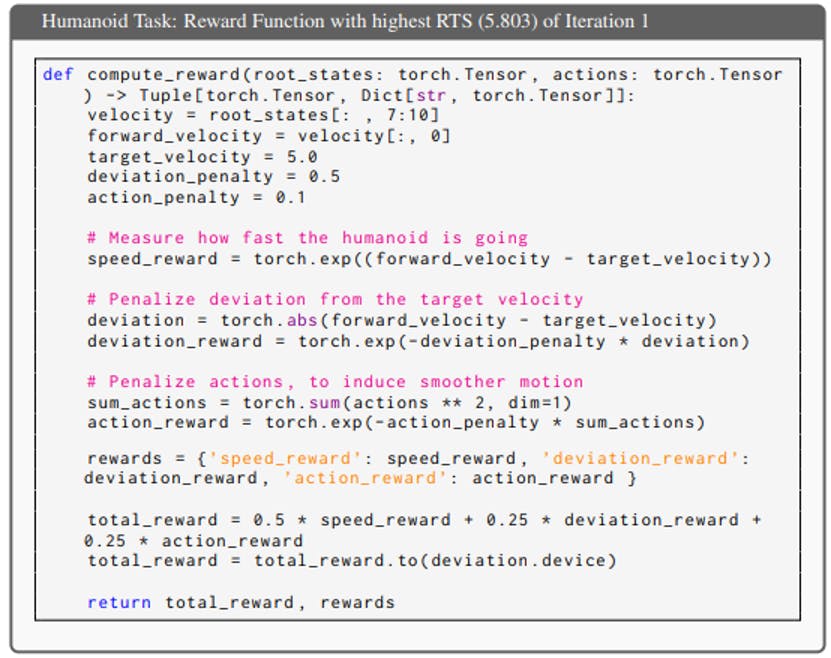
TL;DR —
This section presents environment details for 9 tasks in IsaacGym, including observation and action dimensions, task descriptions, and evaluation metrics. Learn how these elements contribute to preference-based reinforcement learning experiments.
Table of Links
- Abstract and Introduction
- Related Work
- Problem Definition
- Method
- Experiments
- Conclusion and References
A. Appendix
A.1. Full Prompts and A.2 ICPL Details
A.6 Human-in-the-Loop Preference
A.4 ENVIRONMENT DETAILS
In Table 4, we present the observation and action dimensions, along with the task description and task metrics for 9 tasks in IsaacGym.

Authors:
(1) Chao Yu, Tsinghua University;
(2) Hong Lu, Tsinghua University;
(3) Jiaxuan Gao, Tsinghua University;
(4) Qixin Tan, Tsinghua University;
(5) Xinting Yang, Tsinghua University;
(6) Yu Wang, with equal advising from Tsinghua University;
(7) Yi Wu, with equal advising from Tsinghua University and the Shanghai Qi Zhi Institute;
(8) Eugene Vinitsky, with equal advising from New York University (zoeyuchao@gmail.com).
This paper is available on arxiv under CC 4.0 license.
[story continues]
Written by
@languagemodels
Large Language Models (LLMs) ushered in a technological revolution. We breakdown how the most important models work.
Topics and
tags
tags
reinforcement-learning|in-context-learning|preference-learning|large-language-models|reward-functions|rlhf-efficiency|in-context-preference-learning|human-in-the-loop-rl
This story on HackerNoon has a decentralized backup on Sia.
Transaction ID: KqIwyf6s63YYzoVo_6iyno9OfZFxkB4e8sHhxTovx88