Authors:
(1) Bo Wang, Beijing Jiaotong University, Beijing, China (wangbo_cs@bjtu.edu.cn);
(2) Mingda Chen, Beijing Jiaotong University, Beijing, China (23120337@bjtu.edu.cn);
(3) Youfang Lin, Beijing Jiaotong University, Beijing, China (yflin@bjtu.edu.cn);
(4) Mike Papadakis, University of Luxembourg, Luxembourg (michail.papadakis@uni.lu);
(5) Jie M. Zhang, King’s College London, London, UK (jie.zhang@kcl.ac.uk).
Table of Links
3 Study Design
3.1 Overview and Research Questions
3.3 Mutation Generation via LLMs
4 Evaluation Results
4.1 RQ1: Performance on Cost and Usability
4.3 RQ3: Impacts of Different Prompts
4.4 RQ4: Impacts of Different LLMs
4.5 RQ5: Root Causes and Error Types of Non-Compilable Mutations
5 Discussion
5.1 Sensitivity to Chosen Experiment Settings
4.4 RQ4: Impacts of Different LLMs
To answer this RQ, we add two extra LLMs, GPT-4 and StarChat16b, and compare their results with the two default LLMs, GPT-3.5 and Code Llama-13b. The right half of Table 7 shows comparative results across models using the default prompt. We observe that closed-source LLMs generally outperform others in most metrics. GPT-3.5 excels in Mutation Count, Generation Cost per 1K Mutations, and Average Generation Time, ideal for rapidly generating numerous mutations. GPT-4 leads in all Usability Metrics, and Behavior Similarity Metrics, demonstrating its effectiveness in code-related tasks, although its enhancements over GPT-3.5 in Behavior Metrics are trivial. Between the two open-source LLMs, despite StarChat-𝛽-16b having more parameters, CodeLlama-13b outperforms in all metrics. This suggests that model architecture and training data quality significantly impact performance beyond just the number of parameters.
4.5 RQ5: Root Causes and Error Types of Non-Compilable Mutations
Non-compilable mutations require a compilation step to filter out, which results in wasted computational resources. As mentioned in Section 4.1, LLMs generate a significant number of non-compilable mutations. This RQ analyzes the types of errors and potential root causes of these non-compilable mutations. Following the setting of the previous steps, we first sample 384 non-compilation mutations from the outputs of GPT-3.5, ensuring the confidence level is 95% and the margin of error is 5%. From the manual analysis of these non-compilable mutations, we identified 9 distinct error types, as shown in Table 8.
Shown as Table 8, the most common error type, Usage of Unknown Methods, accounts for 27.34% of the total errors, revealing the hallucination issue of generative models [30]. Code Structural Destruction is the second most common error, accounting for 22.92%, indicating that ensuring generated codes are syntactically correct remains a challenge for current LLMs. This result suggests that there is still significant room for improvement in current LLMs.
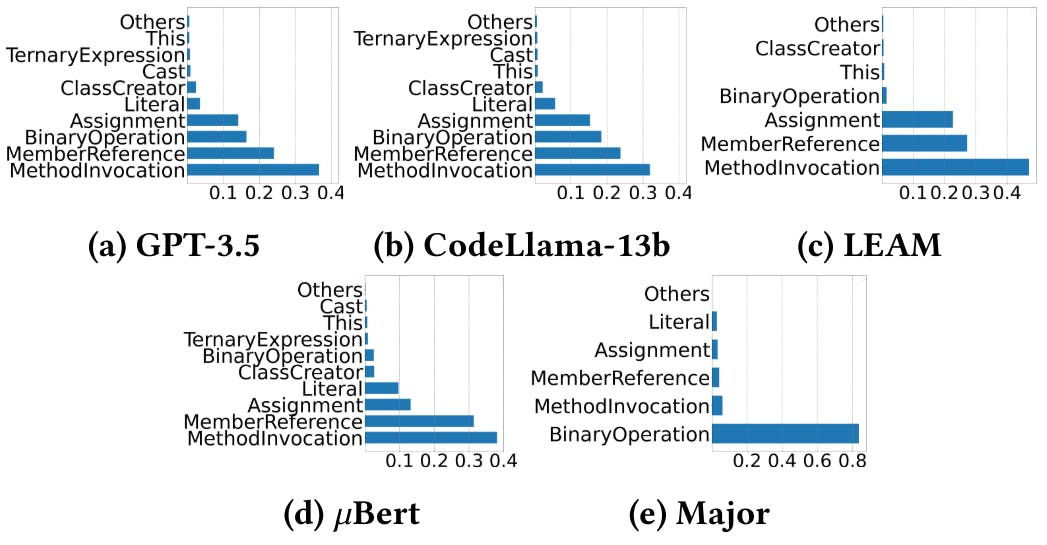
To analyze which types of code are prone to causing LLMs to generate non-compilable mutations, we examined the code locations of all non-compilable mutations generated by GPT-3.5, CodeLlama, LEAM, and 𝜇Bert in Section 4.1, as shown in Figure 3. For all approaches, the code locations with MethodInvocation and MemberReference are the top-2 prevent AST Node types. In particular, there are more than 30% of non-compilable mutations occur at the location with MethodInvocation, and 20% occur at the location with MemberReference. This is potentially caused by the inherent complexity of these operations, which often involve multiple dependencies and references. If any required method or member is missing or incorrectly specified, it can easily lead to non-compilable mutations. The errors highlight a need for better context-aware mutation generation, ensuring that method calls and member references align with the intended program structure. Additionally, we inspect the deletion mutations rejected by the compiler and find that for GPT-3.5, CodeLlama, LEAM, 𝜇Bert, and Major, these mutations account for 7.1%, 0.2%, 45.3%, 0.14%, and 14.4% of all their non-compilable mutations, respectively. Thus for LLMs, deletion is not the major reason for non-compilation.
This paper is