
Table of Links
3 SUTRA Approach
4 Training Multilingual Tokenizers
5 Multilingual MMLU
5.1 Massive Multitask Language Understanding
5.2 Extending MMLU to Multiple Languages and 5.3 Consistent Performance across Languages
5.4 Comparing with leading models for Multilingual Performance
6 Quantitative Evaluation for Real-Time Queries
7 Discussion and Conclusion, and References
4 Training Multilingual Tokenizers
Tokenization, a critical step in NLP pipeline, involves converting text into a sequence of tokens, where each token represents a subword or word. Although English specific tokenizers can generate text in non-English languages, they don’t capture language specific nuances and are highly inefficient in other languages, especially non-Romanized languages. More specifically for Indian languages like Hindi, Gujarati, or Tamil, we note that tokenizers from leading LLMs like Llama-2, Mistral, and GPT-4 consume 4.5X to 8X more tokens compared to English, as shown in Table 4.
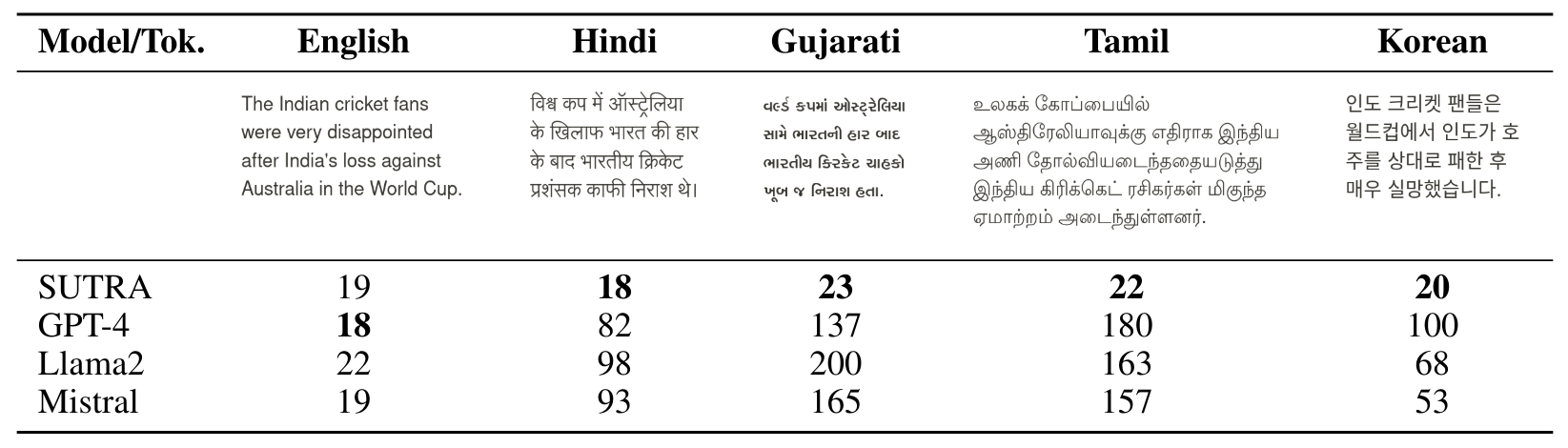
A key step in adding language specific skills is decreasing the average number of tokens a word is split into (also known as token fertility) by a language model on non-english text. This makes inferencing efficient as well as semantically meaningful. We train the sentence-piece tokenizer from a large corpus of multi-language dataset of 500K+ documents, which is then merged with a pre-trained english tokenizer to increase the vocabulary size. Text generated with our tokenizers lead to 80% to 200% reduction in overall tokens consumed across languages, which is critical for bringing down the cost of inferencing when deploying these models for cost-sensitive use-cases.
Authors:
(1) Abhijit Bendale, Two Platforms (abhijit@two.ai);
(2) Michael Sapienza, Two Platforms (michael@two.ai);
(3) Steven Ripplinger, Two Platforms (steven@two.ai);
(4) Simon Gibbs, Two Platforms (simon@two.ai);
(5) Jaewon Lee, Two Platforms (jaewon@two.ai);
(6) Pranav Mistry, Two Platforms (pranav@two.ai).
This paper is
[story continues]
tags