
Scalability of Databases. What is the difference between horizontal and vertical scaling? Which is better and why?
We are generating data everyday. And so are the billions of people in the world. Every database has to be scaled to address the huge amount of data being generated each day.
In short, a database needs to be scalable so that it is available at all times. When the memory of the database is drained, or when it cannot handle multiple requests, it is not scalable.
Scalability is the capability of a system, network, or process to handle a growing amount of work, or its potential to be enlarged to accommodate that growth.
Scaling can be classified into Vertical and Horizontal Scaling.
Elasticity
Elasticity is the degree to which a system can adapt to workload changes by provisioning and de-provisioning resources in an on-demand manner, such that,
At each point in time the available resources match the current demand as closely as possible. — NuoDB
A system is elastic when it can be easily scaled to address the resource needs of the application under use.
Types of scaling

Source : Turbonomic Blog
Imagine that you are buying a brand new car. You got a Nissan car which can accommodate 4 people in it. Now, say you and 10 of your friends need to go for a vacation. What would you do?
Would you buy a bigger car? — Vertical Scaling
Would you buy one more Nissan car ? — Horizontal Scaling
This is a basic explanation of the two types. Let us learn where each of the type can be used and which is better.
Vertical Scaling — Scale Up
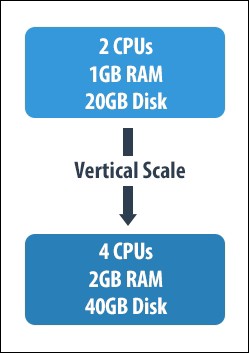
Source : Packt
Vertical Scaling was adopted when the database couldn’t handle the large amount of data.
Suppose you have a database server with 10GB memory and it has exhausted. Now, to handle more data, you buy an expensive server with memory of 2TB. Your server can now handle large amounts of data.
This is called Vertical Scaling. It is buying a single expensive and bigger server.
The process involves adding more power such as CPU and disk power to enhance your storage process.
Now, is this useful?
- Depends on the application and its usage.
Take for example, Instagram. When it was invented, it addressed a small crowd. So, a single server would have been enough. But now, millions of people use the application. It is impossible to buy such an server which can store all the data.
- Secondly, data is meant to be queried too. When a single node faces a lot of queries, it is difficult to handle.
- For a large application involving loads of querying, Vertical Scaling is a definite no-no.
- If your application involves a limited range of users and minimal querying, you can go ahead with this type of scaling.
- Relational databases mostly use vertical scaling.
Advantages
- Simple, since everything exists in a single server. No need to manage multiple instances.
- Performance Gain, because you have faster RAM and memory power on each update.
- Same Code. No change — You need not change your implementation or your code at all.
Disadvantages
- Difficult to perform multiple queries simultaneously.
- Chances of downtime are high, when the server exceeds maximum load.
- Expensive. Hardware resources are costly, after all.
Horizontal Scaling — Scale Out
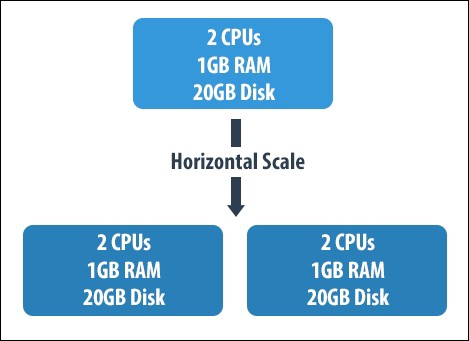
Source : Packt
Horizontal Scaling, as the image depicts is scaling of the server horizontally by adding more machines.
It divides the data set and distributes the data over multiple servers, or shards.
Each shard is an independent database.
Instead of buying a single 2 TB server, you are buying two hundred 10 GB servers.
Vertical scaling focuses on increasing the power and memory, whereas horizontal scaling increases the number of machines.
Same Question. How is it useful?
- Remember the Instagram problem we discussed earlier? Let’s find a solution for it. Suppose, instead of a single server, it purchases multiple machines of the same size and power.
Assume one server stored user profile information, another stored stories and highlights and another stored images.
Now, the query is addressed to specific servers, which reduces the load on the server and gives better performance.
Great, huh?
- If your application involves atomic transactions, it is better you use Vertical Scaling. If your application can allow redundancy and involves less joins, then you can use horizontal scaling.
- NoSQL databases mostly use horizontal scaling. It is less suitable for RDBMS as it relies on strict Consistency and Atomicity rules.
Advantages
- It is cheap compared to vertical scaling.
- Lesser Load, Better performance.
- Chances of downtime are less.
- Resilience and Fault Tolerance.
Disadvantages
- Making joins is difficult, as it may involve cross-server communication.
- Eventual consistency is only possible. It may not be best suited for bank transactions, which happens simultaneously.
- We can’t easily categorize each feature to each server. Sometimes, images may take up more space than a single server can handle.
Why do people opt Horizontal Scaling?
- To put it in simple words, horizontal scaling is elastic. Elasticity as told before is the ability to handle the workload changes.
- Moreover, it is dynamic. You can keep your existing resources online, and add as many servers as you want. Since each of them is independent, it causes no harm.
- Big data is stored mostly in NoSQL databases, which follows horizontal sharding of databases.
This is the reason NoSQL uses horizontal scaling, or sharding.
Since it follows the de-normalization concept, there is no necessity for a single point of truth. It can store duplicates.
For example, if you want to fetch the frequent number of tags used, you can keep a separate table with user ID and the tag used.
NoSQL follows no concept of foreign key or normalization.
Replication to achieve HA( High Availability )
Scaling is to increase our resources to handle data and queries. Replication is to store backups of up-to-date data to overcome failure of nodes.
Replication in RDBMS
- Replication in RDBMS is mostly Master Slave Replication, which involves multiple replicas having a single master.
- The master performs and logs the writes and then passes the updated information to the slaves(replicas).
- The slaves, can perform reads anytime. This is to reduce the load on the master replica.
- When a master node goes down, any one of the replica becomes the master.
The disadvantages to this approach is that, if the master goes down while performing a write, there are chances the information isn’t updated on the slave replicas. So the last transaction might be lost.
Replication in NoSQL
Take Cassandra for example.
- Replication happens in Cassandra using virtual nodes, which randomly contain rows of data.
- The categorization of a particular row to a node happens by hashing the primary key.
- Each node in the cluster has a specified range. The resulting hash value of the row determines its node position.
Consider this example of partition keys and their Murmur3 hash values.
Example data from DataStax documentation
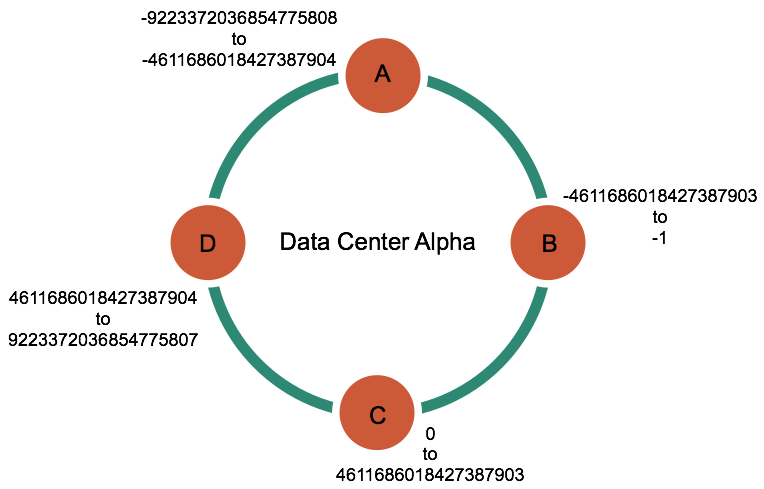
Each data value is stored according to the range value of the node it falls in. Source : DataStax documentation
- There is no master node.
- The read process happens by reading all the replicas, and returning the most up-to-date value. Then a read repair is performed for other values, in case if it is outdated.
I write stories on Life Lessons, Coding and Technology. To read more, follow me on Twitter and Medium.
[story continues]
tags