Authors:
(1) Liangchen Luo, Google Research (luolc@google.com);
(2) Zi Lin, UC San Diego;
(3) Yinxiao Liu, Google Research;
(4) Yun Zhu, Google Research;
(5) Jingbo Shang, UC San Diego;
(6) Lei Meng, Google Research (leimeng@google.com).
Table of Links
B. CriticBench: Sources of Queries
C. CriticBench: Data Generation Details
D. CriticBench: Data Selection Details
E. CriticBench: Statistics and Examples
ABSTRACT
Critical thinking is essential for rational decision-making and problem-solving. This skill hinges on the ability to provide precise and reasoned critiques and is a hallmark of human intelligence. In the era of large language models (LLMs), this study explores the ability of LLMs to deliver accurate critiques across various tasks. We are interested in this topic as a capable critic model could not only serve as a reliable evaluator, but also as a source of supervised signals for model tuning. Particularly, if a model can self-critique, it has the potential for autonomous self-improvement. To examine this, we introduce a unified evaluation framework for assessing the critique abilities of LLMs. We develop a benchmark called CRITICBENCH, which comprises 3K high-quality natural language queries and corresponding model responses; and annotate the correctness of these responses. The benchmark cover tasks such as math problem-solving, code completion, and question answering. We evaluate multiple LLMs on the collected dataset and our analysis reveals several noteworthy insights: (1) Critique is generally challenging for most LLMs, and this capability often emerges only when models are sufficiently large. (2) In particular, self-critique is especially difficult. Even top-performing LLMs struggle to achieve satisfactory performance. (3) Models tend to have lower critique accuracy on problems where they are most uncertain. To this end, we introduce a simple yet effective baseline named self-check, which leverages self-critique to improve task performance for various models. We hope this study serves as an initial exploration into understanding the critique abilities of LLMs, and aims to inform future research, including the development of more proficient critic models and the application of critiques across diverse tasks.
1 INTRODUCTION
“Self-criticism is an art not many are qualified to practice.” — Joyce Carol Oates
Large language models (LLMs) have demonstrated impressive capacities in a wide range of tasks (Google et al., 2023; OpenAI, 2023). Consequently, the evaluation of LLMs has shifted focus from basic sentence coherence to more advanced capabilities, e.g., knowledge acquisition and logical reasoning (Hendrycks et al., 2021; BIG-Bench authors, 2023). One capability that is overlooked in current evaluation frameworks is the ability of critical thinking, which is an important hallmark of human intelligence that requires logic, reasoning, and knowledge. This ability ensures that LLMs can provide precise and reasoned critiques towards model responses. A model with robust critique ability can identify potential misinformation, errors or context misalignment in model outputs, thereby showing their specific shortcomings that can serve as a feedback for improvement. While recent studies have used LLMs for various forms of critique across diverse applications (Madaan et al., 2023; Saunders et al., 2022; Shinn et al., 2023), they primarily focus on advancing the state of the art for specific tasks instead of providing a comprehensive assessment of critique ability.
To address this gap, we propose a standardized benchmark CRITICBENCH to assess the critique abilities of LLMs in diverse tasks. We define a model’s critique ability as “the capacity to identify flaws in model responses to queries”. Figure 1 provides an example of a flaw in the response to a query, and how it is identified by a critique. The benchmark consists of query-response-judgment triplets. During evaluation, we always prompt a model to perform a chain-of-thought analysis to

identify flaws and explain the reason; and then provide a final judgment on the response’s correctness. Comparing this judgment to ground-truth labels allows us to explicitly evaluate a model’s critique accuracy and implicitly assess its analytical process toward an accurate judgment.
To construct CRITICBENCH (Section 3), we gather natural language queries from multiple scientific benchmarks, covering tasks like math problem-solving (Cobbe et al., 2021), code completion (Chen et al., 2021), and question answering (Lin et al., 2021). We employ PaLM-2 models (Google et al., 2023) of various sizes to generate responses, which are then annotated for correctness. To ensure data quality, a complexity-based selection strategy (Fu et al., 2023b) is used to identify high-quality responses among the candidates. Furthermore, to select queries of suitable difficulty, we introduce an auxiliary metric that quantifies a model’s certainty regarding a query. Such a metric can help select queries that poses a moderate level of challenge to models. As a result, we collect 3K highquality examples from an initial pool of 780K candidates to form the benchmark mixture. This data collection method is both scalable and generalizable, requiring no extra human intervention and suitable for a variety of tasks.
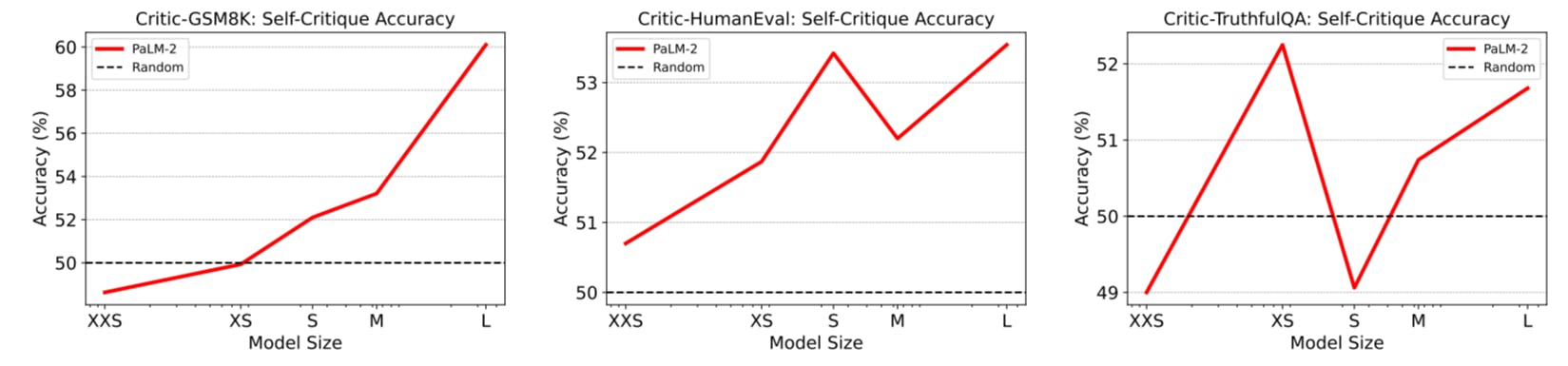
Given CRITICBENCH, we can now analyze the critique abilities of LLMs (Section 4). There are specific aspects that particularly interest us. First, critique inherently involves logic, reasoning, and knowledge, making it a complex process even for humans. Therefore, it is not clear how well LLMs can emulate this capability. It is possible that critique ability is yet another emergent ability, i.e., ability not present in smaller-scale models that are present in larger-scale models (Jang, 2023). Investigating how critique ability scales with model size could offer insights into model size selection and whether fine-tuning is needed for smaller models (Section 4.1). Additionally, self-critique, i.e., when a model critiques its own outputs, is a format of critique of particular interest to us, as it is relevant to a model’s potential for self-improvement (Section 4.2). Finally, we are also interested in what types of queries pose more challenges for LLMs to critique (Section 4.3).
To investigate these aspects, we evaluate various widely-used LLMs on CRITICBENCH and reveal several intriguing findings: (1) Critique tasks pose a considerable challenge for LLMs. Only largescale models exhibit performance with a notable difference from a random guess baseline, indicating that the capacity for critique serves as an emergent indicator of a capable LLM. (2) Self-critique, i.e., a model critiquing its own output, is particularly difficult. Even the strongest LLMs struggle to achieve satisfactory performance. (3) A challenging query is not only difficult for LLMs to directly answer correctly, but also poses a challenge in assessing an answer’s correctness to that query.
To this end, we also propose a simple yet effective baseline called self-check (Section 5). The basic idea is to prompt the model to confirm the accuracy of their generated answers by self-critique before presenting them. The method consistently enhances the baseline performance (Wang et al., 2023) on math word problems across multiple models, achieving an average of 9.55% error reduction rate, which demonstrates the potential utility of critiques from LLMs.
Our contributions are three-fold:
• New Benchmark CRITICBENCH is the first benchmark that comprehensively assesses the critique abilities of LLMs across diverse tasks and scenarios, which fills a gap in the current LLM evaluation framework by introducing this important ability.
• New Findings Our findings on CRITICBENCH underscore the nuances and depth of LLM’s critique abilities (Section 4). These revelations enhance our understanding of the inherent complexities in LLMs and emphasize the need for advanced training and evaluation techniques.
• New Capacity The proposed self-check method (Section 5) not only advances the performance on math word problems over the baseline, but also indicates the new capacity of critique ability with LLMs, which is a fruitful avenue for LLM’s self-improvement strategies.
2 DEFINITION OF CRITIQUE ABILITY
The concept of critique has diverse interpretations and is often applied informally in everyday contexts. Recent research employs large language models to offer critiques across multiple applications (Madaan et al., 2023; Paul et al., 2023; Saunders et al., 2022; Shinn et al., 2023), resulting in varying formats and requirements for their “critiques”. These studies primarily aim to enhance performance in specific tasks, neglecting to clarify the meaning of the term critique. In this paper, we consider the definition of a language model’s critique ability as
the capacity to identify flaws in model responses to queries.
These flaws can differ depending on the task, ranging from incorrect reasoning or calculation in mathematical problems to syntax errors in code completion.
When a model self-assesses its own outputs, we term this as self-critique, a notion that particularly intrigues us. If models can engage in self-critique and reflection, they can potentially do selfimprovement, requiring minimal human intervention. On the risky side, this autonomy also raises concerns about reduced human oversight (Bowman et al., 2022). Yet we posit that self-critique may still remain a challenging capability for large language models, as a flaw-aware model would logically not produce faulty output in the first place (Saunders et al., 2022).
This paper is
[story continues]
tags