Table of Links
-
Related Works
2.3 Evaluation benchmarks for code LLMs and 2.4 Evaluation metrics
-
Methodology
-
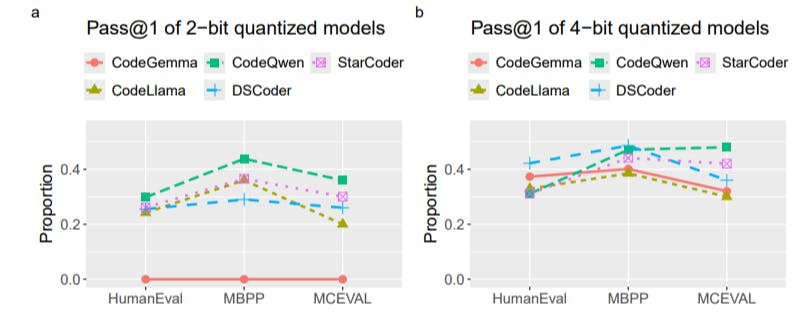
Evaluation
2.3 Evaluation benchmarks for code LLMs
HumanEval [28] and MBPP [29] are arguably the earliest benchmarks that were created for evaluating code LLMs. These are originally benchmarks for testing code generation capabilities specifically in Python language. HumanEval contains 164 hand-written programming tasks. In each task, a model is asked to generate a function that should pass several unit tests. On average, there are 7.7 unit tests per task. In the original study [28], HumanEval was used to evaluate GPT-3-based Codex models (OpenAI’s model that powers Github Copilot) with 12 million to 12 billion parameters. Other applications of HumanEval include evaluating GitHub Copilot, Amazon CodeWhisperer, and ChatGPT [30].
The Mostly Basic Programming Problems (MBPP) benchmark consists of 974 code-generation tasks at the beginner level. Similar to HumanEval, each task in MBPP has a prompt asking to write a Python function. The generated function is also tested against the unit tests defined in the task. MBPP was originally tested on dense left-to-right decoder-only transformer language models with 244 million to 137 billion parameters [29]. Since then, it has become one of the main benchmarks for evaluating all major LLMs such as CodeLlama 7B-34B and StarCoder 15.5B [31]. Overall, HumanEval and MBPP are widely used benchmarks, and Jiang, Wang, Shen, et al. [32] provide a comprehensive review of both benchmarks and code LLMs.
MultiPL-E [33] is a benchmark that combines HumanEval and MBPP. It is a multilingual benchmark that translated the original Python tasks into 18 other programming languages. These languages include Lua, Bash, C++, C#, D, Go, Java, JavaScript, Julia, Perl, PHP, R, Racket, Ruby, Rust, Scalia, Swift, and TypeScript. The benchmark was used to evaluate the InCoder 6.7B, CodeGen 16.1B, and Codex 12B models. A later study [14] applies MultiPL-E to evaluate fine-tuned versions of the StarCoderBase 1B, StarCoderBase 15B, and CodeLlama 34B models. Currently, MultiPL-E is arguably the most popular benchmark for testing multilingual code LLMs. Along with HumanEval, it is used to maintain the Multilingual Code Models Evaluation leaderboard.
Finally, MCEVAL [22] is another multilingual benchmark that covers 40 languages including Lua. Unlike MultiPL-E, which translated Python-based HumanEval and MBPP to other programming languages, MCEVAL contains humanannotated tasks. MCEVAL contains three categories of programming tasks: code generation, code completion, and code understanding. The code generation tasks follow the same evaluation procedure as in MultiPL-E relying on function generation prompts accompanied with unit tests. All generation tasks are divided into easy, middle, and hard difficulty levels. The original study [22] evaluated 23 models with 7B to 72B parameters. These models include GPT-3.5-Turbo, GPT4-Turbo, GPT4-o, Qwen1.5-Chat, Llama3, Phi-3-medium, Yi, CodeQwen 1.5 Chat, DeepSeek Coder Instruct, DeepSeek Coder 1.5 Instruct, CodeLlama Instruct, OCTOCODER, CodeShell, MagiCoder, WizardCoder, Codegemma, Codestral v0.1, Nxcode, OpenCodeInterpreter, etc.
Several studies used custom-developed benchmarks for specific domains. For example, Poldrack, Lu, and Begus [34] created a Python-based dataset with 32 data science coding problems. With this dataset, the authors tested ChatGPT and its underlying GPT-4 model. Liu, Le-Cong, Widyasari, et al. [35] compiled a dataset of 2033 programming tasks collected from LeetCode[4], an online platform for learning programming. There are versions of Python and Java for each task. The dataset was also used to evaluate ChatGPT.
As can be seen, past works focused on evaluating full- or half-precision models without quantization applied to them. Many of the models (models with 7B or more parameters) mentioned in this section are too computationally intensive to be feasibly deployed on generic consumer devices. Models of smaller sizes, such as StarCoderBase 1B, demonstrate only marginal performance compared to the other models. Therefore, it still remains a question whether quantized code LLMs with a larger number of parameters can be leveraged.
2.4 Evaluation metrics
The performance of a model in these benchmarks is usually evaluated with the pass@k metric [36; 28]. Because the next token prediction in LLMs is a stochastic process, an LLM can generate different outputs for the same prompt. For a code LLM, if at least one correct solution (a solution that passed all unit tests defined in the task) is found in the top k outputs then the LLM is considered to have passed the task. For example, with pass@10, a code LLM must produce a correct solution within its top 10 outputs. pass@1 is the strictest test where the code LLM is expected to produce a correct solution with its first attempt.
2.5 Low- and high-resource languages
Cassano, Gouwar, Nguyen, et al. [33] proposed a categorization of programming languages based on their frequency on GitHub and TIOBE rank. For example, C++, Java, JavaScript, and TypeScript are considered to be high-frequency languages. The other categories are medium, low, and niche. Lua, Racket, Julia, D, and Bash fall into the niche category, each having less than 1% representation on GitHub.
The low representation of these languages can result in a lack of training data for LLMs. For this reason, Cassano, Couwar, Lucchetti, et al. [14] categorized programming languages into high- and low-resource languages. The former include languages such as Java, Python, and JavaScript. The latter include Julia, R, Racket, and Lua.
This reflects the bias in existing code LLMs toward high-resource languages. Even if quantized models perform well on high-resource languages, this performance may not generalize to low-level languages. In fact, because of the very nature of optimization, quantization may negatively affect most code generation for low-resource languages. Therefore, it is more informative to evaluate quantized models against low-resource languages rather than high-resource languages. Among the niche low-resource languages, the non-quantized models demonstrated the best performance on Lua [33; 14; 22]. Therefore, Lua presents a good balance between being a low-resource language and being a benchmark.
Author:
(1) Enkhbold Nyamsuren, School of Computer Science and IT University College Cork Cork, Ireland, T12 XF62 (enyamsuren@ucc.ie).
This paper is available on arxiv under CC BY-SA 4.0 license.
[4] https://leetcode.com/