Table of Links
-
Related Works
2.3 Evaluation benchmarks for code LLMs and 2.4 Evaluation metrics
-
Methodology
-
Evaluation
4.4 Lines of code
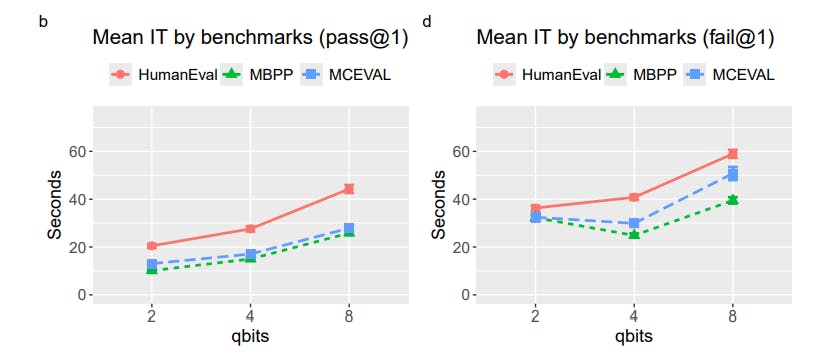
As shown in Fig. 6, lines of codes generated by the models do not differ much between the quantization levels. In generating incorrect solutions, CodeQwen and CodeGemma tended to be more verbose. The correct solutions in HumanEval require more lines of code than in the other two benchmarks. Interestingly, for the correct solutions, MBPP requires slightly more lines of code than MCEVAL while needing less inference time (Fig. 4). Overall, there is no effect of quantization on the number of lines of code generated. However, as depicted by Fig. 7, the time required to generate the same number of lines of code increases with higher precision quantization. This is observed for both the correct and incorrect solutions. This indicates that the increase in inference time in higher precision models is mainly due to longer forward pass time (calculations at the layers) rather than longer output generation time. In simpler terms, the higher precision models spend more time ‘thinking’ before generating output. However, this additional thinking time does not effectively translate into better performance when the 4-bit and 8-bit models are compared (Fig. 1).
4.5 Comparison with FP16 models
Instead of using quantized models, it may be better to use a non-quantized model but with a smaller number of parameters. For this reason, we raised the research question RQ4. We performed the same tests on DeepSeek Coder 1.3B Instruct, CodeGemma 2B, and StarCoder2 3B. The three models were tested at half-precision (FP16). The storage requirements for these models are 2.69GB, 4.40GB, and 6.06GB respectively. When loaded into memory, these models require 2.53GB, 4.44GB, and 5.79GB respectively. These sizes roughly correspond to the sizes of 2-bit, 4-bit, and 8-bit models. No low-parameter models were available for CodeLLama and CodeQwen.
As Fig. 8 suggests, the low-parameter models at the FP16 half-precision performed roughly at the level of 2-bit quantized models. The low-parameter models performed considerably worse than the 4-bit quantized models.
Author:
(1) Enkhbold Nyamsuren, School of Computer Science and IT University College Cork Cork, Ireland, T12 XF62 (enyamsuren@ucc.ie).
This paper is available on arxiv under CC BY-SA 4.0 license.
[story continues]
tags