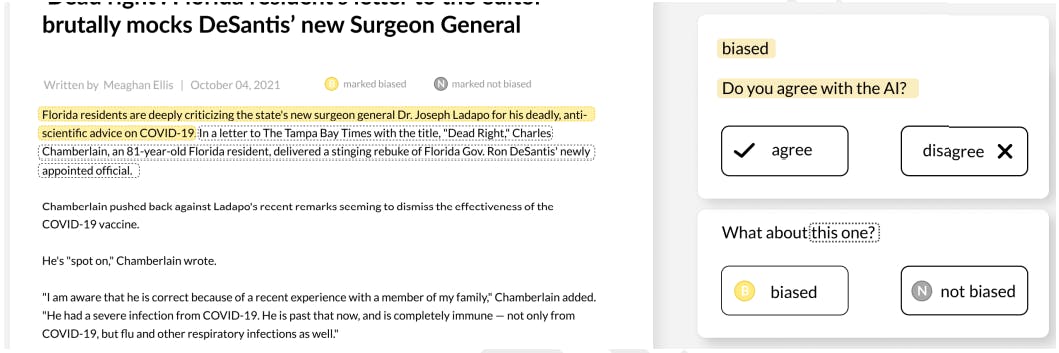
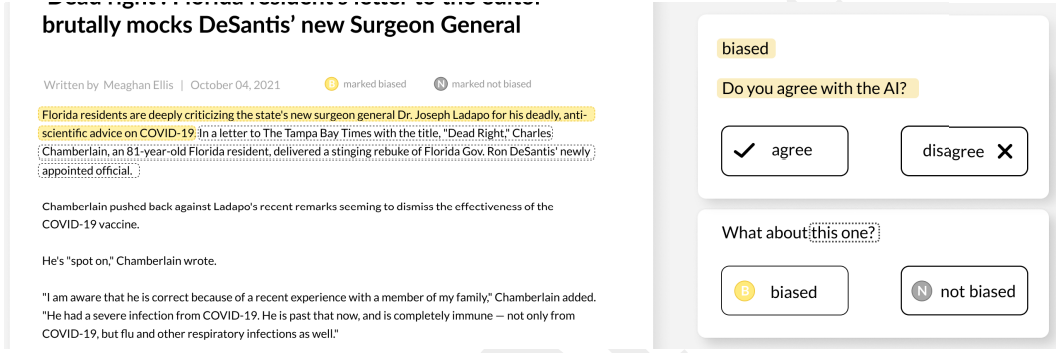
In the Highlights mechanism, biased sentences are col- ored yellow, and non-biased ones are grey, inspired by Spinde et al. (2022). Participants indicate their agreement or disagreement with these classifications through a floating module (Figure 2). The Comparison mechanism dis- plays sentence pairs. For the first sentence, participants pro- vide feedback on the AI’s classification as in Highlights. The second sentence has no color coding, prompting users with ”What do you think?” (Figure 3), thereby aiming to foster an independent bias assessment and mitigate anchoring effects. Participants in the control group do not see any highlights, solely encountering the feedback module with the second question from Comparison.
We use the BABE classifier trained by Spinde et al. (2021b) to generate the sentence labels and highlights. Currently, the classifier showcases the highest performance by fine-tuning the large language model RoBERTa with an extensive dataset on linguistic bias annotated by experts on both sentence and word levels. The BABE-based model on Huggingface[7] generates the probability of a sentence being biased or not biased for each article. We accordingly assign the label with the higher probability.
Study Design
To assess the two mechanisms, we recruit 240 participants, balanced regarding gender, from Prolific.[8] On the study website built for this purpose, depicted in Figure 13, they view two articles from different political orientations paired with one feedback mechanism per group. During the study, users freely determine their annotation count and time spent, with a progress bar showing the number of annotated sentences. Not interacting with any sentences prompts a pop-up, but they can click ’next’ to proceed.

We guarantee GDPR conformity through a preliminary data processing agreement. A demographic survey and

an introduction to media bias follow (Appendix A). A post-introduction attention test confirms participants’ understanding of media bias, which, if failed twice, results in study exclusion. Then, participants read through a description of the study task and proceed to give feedback on the two articles. Lastly, a concluding trustworthiness question ensures data reliability. If participants clicked through the study inattentively, they could indicate that their data is not usable for research (Draws et al. 2021) while still receiving full pay (Spinde et al. 2022).
Results
The 240 participants in the study spent an average of 11:24 minutes, with a compensation rate of £7.89/hr. Twelve participants failed the attention test once, but only one was excluded for a second failure. We further excluded 33 participants who flagged their data as unsuitable for research. Therefore, the analysis includes data from 206 participants: 69 control group participants, 66 Comparison group participants, and 71 Highlights group participants (p = .84, f = .23, α = .05). 104 participants identified as female, 99 as male, and 3 as other, with an average age of 36.62 years (SD = 13.74). The sample, on average, exhibits a left slant (Figure 11 and Figure 12) with higher education (Figure 7). 196 participants indicated advanced English levels, 9 inter- mediate, and 1 beginner (Figure 9). News reading frequency averaged around once a day (Figure 10).
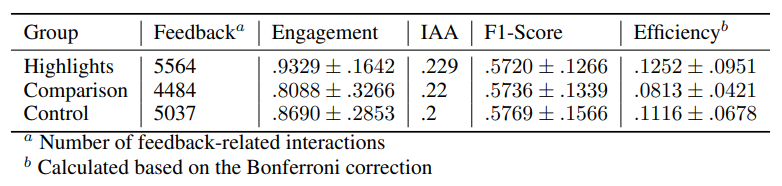
Notably, we observe a high overall engagement, with even the least annotated sentences receiving feedback from 70% of the participants. We detail the results of the feedback mechanism study, including engagement, IAA, F1 scores, and efficiency, in Table 1. The Highlights group exhibits higher engagement than the Comparison group, containing more collected data. Also, Highlights demonstrates higher efficiency by collecting more feedback data in less time without compromising quality measured by IAA and agree- ment with the expert standard.
The increases in engagement and efficiency are significant at a .05 significance level. Due to variance inhomogeneity indicated by a significant Levene test (p <.05), we applied Welch’s ANOVA for unequal variances. Post-hoc HolmBonferroni adjustments revealed significant differences between the CONTROL and HIGHLIGHTS groups, with p <.0167 for efficiency and p <.025 for engagement. The Games-Howell post-hoc test confirmed these results.As in previous research, IAA and F1 scores from crowdsourcers are low due to the complex and subjective task (Spinde et al. 2021c). F1 score differences are not significant (ANOVA
with Holm-Bonferroni, p >.05). Given the comparable IAA and F1 scores across groups, we integrate Highlights within NewsUnfold to optimize data collection efficiency.
Authors:
(1) Smi Hinterreiter;
(2) Martin Wessel;
(3) Fabian Schliski;
(4) Isao Echizen;
(5) Marc Erich Latoschik;
(6) Timo Spinde.
This paper is available on arxiv under CC0 1.0 license.
[6] Readers can modify their annotations at any time; however, each unique sentence annotation counts as a single interaction for our feedback metric.
[7] https://huggingface.co/mediabiasgroup/da-roberta-babe-ft
[8] https://www.prolific.co
[9] Experts have at least six months experience in media bias. Consensus was achieved through majority or discussion.
[story continues]
tags