
Internet-scale distributed systems implement an API rate limiter for high availability and security. Let’s break down the design components of this system.
Requirements
- Throttle requests exceeding the rate limit
- Distributed rate limiter
Data storage
Database schema
The NoSQL document store such as MongoDB is used to store the rate limiting rules and the throttled data
Type of data store
- The NoSQL document store such as MongoDB stores the rate-limiting rules and the throttled data
- The cache server such as Redis stores the rate-limiting rules and throttling data in-memory for faster lookups
- The message queue stores the dropped requests for analytics and auditing purposes
High-level design
-
The cookie, user ID, or IP address is used to identify the client
-
The rate limiter drops the request and returns the status code “429 too many requests” to the client if the throttling threshold is exceeded
-
The rate limiter delegates the request to the API server if the throttling threshold is not exceeded
Throttling type and algorithms
-
Soft throttle: fixed window, token bucket
-
Hard throttle: sliding window, sliding window with counter, leaking bucket
-
Dynamic throttle: all of the above with an additional system query to check for free resources
Workflow
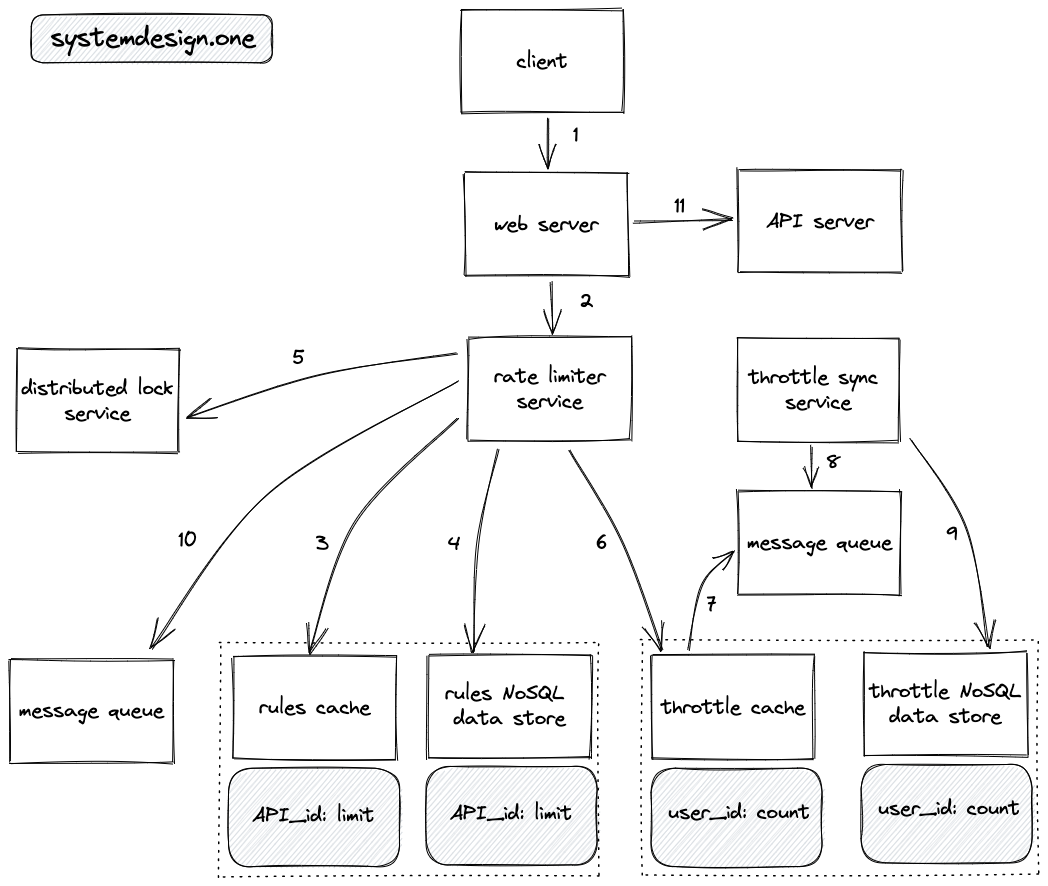
- The client creates an HTTP connection to the web server
- The web server forwards the request to the rate limiter service
- The rate limiter service queries the rules cache to check the rate limit rule for the requested API endpoint
- The read replicas of rules NoSQL data store are queried on a cache miss to identify the rate limit rule
- The distributed lock such as Redis lock is used to handle concurrency when the same user makes multiple requests at the same time in a distributed system
- The rate limiter service queries the throttle cache to verify if the throttle threshold is exceeded
- The throttle cache uses a write-behind (write-back) cache pattern by storing the throttle data on the message queue to improve the latency
- The throttle sync service executes a batch operation to store the throttle data on the message queue to the NoSQL document store
- The NoSQL document stores persist the throttle data for fault tolerance, long-living rate limits, analytics, and auditing
- The dropped requests (throttle threshold exceeded) are stored on the message queue for analytics and auditing
- If the client request is not exceeding the throttle limit, the rate limiter delegates the client request to the API server
- LRU cache eviction is used for cache servers
- HTTP response headers indicate the relevant throttle limit data
- Consistent hashing is used to redirect the request from a user to the same subset of servers
References
- Paul Tarjan, Scaling your API with rate limiters, stripe.com
- Rate-limiting strategies and techniques, cloud.google.com
Also published here.
Featured image source.
[story continues]
tags