In software engineering, a data pipeline is exactly what it suggests: a way for data to ‘flow’ from a source to a destination. Every data pipeline consists of 3 stages.
Extract phase: In this phase, data is extracted from the source. This could be hitting some API, reading files from a object storage (like AWS S3) or running queries on a database (like AWS RDS).
Transform phase: In this phase, transformations are applied to the data to massage it into a different format. This could be transformations at rest (like normalizing all documents in a data lake) or transformations in motion (like converting from one class to another).
Load phase: In this phase, the data is loaded into another storage. This could be a data warehouse, database or even a customer facing tool like a Tableau dashboard.
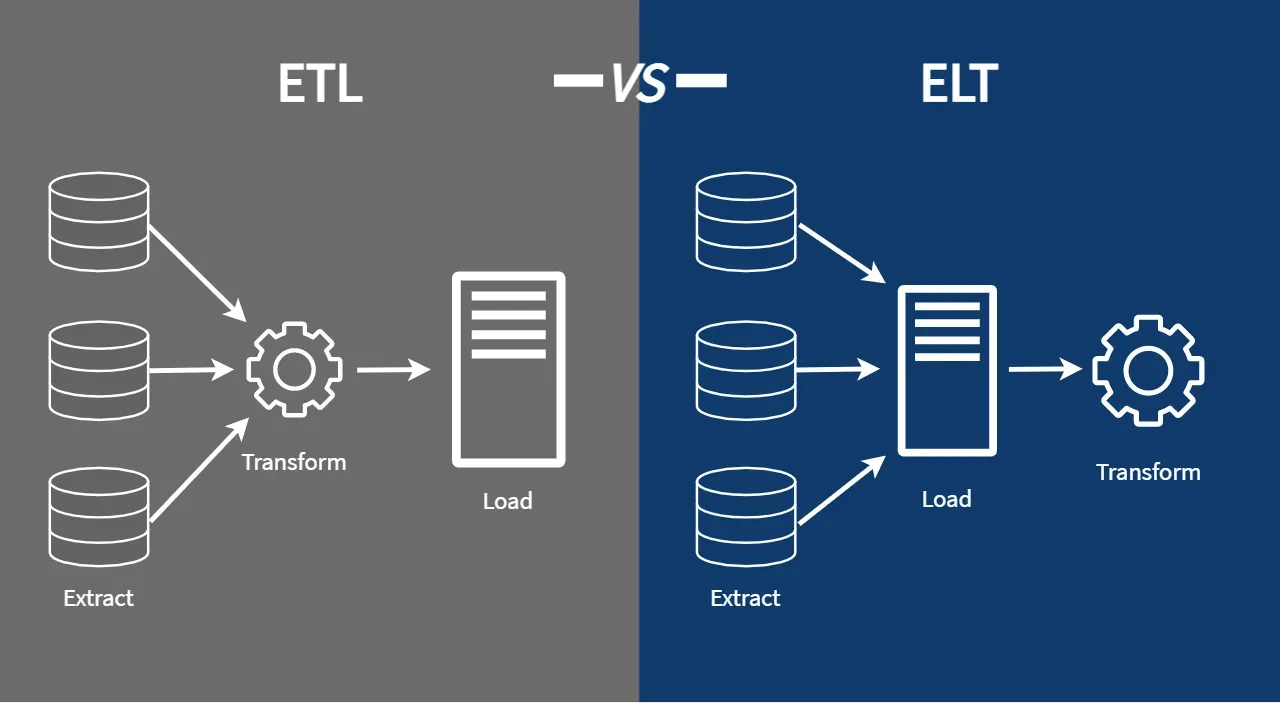
Every data pipeline begins with the Extract phase. But the order in which the other 2 phases occur divides data pipelines into 2 broad categories, which are explained below.
ETL Pipelines
In ETL pipelines, the order of operations is Extract, Transform and Load.
In ETL pipelines, data is extracted into from a single (or multiple) source(s), transformed on the fly using a set of business rules and loaded into a target repository. ETL pipelines usually move data into a relational store like a SQL database and this makes subsequent querying very fast.
ELT Pipelines
In ELT pipelines, the order of operations is Extract, Load and Transform.
In ELT pipeline, data is extracted into from a single (or multiple) source(s). This raw data is stored in a data lake. Transformations are applied when required before the data is consumed or server. ELT is a relatively modern phenomenon, made possible by better technology in recent times.
Advantages of ELT over ETL
ELT, though new to the field, has some advantages over ETL that make it really useful in some scenarios.
-
No need to formalize schema
This is a big advantage. ETL applications require all the transformations to be formalized and coded before the data can be ingested into the organization’s data stores. ELT has no such requirements. This means new data can be made available as soon as we know how to extract it.
-
Ingestion of unstructured data
ETL by definition can not deal with unstructured data. For transformations to take place consistently for every data point, we expect the data to have a certain predictable structure. This is not the case with ELT however. ELT pipelines are capable of handling both structured and unstructured data because they make no assumptions of any underlying structure.
-
Retention of Data from external sources
Many times, we may not know immediately how we want to consume data. We just know that we ‘may’ consume it later, and hence will definitely want to store it in a system controlled by us, like a data lake. ELT pipelines help us ingest raw data quickly into our data lake without wasting time thinking about how to transform them into a usable format. This is very useful for AI-based applications, especially.
Conclusion
ETL and ELT pipelines have their own advantages and disadvantages. While ETL pipelines are often the first preference, ELT pipelines could very well be more advantageous to your particular use case. The final decision, of course, depends on details and specifications required from the data pipeline.
[story continues]
tags