
In this article, I aim to share my experience standardizing the ETL process within frameworks like Spark and Flink, particularly for those not using data processing frameworks like dbt.
Context
Data processing is a comprehensive field that encompasses the regular processing of substantial information volumes in both batch and stream modes. These procedures, often referred to as ETL processes, are developed using a variety of programming languages and frameworks.
Typically, the main stages of data processing are as follows:
-
Reading data: Data is collected from various sources for subsequent processing.
-
Transformation: The data undergoes various transformations and manipulations to attain the required structure and format.
-
Writing: The transformed data is then stored in the target storage.
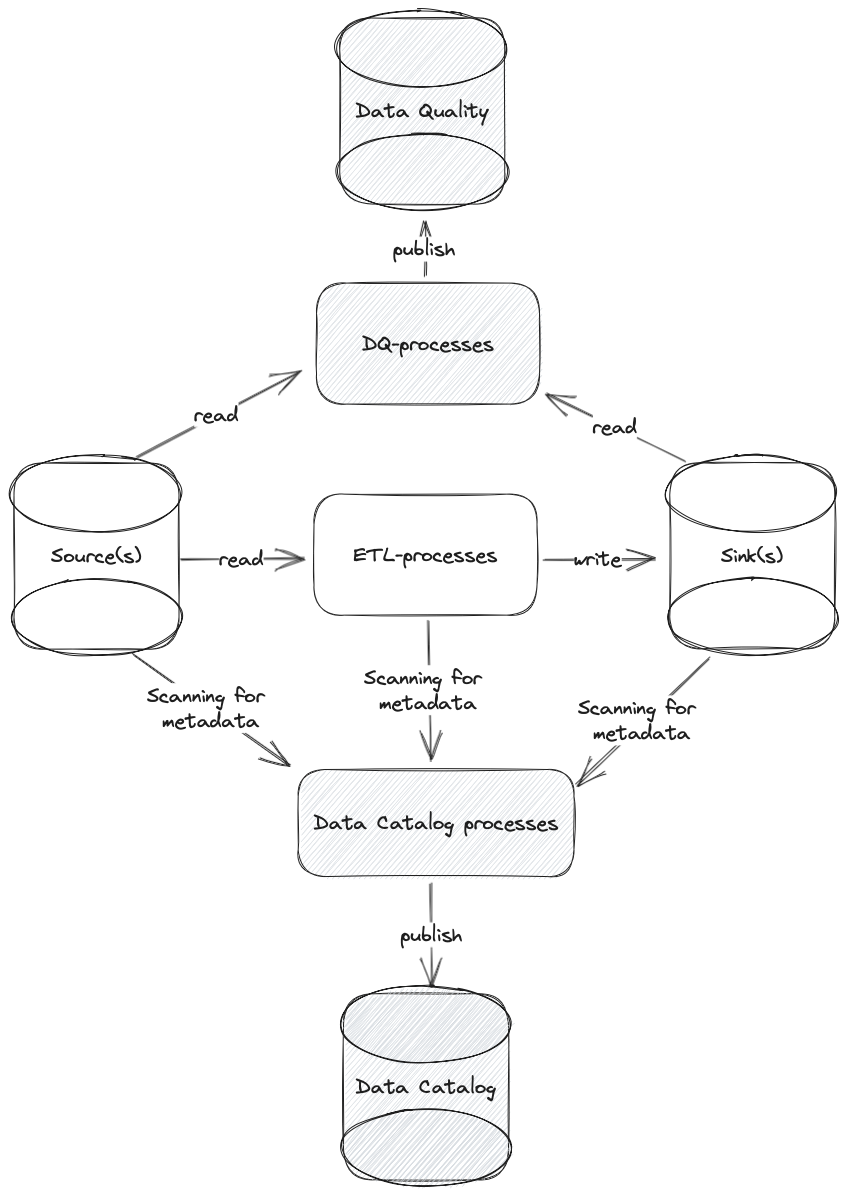
Schematically, it is represented as shown in the diagram:

Challenges
After the main stages are implemented, several other stages can be added to enhance and refine the process:
-
Data quality check: This stage involves verifying data compliance with requirements and expectations, including data cleaning to ensure accuracy and completeness.
-
Data registration in the data catalog: The registration process tracks and documents available data sets. It may also involve data and metadata management for effective data organization.
-
Building data lineage: This allows visualization of relationships between data assets and ETL processes to understand dependencies. It can help identify potential data quality issues and improve overall data quality.
-
Data classification: Additional processing may define the level of data confidentiality and criticality, ensuring proper data protection and security.
Each of the stages mentioned can be implemented using various technologies and tools, allowing flexibility in choosing the right solution for each specific stage of data processing.
Solution
Reading data
The first step in the ETL process involves reading data from the source. Various types of sources may be used at this stage, such as files, databases, message brokers, and more. The data may also come in different formats, such as CSV, JSON, Parquet, Delta, Hudi, etc. Here is some boilerplate code for reading data from these different sources (implemented as Strategy pattern):
from abc import ABC, abstractmethod
from pyspark.sql import SparkSession, DataFrame
# Define the strategy interface
class ReadStrategy(ABC):
@abstractmethod
def read_data(self) -> DataFrame:
pass
# File System Read Strategy - represents a file system reading
class FileSystemReadStrategy(ReadStrategy):
def __init__(self, spark: SparkSession, path: str):
self.spark = spark
self.path = path
@abstractmethod
def read_data(self):
pass
# Implement the strategy for CSV
class CSVReadStrategy(FileSystemReadStrategy):
def read_data(self) -> DataFrame:
return self.spark.read.format("csv").option("header", "true").load(self.path)
# Implement the strategy for Delta
class DeltaReadStrategy(ReadStrategy):
def read_data(self) -> DataFrame:
return self.spark.read.format("delta").load(self.path)
# Implement the strategy for Parquet
class ParquetReadStrategy(ReadStrategy):
def read_data(self) -> DataFrame:
return self.spark.read.format("parquet").load(self.path)
# Context class
class DataReader:
def __init__(self, read_strategy: ReadStrategy):
self.read_strategy = read_strategy
def read(self) -> DataFrame:
return self.read_strategy.read_data()
Usage example:
spark = SparkSession.builder.appName("our-ETL-job").getOrCreate()
path = "path-to-our-data"
src_df = DataReader(DeltaReadStrategy(spark, path)).read()
This approach offers several benefits:
- It enables the alteration of the reading strategy (source format).
- It facilitates the addition of new reading strategies without modifying existing code.
- Each strategy can have its unique parameters. For example, CSV may have a delimiter, while Delta may have a version, etc.
- Instead of providing a path, we can create a dedicated class, like
ReadConfig, which can hold all necessary data reading parameters. - It allows the incorporation of additional logic into strategies without affecting the main code. For instance:
- We can call
input_file_name()by default for a file source. - If we have a data catalog, we can check whether the table exists there and register it if not.
- We can call
- Each strategy can be tested individually.
Transformation
After reading the data, it must be transformed. This can include various operations like filtering, aggregating, and joining. Since the transformation process can be complex and time-consuming, it's crucial to standardize it for ease of understanding. From my experience, using the transform method of the DataFrame API is an effective way to standardize this process. This method lets us chain multiple transformations, enhancing code readability. Each transformation can be declared as a separate pure function, performing a specific transformation, and can be tested independently.
import pyspark.sql.functions as F
from pyspark.sql import DataFrame
desired_columns = ["name", "age", "country"]
def with_country_code(df: DataFrame) -> DataFrame:
return df.withColumn("country_code", F.when(F.col("country") == "USA", "US").otherwise("Other"))
def with_age_category(df: DataFrame) -> DataFrame:
return df.withColumn("age_category", F.when(F.col("age") < 18, "child").when((F.col("age") >= 18) & (F.col("age") < 65), "adult").otherwise("senior"))
def filter_adult(df: DataFrame) -> DataFrame:
return df.filter(F.col("age_category") == "adult")
def select_columns(columns: list) -> callable[[DataFrame], DataFrame]:
def inner(df: DataFrame) -> DataFrame:
return df.select(columns)
return inner
transformed_df = (src_df
.transform(with_country_code)
.transform(with_age_category)
.transform(filter_adult)
.transform(select_columns(desired_columns))
)
Writing
The last stage in the ETL process is writing the transformed data into the target storage, which could be a file system, a database, or a message broker. The loading phase may also incorporate extra steps like data validation, data registration, and data lineage. For this stage, we can apply the same methods as reading data, but with writing strategies.
from abc import ABC, abstractmethod
from pyspark.sql import DataFrame, SparkSession
class WriteStrategy(ABC):
@abstractmethod
def write_data(self, df: DataFrame):
pass
class FileSystemWriteStrategy(WriteStrategy):
def __init__(self, spark: SparkSession, path: str, format: str, mode: str = "overwrite"):
self.spark = spark
self.path = path
self.format = format
self.mode = mode
def write_data(self, df: DataFrame):
df.write.format(self.format).mode(self.mode).save(self.path)
class DataWriter:
def __init__(self, write_strategy: WriteStrategy):
self.write_strategy = write_strategy
def write(self, df: DataFrame):
self.write_strategy.write_data(df)
Usage example:
path = "path-to-our-data"
writer = DataWriter(FileSystemWriteStrategy(spark, path, "delta"))
writer.write(transformed_df)
Conclusion
This implementation standardizes the ETL process, making it more comprehensible and maintainable. It facilitates the addition of new reading and writing strategies without modifying existing code. Each strategy can possess unique parameters, and additional logic can be incorporated into strategies without disrupting the main code. The approach also enables separate testing of each strategy. Moreover, we can introduce additional stages to the ETL process, such as data quality checks, data registration in the data catalog, building data lineage, and data classification.
[story continues]
tags