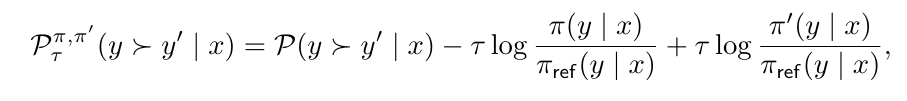Extending Direct Nash Optimization for Regularized Preferences
Written by @languagemodels| Published on 2025/4/17
TL;DR —
This section presents an extension of the Direct Nash Optimization (DNO) framework for handling regularized preferences. The key difference between SPO and Nash-MD lies in the use of smoothed policies for the latter, which helps obtain a late-iteration guarantee. The section introduces a new version of DNO, designed to converge to a Nash equilibrium using KL-regularization. The algorithm (Algorithm 3) works iteratively, adjusting the policy distribution through a partition function and reward function, ultimately refining the policy with each iteration. The approach helps address the challenges of regularized preferences while ensuring stable convergence.
Authors:
(1) Corby Rosset, Microsoft Research and Correspondence to corbyrosset@microsoft.com;
(2) Ching-An Cheng, Microsoft Research;
(3) Arindam Mitra, Microsoft Research;
(4) Michael Santacroce, Microsoft Research;
(5) Ahmed Awadallah, Microsoft Research and Correspondence to hassanam@microsoft.com;
(6) Tengyang Xie, Microsoft Research and Correspondence to tengyangxie@microsoft.com.