
Why Cross-Modal + Cross-Domain = Smarter AI
In an age where AI needs to not just recognize a cat, but also read about it and generalize that knowledge to wild tigers in a different dataset, we need two things:
- Cross-modal alignment – understanding relationships across text, images, audio, etc.
- Cross-domain learning – applying knowledge from one domain (like product images) to another (like real-world photos).
Let’s break this down.
Understanding Cross-Modal Alignment (with Code)
The goal here is to embed different types of data—say, an image and its text caption—into a shared space where their representations are directly comparable.
The Idea
Imagine you have:
- An image:
xᵛ ∈ V - A text:
xᵗ ∈ T
You want to learn two functions:
fᵥ(V) → ℝᵈfor imagesfₜ(T) → ℝᵈfor text
...such that fᵥ(xᵛ) and fₜ(xᵗ) are close if they belong together.
Contrastive Learning: The Workhorse
One powerful loss function for this is InfoNCE, commonly used in CLIP. Here's the formulation for one direction (image → text):
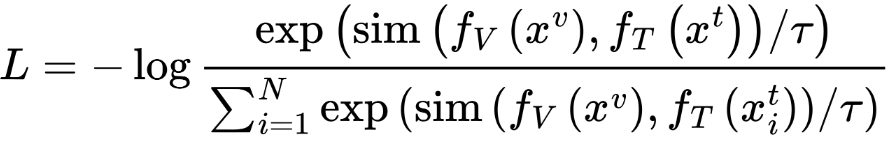
Where:
sim()is cosine similarity or dot productτis a temperature parameter- The denominator includes all text embeddings in the batch (i.e., both positive and negatives)
In practice, CLIP applies the loss in both directions, image→text and text→image. Here's how that typically looks in PyTorch:
logits_per_image = img_emb @ txt_emb.T / tau
logits_per_text = txt_emb @ img_emb.T / tau
labels = torch.arange(batch_size).to(device)
loss_i2t = F.cross_entropy(logits_per_image, labels)
loss_t2i = F.cross_entropy(logits_per_text, labels)
loss = (loss_i2t + loss_t2i) / 2
A Simplified CLIP-Inspired Model
Here’s a bite-sized version of OpenAI’s CLIP model that aligns images and text.
import torch
import torch.nn as nn
import torchvision.models as models
from transformers import BertModel
import numpy as np
class MiniCLIP(nn.Module):
def __init__(self, embed_dim=512):
super().__init__()
# Visual encoder (ResNet-based)
base_cnn = models.resnet18(pretrained=True)
self.visual_encoder = nn.Sequential(*list(base_cnn.children())[:-1])
self.visual_fc = nn.Linear(base_cnn.fc.in_features, embed_dim)
# Text encoder (BERT)
self.text_encoder = BertModel.from_pretrained('bert-base-uncased')
self.text_fc = nn.Linear(self.text_encoder.config.hidden_size, embed_dim)
# Learnable temperature
self.logit_scale = nn.Parameter(torch.ones([]) * np.log(1 / 0.07))
def forward(self, images, input_ids, attention_mask):
img_feat = self.visual_encoder(images).squeeze()
img_embed = self.visual_fc(img_feat)
txt_feat = self.text_encoder(input_ids=input_ids, attention_mask=attention_mask).pooler_output
txt_embed = self.text_fc(txt_feat)
# Normalize embeddings
img_embed = img_embed / img_embed.norm(dim=-1, keepdim=True)
txt_embed = txt_embed / txt_embed.norm(dim=-1, keepdim=True)
return img_embed, txt_embed
Cross-Domain Learning: Theory and MMD Loss
Cross-domain learning is all about transferring what a model learns in one domain (the source) to another, possibly quite different, domain (the target). This is especially useful when labeled data is scarce in the target domain — something deep learning models struggle with.
Transfer Learning vs. Domain Adaptation
While transfer learning fine-tunes a pre-trained model from one domain to another, domain adaptation goes one step further: it reduces the gap in data distributions between domains so that a model trained on the source can generalize to the target.
MMD Loss: Maximum Mean Discrepancy
One popular way to minimize the distribution gap is the MMD loss — short for Maximum Mean Discrepancy. It measures how far apart the source and target domain distributions are in a high-dimensional feature space.
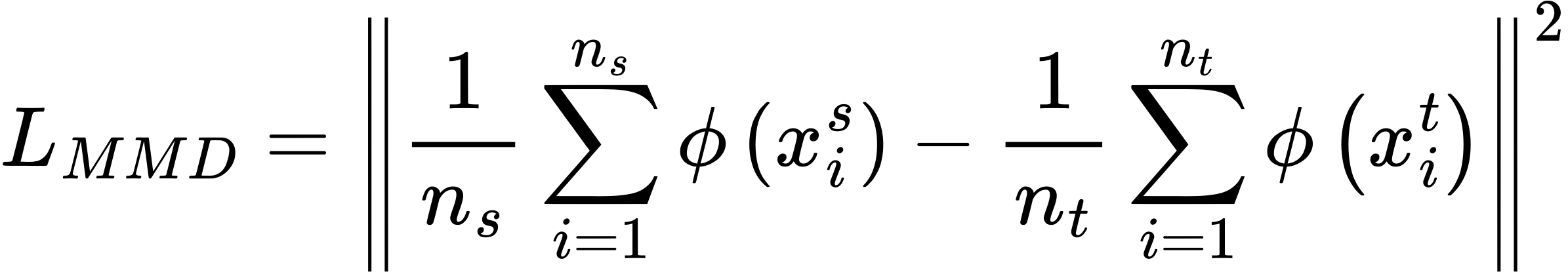
Where:
- ϕ(⋅) maps the data into a reproducing kernel Hilbert space (RKHS)
MMD essentially says: If the average representation of source and target data are close in some space, the model will generalize better.
What About Different Domains?
Now that we’ve laid the theoretical foundation, let’s look at how cross-domain learning applies in real scenarios.
Cross-domain learning becomes especially valuable when the data distribution shifts — for example, when models trained on high-quality studio product images are used on blurry, real-world smartphone photos. Despite training on one domain, we expect the model to perform well in a different one.
This is where domain adaptation comes into play. You can pair contrastive techniques with domain-invariant feature learning (like MMD loss or adversarial training) to ensure the model generalizes across these distribution gaps.
The next section introduces one practical approach to this: Domain-Adversarial Neural Networks (DANN).
Let’s say you trained a model on Amazon product images. Can it recognize the same products photographed in a real-world store? That’s where cross-domain learning steps in.
Domain Adaptation via Adversarial Learning
One elegant solution: make your features domain-invariant. Enter DANN—Domain-Adversarial Neural Networks.
DANN in a Nutshell
You train a feature extractor to fool a domain classifier. Meanwhile, your label predictor keeps doing its thing.
class DomainClassifier(nn.Module):
def __init__(self):
super().__init__()
self.model = nn.Sequential(
nn.Linear(800, 100), # adjust to match flattened features
nn.ReLU(),
nn.Linear(100, 2) # binary: source vs target domain
)
def forward(self, x):
return self.model(x.view(x.size(0), -1))
To make it truly adversarial, use a gradient reversal layer (not shown above) so the domain classifier learns, while the feature extractor tries to confuse it.
Putting It Together: Cross-Modal and Cross-Domain
Why stop at one challenge? Some tasks—like multilingual image retrieval across countries—need both.
Combined Loss Function
Here’s a sample loss that merges contrastive (alignment) and adversarial (domain adaptation) objectives:
def combined_loss(img_emb, txt_emb, domain_logits, domain_labels, λ=0.5):
contrastive = -torch.mean((img_emb * txt_emb).sum(dim=-1)) # dot product loss
domain = nn.CrossEntropyLoss()(domain_logits, domain_labels)
return contrastive + λ * domain
Benchmarks & Datasets
|
Task |
Dataset |
Why Use It |
|---|---|---|
|
Cross-modal alignment |
COCO, Flickr30K |
Image-caption pairs for retrieval tasks |
|
Cross-domain learning |
Office-31, VisDA |
Domain-shift experiments (Amazon → Webcam etc) |
Experiments show that combining both strategies improves retrieval accuracy and classification robustness—especially in low-data or out-of-distribution scenarios.
Final Thoughts
Cross-modal alignment helps machines connect the dots between different types of data. Cross-domain learning ensures they stay accurate when the context changes.
Together, they form a powerful combo for building generalizable AI systems. The next frontier? Add more modalities (like audio or tabular data), fewer labels, and tougher domains.
[story continues]
tags