
Two bridges, one rush hour, zero do-overs
“Cutover weekend” is a fairy tale when you’re migrating thousands of tapes (or billions of objects). Real migrations live in the messy middle: two stacks, two truths, and twice the places for ghosts to hide. The goal isn’t elegance—it’s survivability. You’re not building a bridge and blowing up the old one; you’re running both bridges during rush hour… while replacing deck boards.
TL;DR (for the exec sprinting between status meetings)
- You need 2.0–2.5 years of dual-stack overlap for serious archives.
- Plan for two telemetry stacks and two alert planes—on purpose.
- Budget 25–40% capacity headroom in the new system during the overlap (recalls + re-writes + retries + verification).
- Expect power/cooling to peak at 1.6–1.9× steady-state during the hottest quarter.
- Define a one-click rollback (it won’t be one click, but that’s the standard).
- The migration “finish line” is 90 days of boring: zero P1s, stable ingest, and verified parity across the sets.
Why dual-stack is not optional
In any non-toy environment, your users don’t pause while you migrate. You must:
- Serve existing read/write demand on the old stack,
- Hydrate and validate data into the new stack, and
- Prove parity (fixity + findability + performance envelopes) before you demote the old system.
That’s three states of matter in one datacenter. If you don’t consciously separate them, your queueing theory will do it for you—in the form of backlogs and angry auditors.
The Five Hard Beats (and how to win them)
1) Two telemetry stacks (and why you want both)
Principle: Never collapse new-stack signals into old-stack plumbing. You’ll lose fidelity and paper over regressions.
Old stack (Legacy):
- Metrics: drive mounts/recalls, tape queue depth, library robotics, filesystem ingest latency, tape error codes (LEOT, media errors, soft/hard retries), cache hit%.
- Logs: ACSLS/robot logs, HSM recalls, tape write completion, checksum compare events.
- Traces: usually none; add synthetic job tracing for long runs.
New stack (Target):
- Metrics: object PUT/GET P95/P99, multipart retry rate, ETag mismatch rate, cache write-back queue, erasure-coding (EC) window backlog, compaction status, S3 4xx/5xx, replication lag, lifecycle transition lag.
- Logs: API gateway, object router, background erasure/repair, audit immutability events.
- Traces: per-object ingest spans (stage → PUT → verify), consumer recall spans.
Bridging layer:
- A translation dashboard that lines up: Recall-to-Stage (legacy) ↔ Stage-to-Object (new) ↔ Post-write Verify (new).
- Emit canonical event IDs (e.g., file_uuid, bag_id, vsn_id, object_key) across both worlds so you can follow one item end-to-end.
Operational rule: If a signal can be misread by someone new at 3 AM, duplicate it with a human label. (“ec_window_backlog → ‘EC pending repair chunks’.”)
2) Two alert planes (and how they fail differently)
Alerts are not purely technical; they encode who gets woken up and what’s allowed to break.
Plane A — Legacy SLA plane (keeps the current house standing):
- P1: Robotics outage, recall queue stalled > 15 min, tape write failures > 5% rolling 10 min, HSM DB locked.
- P2: Mount latency > SLO by 2× for 30 min, staging filesystem > 85% full, checksum compare backlog > 12 hrs.
- P3: Non-critical drive failures, single-path network flaps (redundant), media warning rates up 3× weekly baseline.
Plane B — Migration plane (keeps the new house honest):
- P1: New object store accepts writes but verify fails > 0.1% / hr; replication lag > 24 hrs on any protected bucket; audit/immutability service down.
- P2: Lifecycle transitions > 72 hrs lag; EC repair backlog > 48 hrs; multipart retry rate > 5%.
- P3: Post-write fixity checks running > 20% behind schedule; cache eviction thrashing > threshold.
Golden rule: Never page the same person from both planes for the same symptom. Assign clear ownership and escalation. (Otherwise you’ll create the dreaded two pagers, zero action syndrome.)
3) Capacity headroom math (the part calculators “forget”)
Capacity during overlap has to absorb four things simultaneously:
- Working set your users still hit on the legacy stack (reads + occasional writes).
- Hydration buffer to ingest into the new stack.
- Verification buffer for post-write fixity and temporary duplication.
- Retry + rollback cushion for when a batch fails fixity or the new stack sneezes.
Let’s model new-stack headroom with conservative factors.
Variables
- D_total: total data to migrate (e.g., 32 PB).
- d_day: average verified migration/day (e.g., 120 TB/day sustained; if you don’t know, assume 60–150 TB/day).
- α_recall: fraction recalled from legacy that must be cached simultaneously (0.02–0.07 common; use 0.05).
- β_verify: overhead of verification copies (0.10–0.25; use 0.15 for rolling windows).
- γ_retry: failure/retry cushion (0.05–0.15; use 0.10).
- δ_growth: organic growth during migration (0.03–0.08 per year; use 0.05/yr).
- W: verification window in days (e.g., 14 days).
- S_day: legacy recall/stage capacity (e.g., 150 TB/day peak).
Headroom formula (new stack required free capacity during overlap):
Headroom_new ≈ (α_recall * D_total)
+ (β_verify * d_day * W)
+ (γ_retry * d_day * W)
+ (δ_growth * D_total * (Overlap_years))
Worked example
- D_total = 32 PB
- d_day = 120 TB/day
- α_recall = 0.05 ⇒ 1.6 PB
- β_verify = 0.15 & W = 14 ⇒ 0.15 * 120 * 14 = 252 TB ≈ 0.25 PB
- γ_retry = 0.10 & W = 14 ⇒ 0.10 * 120 * 14 = 168 TB ≈ 0.17 PB
- δ_growth = 0.05/yr, Overlap_years = 2.5 ⇒ 0.125 * 32 = 4 PB (this includes growth across total corpus; if growth only hits subsets, scale down accordingly)
Total headroom_new ≈ 1.6 + 0.25 + 0.17 + 4 = 6.02 PB
Reality check: If that number makes you queasy, good. Most teams under-provision growth and verification windows. You can attack it by shortening W (risk trade), throttling d_day (time trade), or using a larger on-prem cache with cloud spill (cost trade). Pick your poison intentionally.
4) Power/cooling overlap (how hot it gets before it gets better)
During dual-stack, you often run peak historical load + new system burn-in. Nameplate lies; measure actuals.
Basics
- 1 W ≈ 3.412 BTU/hr
- Cooling capacity (tons) where 1 ton ≈ 12,000 BTU/hr
Variables
- P_old: measured legacy avg power (kW), P_old_peak: peak (kW)
- P_new: measured new stack avg power during migration (kW), P_new_peak
- PUE: 1.3–1.8 (use 1.5 if unknown)
- f_overlap: simultaneous concurrency factor (0.7–1.0; assume 0.85 when you’re careful)
Peak facility power during overlap:
P_facility_peak ≈ (P_old_peak + P_new_peak * f_overlap) * PUE
**Cooling load (BTU/hr):**
BTU/hr ≈ P_facility_peak (kW) * 1000 * 3.412
Tons ≈ BTU/hr / 12000
Example
- P_old_peak = 120 kW
- P_new_peak = 90 kW (burn-in + EC repairs + cache)
- f_overlap = 0.85, PUE = 1.5
- P_facility_peak ≈ (120 + 90*0.85) * 1.5 = (120 + 76.5)*1.5 = 196.5 * 1.5 = 294.75 kW
- BTU/hr ≈ 294.75 * 1000 * 3.412 ≈ 1,005, ~**1.005e6 BTU/hr**
- Tons ≈ 1,005,000 / 12,000 ≈ **83.8 tons**
Implication: If your room is rated 80 tons with no redundancy, you’re courting thermal roulette. Either stage the new system ramp, or get a temporary chiller and hot-aisle containment tuned before the overlap peaks.
5) Rollback strategy (because you will need it)
You need a reversible plan when the new stack fails parity or the API lies.
Rollback checklist:
- Control plane: versioned config bundles (object lifecycles, replication rules, auth). Rolling back a rule must be idempotent.
- Data plane: content-addressed writes (hash-named) or manifests enable safe replay.
- Pointers: migration uses indirection (catalog DB, name mapping) so you can atomically flip readers/writers back to legacy.
- Clock: define the rollback horizon (e.g., 72 hrs) where old stack retains authoritative writes; after that, dual-write is mandatory until confidence returns.
- People: pre-assigned “red team” owns the rollback drills. Monthly rehearse: break → detect → decide → revert → verify. Export a timeline to leadership after each drill.
Litmus test: Can you prove that any object written in the last 72 hrs is readable and fixity-verified on exactly one authoritative stack? If you’re not sure which, you don’t have a rollback; you have a coin toss.
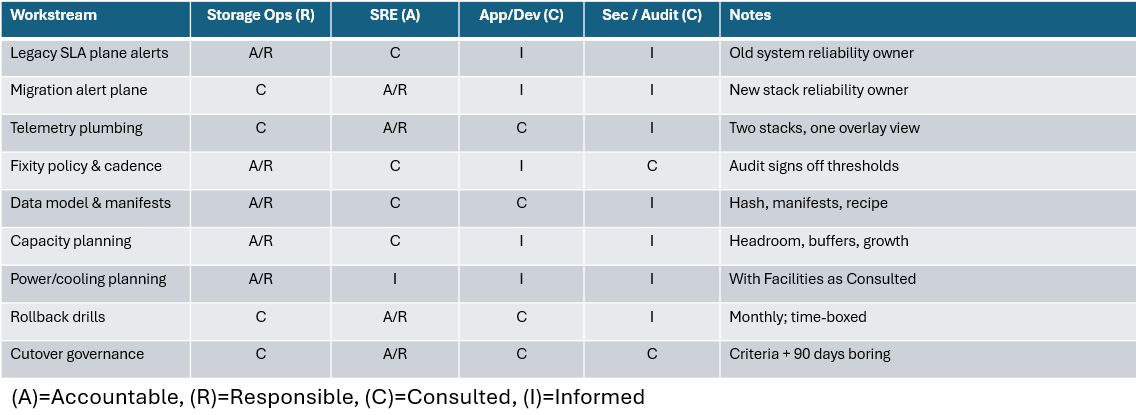
The RACI that keeps humans from stepping on the same rake
Timeline: the 2.5-year overlap

Legend: M = monthly rollback drill; “SLA parity soak” = run new stack at target SLOs with production traffic for 90 days minimum.
The Playbook (from “please work” to “boringly reliable”)
A) Telemetry: build the translator first
- Create a canonical vocabulary: recall_mount_latency, stage_queue_age, put_p95, etag_verify_rate, replication_lag, ec_backlog.
- Map old→new: a one-page legend every on-call uses. If an alert references a metric not in the legend, kill it.
- Emit correlation IDs (UUID) across recall, stage, PUT, verify; propagate to logs.
B) Alert planes: page the right human
- Separate routes: old plane → Storage Ops primary; new plane → SRE primary. Cross-page only at escalation step 2.
- Define P1/P2 in outcomes, not internals. (“Users cannot recall > 15 min” beats “robotics code 0x8002”.)
- Introduce budgeted noise: 1–2 synthetic P2s/month from each plane to prove the pager works and triage muscle stays warm.
C) Capacity headroom: compute, publish, revisit
- Publish the headroom formula (above) in your runbook, not in a slide.
- Recalc quarterly with real numbers (d_day, β_verify, γ_retry).
- If headroom drops < 20% free, either slow the ingest or expand cache. Don’t “hope” through it.
D) Power & cooling: schedule the ugly
- Stage new-stack burn-in during the coolest month.
- Pre-approve a portable chiller and extra PDUs; install before peak.
- Add thermal cameras or per-rack temp sensors; alert on rate of change, not just thresholds.
E) Rollback: rehearsed, timed, boring
- Runbooks with step timings (target: detect < 10 min, decide < 20 min, revert start < 30 min).
- Shadow writes or dual-write for the critical set until 90-day parity soak ends.
- Back-pressure valves: If verify backlog > threshold, auto-pause puts (not recalls) and page Migration plane.
F) Governance: declare the boring finish line
- Cutover criteria are binary:
- Only then schedule decommission in three passes: access freeze → data retirement → hardware retirement, each with abort points.
“But can we just… cut over?” (No.)
Let’s turn the snark dial: Cutover weekend is a cute phrase for small web apps, not for petabyte archives and tape robots named after Greek tragedies. Physics, queueing, and human sleep cycles don’t read your SOW. You’ll either:
- Build a dual-stack plan intentionally,
- Or live in one accidentally—without budgets, telemetry, or guardrails.
Pick intentional.
Worked mini-scenarios (because math > vibes)
Scenario 1: Verify window pressure
- You push d_day from 120 → 180 TB/day to “finish faster.”
- With β_verify=0.15, W=14: verify buffer jumps from 0.25 PB → 0.15 * 180 * 14 = 378 TB ≈ 0.38 PB.
- If headroom stayed flat, you just ate +130 TB of “invisible” capacity.
- If your cache eviction isn’t tuned, expect re-reads and PUT retries → γ_retry quietly creeps from 0.10 → 0.14, adding another 0.04 * 180 * 14 = 100.8 TB ≈ 0.10 PB.
- Net: your “faster” plan consumed ~0.24 PB extra headroom and slowed you down via retries.
Scenario 2: Power/cooling brown-zone
- Old peak 120 kW, new burn-in 110 kW, f_overlap=0.9, PUE=1.6.
- P_facility_peak = (120 + 99)*1.6 = 219*1.6 = 350.4 kW
- BTU/hr = 350.4*1000*3.412 ≈ 1.196e6 → ~99.7 tons
- If your CRAC is 100 tons nominal (80 usable on a hot day), congrats—you’re out of spec.
- Fix: stagger burn-in, enable row-level containment, or rent 20–30 tons portable for 60–90 days.
Scenario 3: Rollback horizon truth test
- New stack verify fails spike to 0.4%/hr for 3 hrs after a firmware push.
- You detect in 9 min (anomaly), decide in 16 min, start revert in 27 min.
- Dual-write on critical collections ensures authoritative copy exists in legacy for last 24 hrs.
- Users see degraded ingest but consistent reads. You publish a post-mortem with who paged whom, when, and why.
- Leadership’s reaction: mild annoyance → continued funding. (The alternative: blame tornado.)
Common failure smells (and the antidotes)
- Shared dashboards, shared confusion. Antidote: Two stacks, one overlay view with legend; don’t merge sources prematurely.
- Pager ping-pong. Antidote: Distinct planes, distinct owners, escalation handshake documented.
- Capacity “optimized” to zero margin. Antidote: Publish headroom math; refuse go-faster asks without buffer adjustments.
- Thermals guessed, not measured. Antidote: Metered PDUs, thermal sensors, and an explicit peak week plan.
- Rollback “documented,” never drilled. Antidote: Monthly red-team drills with stopwatch; treat like disaster recovery, because it is.
Manager’s checklist (print this)
- Two telemetry stacks live, with a translator dashboard and legend
- Two alert planes live, no shared first responder
- Headroom ≥ 25% free on new stack; recalculated this quarter
- Portable cooling + PDUs pre-approved (not “on order”)
- Rollback drill within 30 days; last drill report published
- Cutover criteria written as binary test; 90-day boring clock defined
- Finance briefed on growth and verification buffers (no surprise invoices)
- Legal/Audit sign-off on fixity cadence and immutability controls
Closing
If your plan is a slide titled “Cutover Weekend,” save time and rename it to “We’ll Be Here All Fiscal Year.” It’s not pessimism; it’s project physics. Dual-stack years are how grown-ups ship migrations without turning their archives into crime scenes.
[story continues]
tags