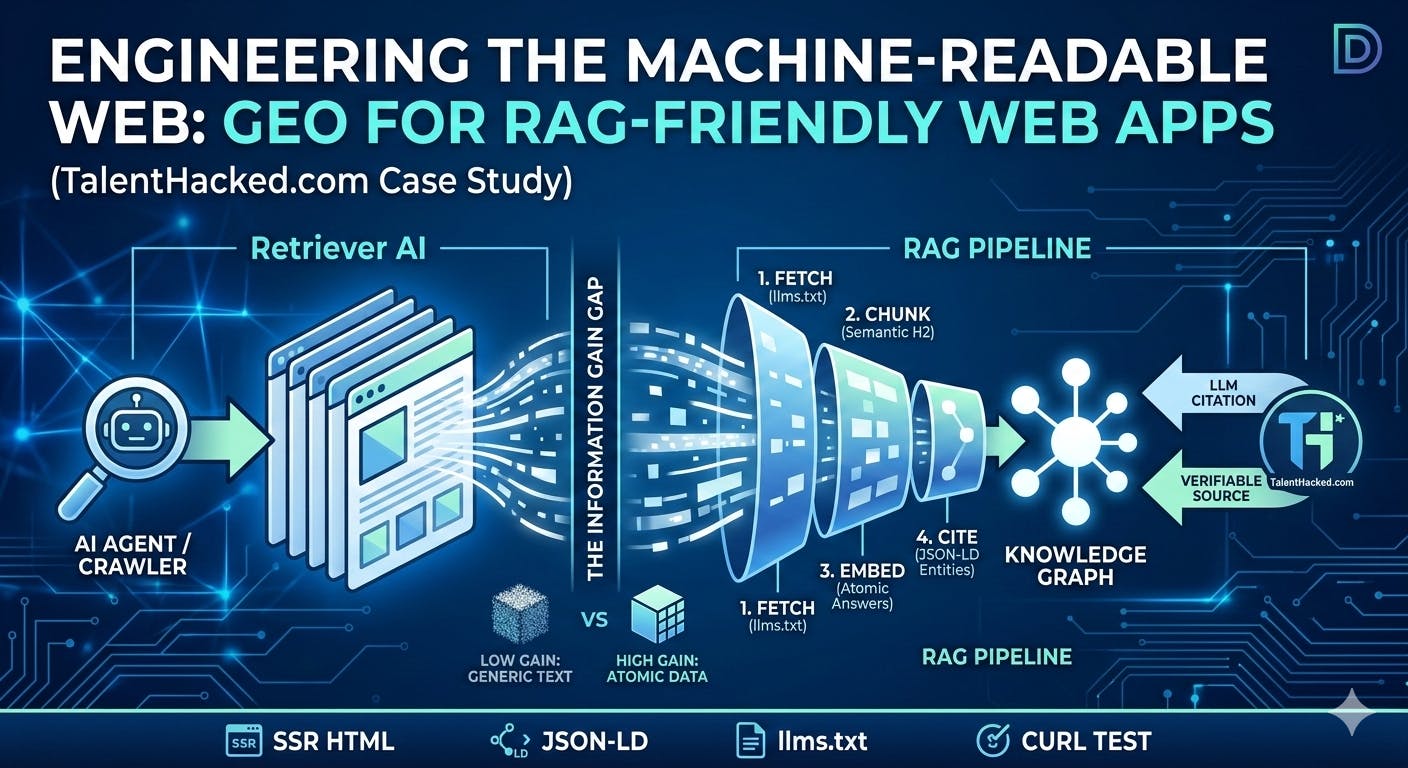
LLMs are becoming a discovery layer. Users ask a question, the model synthesizes an answer, and then it may cite a few sources. That shifts the goal from “rank and win a click” to “be the most useful, extractable, verifiable source in the retrieval set.”
For TalentHacked.com (UK Global Talent Visa platform), this is a solvable engineering problem: ship content that a headless retriever can fetch, chunk, embed, and cite.
The key concept: Information Gain
Information Gain is the practical reason an LLM would cite your page instead of any other page on the topic. It is the gap between:
- what the model can answer from generic web consensus, and
- what your site uniquely adds that is specific, auditable, and easy to retrieve
A simple rule: if your page reads like every other overview, it has low information gain. If it contains atomic answers, clear definitions, and step-by-step checks that can be validated, it has high information gain.
Examples for TalentHacked:
- Low gain chunk: “The Global Talent visa is for talented people in eligible fields.”
- Higher gain chunk: “For a software founder, your evidence packet should map each claim to a dated artifact. Use a one-claim-per-document pattern, include issuer + URL + date, and add a short ‘why this proves the criterion’ note. Missing provenance is a common failure mode.”
Now let’s implement four steps that increase information gain and retrieval success.
Step 1) Publish llms.txt in the root
Purpose: give AI crawlers and retrieval agents a canonical map of the pages that are designed to be cited. Keep it small, opinionated, and stable.
Create https://talenthacked.com/llms.txt:
# llms.txt for TalentHacked.com
site: https://talenthacked.com
name: TalentHacked
description: Evidence-driven guidance and tools for the UK Global Talent Visa.
language: en-GB
last_updated: 2026-03-05
citable:
- /uk-global-talent-visa
- /evidence/letters-of-recommendation
- /evidence/checklist
- /glossary
- /sources
disallow:
- /search
- /tag/
- /author/
- /*?*
Implementation notes:
- Serve it as plain text with HTTP
200. - Do not require authentication.
- Keep canonical URLs stable and avoid duplicates.
Why this helps: retrieval systems often need a “starting set.” llms.txt reduces crawl ambiguity and points the model to your highest-signal pages first.
Step 2) Add semantic entity mapping with JSON-LD (TechArticle + DefinedTerm)
Purpose: make your content machine-resolvable. GEO is not just about keywords; it is about entities and definitions that can be referenced consistently.
Put JSON-LD in the <head> of a canonical guide page. This compact graph does three things:
- declares the page as a
TechArticle - defines key terms as
DefinedTerm - anchors your claims to an official primary source via
sameAsandisBasedOn
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@graph": [
{
"@type": "Organization",
"@id": "https://talenthacked.com/#org",
"name": "TalentHacked",
"url": "https://talenthacked.com",
"sameAs": [
"https://www.gov.uk/global-talent"
]
},
{
"@type": "TechArticle",
"@id": "https://talenthacked.com/uk-global-talent-visa#article",
"headline": "UK Global Talent Visa: Evidence Guide (RAG-Friendly)",
"publisher": { "@id": "https://talenthacked.com/#org" },
"mainEntityOfPage": "https://talenthacked.com/uk-global-talent-visa",
"about": [
{ "@id": "https://talenthacked.com/glossary#global-talent-visa" },
{ "@id": "https://talenthacked.com/glossary#endorsement" }
],
"isBasedOn": [
{
"@type": "WebPage",
"name": "UK Global Talent visa guidance (primary source)",
"url": "https://www.gov.uk/global-talent"
},
{
"@type": "WebPage",
"name": "Home Office",
"url": "https://www.gov.uk/government/organisations/home-office"
}
]
},
{
"@type": "DefinedTerm",
"@id": "https://talenthacked.com/glossary#global-talent-visa",
"name": "Global Talent visa",
"description": "A UK visa route for leaders or potential leaders in eligible fields; typically requires endorsement or qualifying award.",
"inDefinedTermSet": "https://talenthacked.com/glossary",
"sameAs": "https://www.gov.uk/global-talent"
},
{
"@type": "DefinedTerm",
"@id": "https://talenthacked.com/glossary#endorsement",
"name": "Endorsement",
"description": "A decision by an endorsing body supporting eligibility for the Global Talent route.",
"inDefinedTermSet": "https://talenthacked.com/glossary"
}
]
}
</script>
Why this helps: when definitions are stable and linked, retrievers can target “definition chunks,” and the model can cite your site for terminology instead of a random blog.
Step 3) Write for vector retrieval: the “Atomic Answer” chunk pattern
Most RAG systems chunk by headings and paragraph boundaries. Your job is to make the first chunk after a heading:
- complete enough to quote
- short enough to embed cleanly
- precise enough to reduce uncertainty
Pattern:
- an
<h2>that is a question or claim - one paragraph of roughly 60 words that answers it directly
- then details, examples, and sources
Example:
<h2>What counts as “evidence” for a Global Talent application?</h2>
<p><strong>Atomic answer:</strong> Evidence is a set of verifiable documents that support specific criteria claims such as impact, recognition, and leadership. Each item should be attributable, dated, and easy to audit. Strong evidence maps one claim to one artifact and includes a one-sentence explanation of what it proves and why it is credible.</p>
<p>Details: add issuer, URL, screenshots, a criterion mapping table, and common failure modes...</p>
Operational tips:
- Use real semantic headings (
<h2>, not styled<div>). - Keep the first paragraph stable; treat it like an API contract for retrieval.
- Put definitions in
/glossaryand link to them consistently across the site.
Step 4) Verify SSR and crawlability with the headless test
If your site renders content only after client-side JS, many crawlers will see a thin shell. Test what an AI-style fetcher gets.
Fetch HTML as an AI bot:
curl -A "GPTBot" -L https://talenthacked.com/uk-global-talent-visa | head -n 80
You should see:
- your
<h1>and multiple<h2>sections - the Atomic Answer paragraphs in raw HTML
- the JSON-LD script tag
Quick checks:
curl -A "GPTBot" -L https://talenthacked.com/uk-global-talent-visa | grep -n "<h2"
curl -A "GPTBot" -L https://talenthacked.com/uk-global-talent-visa | grep -n "application/ld+json"
Common failure modes:
- HTML response is just a JS bundle loader
- headings only appear after hydration
- bot protections block unknown user agents
- canonical content differs by user agent
The fix is always the same: ensure SSR delivers meaningful HTML.
Technical Checklist
-
llms.txtexists at/llms.txtand lists a small set of canonical citable pages -
Canonical pages ship SSR HTML that includes headings and body content without JS
-
Every key
<h2>is followed by a ~60-word Atomic Answer -
JSON-LD includes
TechArticleplusDefinedTermentries for your glossary terms -
curlheadless tests confirm content and JSON-LD are present for AI user agents -
High-information pages include primary-source links and a visible “last updated” date
The Machine-Readable Web wins citations
The future web is not only human-readable. It is machine-retrievable. If you want LLMs to cite you, engineer your site for Information Gain: publish unique, auditable answers, define your entities, and make content work without JavaScript.