
If you use AI for deep coding tasks or prolonged conversations, you have probably watched the output is complete nonsense. This is the classic "AI hallucination." In extended sessions, these errors are heavily driven by the limits of the AI's memory, known as the context window. To understand why your AI assistant eventually loses the plot, we need to examine three key factors: context window truncation, attention dilution, and the core nature of AI prediction.
Context Window truncation - In simplest form, imagine context window is like conveyor belt can hold only 100 words, as you add next 10 words to it, it truncates (forgetting) the first 10 words.
Attention Dilution - Even with large token window, the model may hallucinate because attention is spread too thin. It probably mix two different sections of the information to the response
The nature of predication - Fundamentally, LLMs are built to patterns but not to verify facts. In case, given prompts is ambiguous, model priority is to provide plausible answer that matches the patterns it learned from billions of lines of text.
There have been a number of improvements made to overcome "Context Rot." While advanced techniques like context condensation and context compaction are gaining traction, the most common industry solution has simply been to increase the raw size of the context window.
Recent examples of this include:
- Google's Gemini 3 Pro and Gemini 3 Flash: Up to 1 million tokens.
- Anthropic's Claude Opus 4.6: Scaling up to a 1 million token limit.
- OpenAI's GPT-5.2: Expanding its memory to a 400,000 token window.
- Alibaba's Qwen3-Coder-480B: Natively supporting 256K, but extendible up to 1 million tokens.
Recursive Language Model
RLMs address the long-context problem at the inference-time (in other words, when someone is actively using the AI to get answers). Instead of forcing a massive wall of text into a constrained context window, the RLM treats the prompt like a virtual file system. It interacts with the input as an external environment. By chopping a massive workload into smaller, manageable sub-tasks, the model recursively calls itself to process the data efficiently.
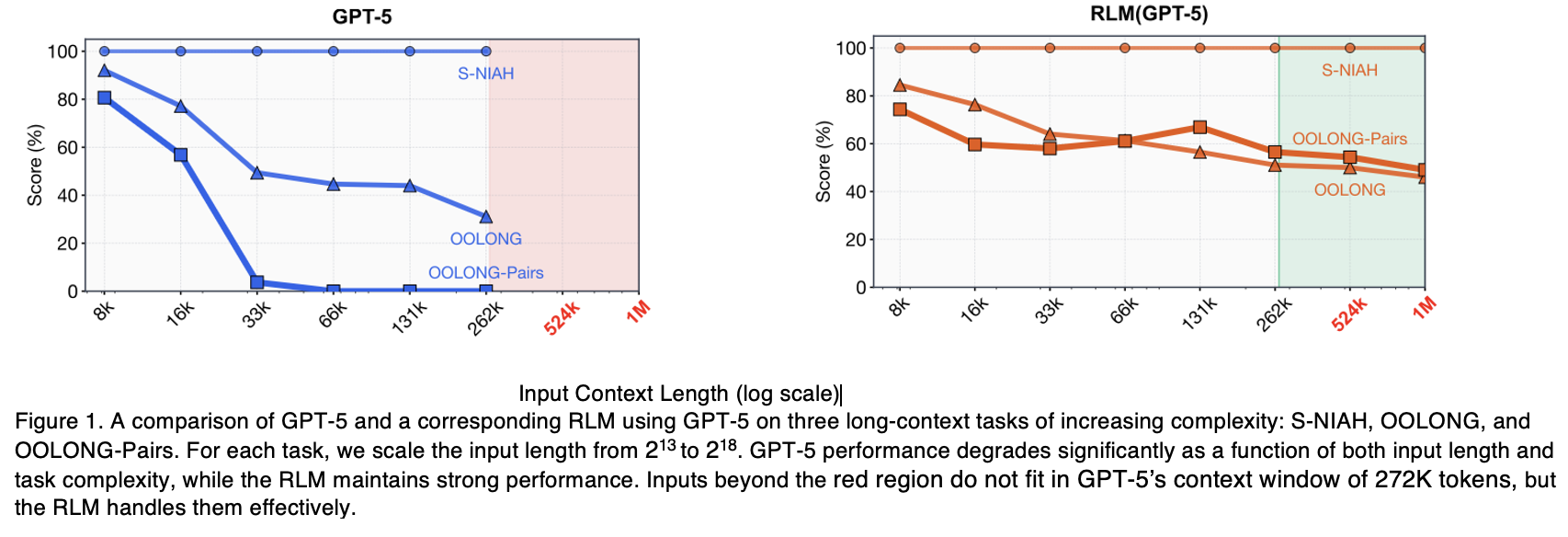
The research paper provides a snapshot comparing standard GPT-5 with an RLM-enabled GPT-5. As the context size scales up, the RLM consistently outperforms the base model or remains highly stable.
The experiments measured performance across several distinct task types:
- S-NIAH (Single Needle In A Haystack): Finding a specific phrase or number hidden within a massive dataset of unrelated text.
- OOLONG Benchmark: Requiring the model to analyze every individual chunk of a massive document and aggregate those chunks to form a final answer.
- OOLONG-Pairs Benchmark: Forcing the model to perform quadratic reasoning. It must compare every single piece of information in the document against every other piece.
Idea behind RLM
In a traditional setup, when a user enters a prompt, a tokenizer converts the text into tokens. These tokens are then fed directly into the Transformer model's context window for processing. With the RLM, this paradigm shifts entirely. The user input is not fed directly into the Transformer. Instead, it is treated as an external environment that the LLM can interact with recursively.
The key mechanism works like this. Given a prompt, the RLM initializes a Read-Eval-Print Loop (REPL) programming environment and assigns the massive prompt as the value of a variable. The RLM then provides the base language model with general context about this new REPL environment. The model understands this structure and writes executable code to read the variable, slice into manageable sub-tasks, and process it through recursive calls.
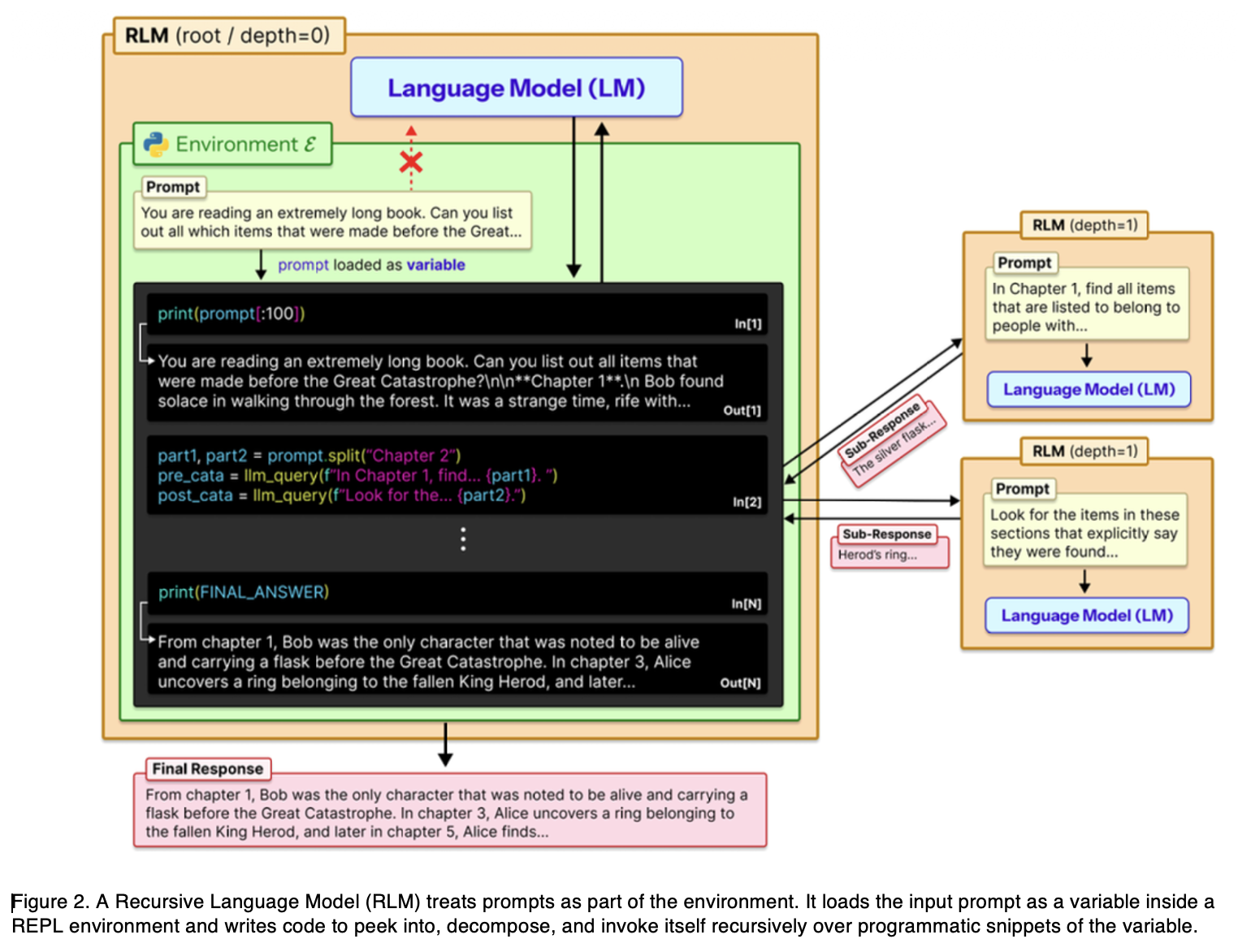
In practice, RLM acts as a wrapper around the base language model. It intercepts the user input, places it into the REPL environment, and delegates the workload. The model then creates sub-tasks to work through the data. This architecture enables unbounded input tokens, unbounded output tokens, and unbounded semantic work.
"Unbounded semantic work" means the model can maintain deep, complex, and comprehensive reasoning across the entire dataset, regardless of how large the underlying information grows. Ultimately, this unbounded approach opens the door for higher accuracy at a lower computational cost.
Key Observations on RLM Performance:
Recent experiments testing RLMs against modern frontier models like OpenAI's GPT-5 and Alibaba's Qwen3-Coder revealed several advantages:
- Massive scale without losing the Context: RLMs can process upwards of 10 million tokens and still outperform base models on long-context tasks. For many, this massive scale is a game changer, directly improving both reasoning capabilities and overall cost efficiency.
- The RLM architecture splits the workload into two distinct mechanisms. The REPL environment is what handles massive input length by offloading the context into a programmable space. And the recursive sub-calling feature is what gives RLMs their edge on information-dense tasks, such as OOLONG and OOLONG-Pairs, where complex semantic reasoning is required.
- As input length and problem complexity increases, standard AI performance drops proportionally. RLMs, however, are built to scale gracefully, maintaining high accuracy exactly where even the most advanced frontier models begin to degrade.
- On average, the inference cost of an RLM is comparable to a standard base model. However, one should note that costs can vary significantly from run to run. Because the model dynamically adjusts the number of sub-calls based on the complexity of the task, the exact cost of an individual prompt is less predictable.
- The RLM architecture is fundamentally model-agnostic, serving as a flexible inference strategy. Yet, because underlying models possess different training backgrounds, they can exhibit distinct behaviors when deployed as an RLM, taking varying approaches to context management and sub-call frequency.
Current Limitations and What is Next
While RLMs offer a massive improvement in context scaling, it comes with practical engineering trade-offs. Currently, architecture is limited to a recursion depth of one, and because sub-calls execute synchronously, processing can take minutes. Further, the dynamic nature of these sub-calls means runtime and cost can be unpredictable for any single query.
Future iterations will likely introduce asynchronous parallel processing to reduce latency, enable hierarchical recursion for deeper reasoning, and lastly, feature models natively trained from the ground up to operate within the RLM architecture.
Final Thoughts
Recursive Language Models (RLMs) represent a fundamental paradigm shift in how we handle prompt ingestion and the large context window problem. Rather than supplying massive input into a fixed internal memory, RLMs offload that context to an external programmable environment. By enabling theoretically unbounded lengths on both inputs and outputs, this approach dramatically scales the effective reasoning power of AI without inflating compute costs.
The researchers have already successfully post-trained the first natively recursive model, proving that this is not just a temporary scaffolding trick. As structural constraints evolve, the next wave of foundational models will likely rely on these principles to solve memory limitations natively, treating context management much like a highly efficient distributed system.
For those interested in diving deeper into the architecture and benchmarks, you can read the full MIT research paper here: https://arxiv.org/pdf/2512.24601
[story continues]
tags