
Every morning, millions of people open their phones to the same thing: a flood of headlines. Global politics, tech announcements, market swings, and local stories all compete for attention. Most of it isn’t relevant — but buried somewhere are the few stories that truly matter.
You don’t need flashy “agentic AI” hype to solve this. What you need are well-designed tools with strong fundamentals: systems that can fetch information, process it, enrich it with structure, and deliver it in a way that fits your context. Large language models add value here — not by being the whole solution, but by refining, summarizing, and helping you iterate.
AI Agents
At its core, an agent is just a tool that connects a few dots. Think of simple functions that can make RPC/API calls, fetch data from a source, process it, and either pass it along to an LLM or hand it to other agents for more processing.
In the context of large language models, an agent usually:
- Perceives through inputs like search results, APIs, or user instructions.
- Reasons with the help of an LLM, deciding what to prioritize.
- Acts by calling tools, running code, or presenting results.
Let’s walk through this “agentic world” — the new hype in town — in the context of a personalized news feed. If you’ve ever prepped for a system design interview, you’ll know feed design always shows up: the Facebook News Feed, Twitter timeline, or (if you’re a 90s kid) RSS readers. This is the same challenge, reimagined for LLMs.
The Simple Personalized News Agent
Imagine you tell the agent you care about certain tags: AI, Apple, and Bay Area stories. It does three things:
- Pulls the top news from the web.
- Filters the results by those keywords.
- Summarizes them into a quick digest.
On a given day, it might give you:
- Apple unveils new on-device AI model for Siri and iOS apps.
- Bay Area rail expansion project secures funding.
- Markets cool as AI chip demand slows after last quarter’s surge.
This is already helpful. The firehose is reduced to a manageable list. But it’s flat. You don’t know why a story matters, or how it connects to others.
Introducing Multiple Agents
Instead of relying on one monolithic agent that does everything end-to-end, we can split the workflow across specialist agents, each focused on a single responsibility. This is the same principle as a newsroom: reporters gather raw material, researchers annotate it, analysts provide context, and editors package it for readers.
In our news pipeline, that looks like this:
- Fetcher Agent — retrieves full news articles from feeds or APIs.
- Passage Extractor Agent — highlights the most relevant sections of each article.
- Named Entity Extractor Agent — pulls out people, companies, places, and products mentioned.
- Entity Disambiguation Agent — ensures “Apple” is Apple Inc., not the fruit.
- Entity Tagger Agent — assigns structured tags (e.g., Organization: Apple, Product: iPhone).
- Topic Classifier Agent — identifies broader themes such as AI, Finance, Bay Area.
- Sentiment & Stance Agent — determines whether coverage is positive, negative, or neutral.
- Tag Summarizer Agent — merges entities, topics, and sentiments into thematic sections.
- Fact-Checker Agent — validates claims against trusted sources.
- Personalization & Ranking Agent — prioritizes stories that match your interests and history.
- Digest Compiler Agent — assembles the polished digest in a reader-friendly format.
- Daily Digest Agent — delivers the final package (to your inbox, Slack, or app).
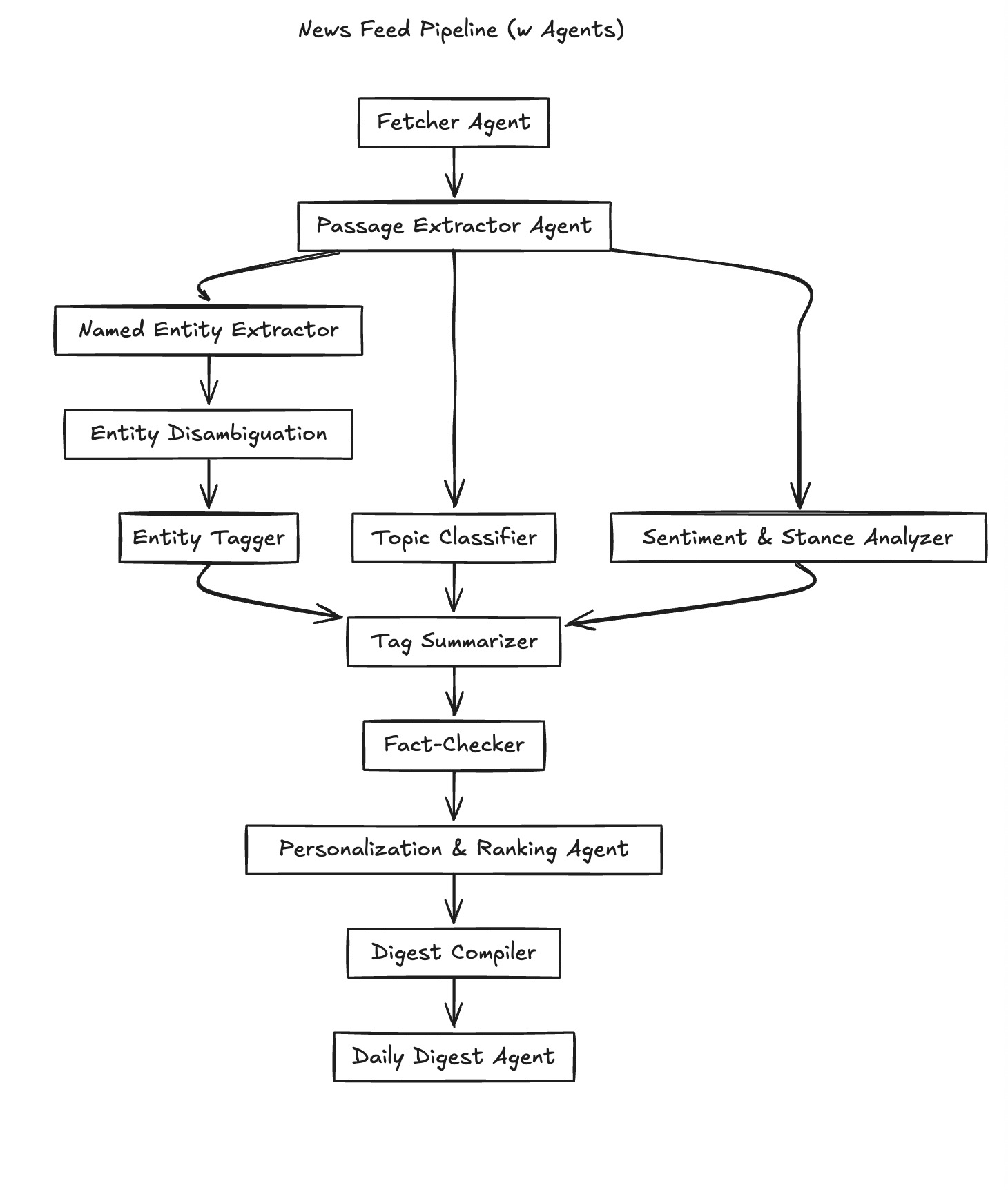 Some of these agents operate sequentially (e.g., disambiguation must follow extraction), while others can run in parallel (topic classification, sentiment analysis, and entity extraction can all work on the same passage at once). The result is a coordinated pipeline of specialists, producing a far richer and more structured digest than any single agent could.
Some of these agents operate sequentially (e.g., disambiguation must follow extraction), while others can run in parallel (topic classification, sentiment analysis, and entity extraction can all work on the same passage at once). The result is a coordinated pipeline of specialists, producing a far richer and more structured digest than any single agent could.
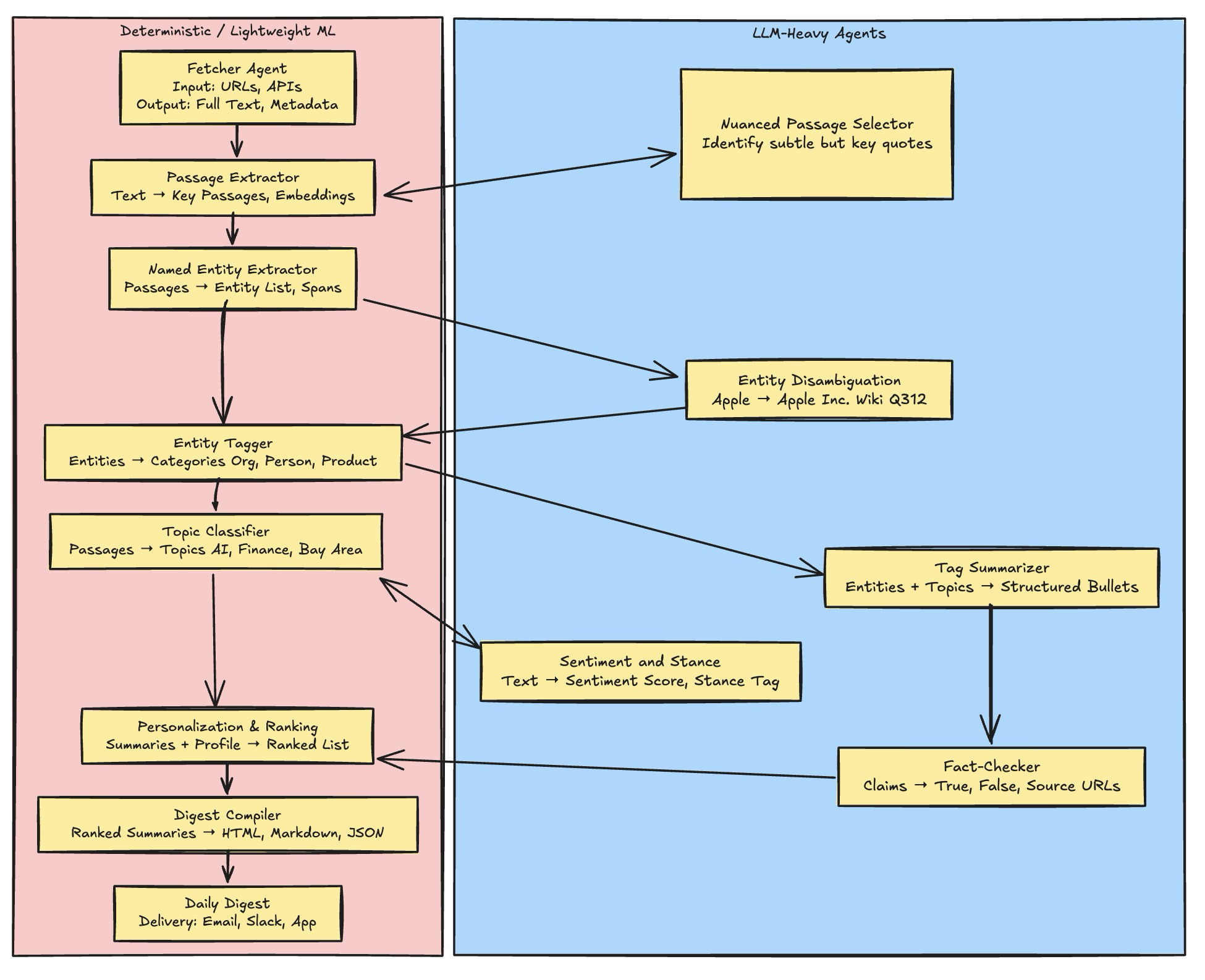
What Comes In and What Goes Out -- Agent interfaces
The table below summarizes what every agent would expect and what it would give back. I also tried to show where agents might interact with LLMs if they need help.
|
Agent |
Inputs |
Outputs |
LLM Needed? |
|---|---|---|---|
|
Fetcher |
News feed URL, RSS, API query |
Full article text, metadata (title, URL, timestamp, source) |
❌ No — HTTP/API call |
|
Passage Extractor |
Full article text |
Key passages, passage embeddings |
✅ Optional — LLM for salience, or embeddings/TF-IDF |
|
Named Entity Extractor |
Passages |
Entity list, spans, embeddings |
❌/✅ — NER models are faster, LLM can catch novel entities |
|
Entity Disambiguation |
Entity list, context embeddings |
Resolved entities with canonical IDs (e.g., Wikidata Q312) |
✅ Yes — reasoning helps resolve ambiguous names |
|
Entity Tagger |
Disambiguated entities |
Entities with categories (Org, Person, Product, Location) |
❌ No — deterministic classification |
|
Topic Classifier |
Passages, embeddings |
Topic labels (AI, Finance, Bay Area) |
❌/✅ — embeddings + clustering or LLM for nuance |
|
Sentiment & Stance Analyzer |
Passages, entities |
Sentiment score, stance (supportive/critical/neutral) |
✅ Optional — LLM for nuance, or sentiment models for speed |
|
Tag Summarizer |
Tagged entities, topics, sentiment |
Structured summaries grouped by tag |
✅ Yes — summarization requires LLM |
|
Fact-Checker |
Summaries, claims |
Verified/Unverified claims, supporting references |
✅ Yes — requires claim extraction + retrieval reasoning |
|
Personalization & Ranking |
Validated summaries, user profile |
Ranked/weighted story list |
❌ No — ML heuristics suffice |
|
Digest Compiler |
Ranked summaries |
Final formatted digest (Markdown, HTML, JSON) |
❌/✅ — deterministic formatting, LLM optional for tone |
|
Daily Digest |
Compiled digest |
Delivery package (email, Slack, app notification) |
❌ No — just delivery |
Some agents require LLM reasoning, others are lightweight and deterministic. This split matters: for production, you’ll want as few LLM calls as possible (to save cost and latency), reserving them for reasoning-heavy tasks like disambiguation, summarization, and fact-checking. I’ve tried to show one of the ways how the split would look like.
A Concrete Example: Bay Area Earthquake
Let’s run a real article through our pipeline. The story:
Title: Magnitude 3.2 earthquake hits near Pleasanton
Source: CBS Bay Area, Sept 7, 2025
Snippet: “A magnitude 3.2 earthquake struck near Pleasanton on Sunday morning, according to the United States Geological Survey. The quake hit just after 10 a.m., about 3 miles north of Pleasanton. Residents across the East Bay reported weak shaking. No immediate reports of damage.”
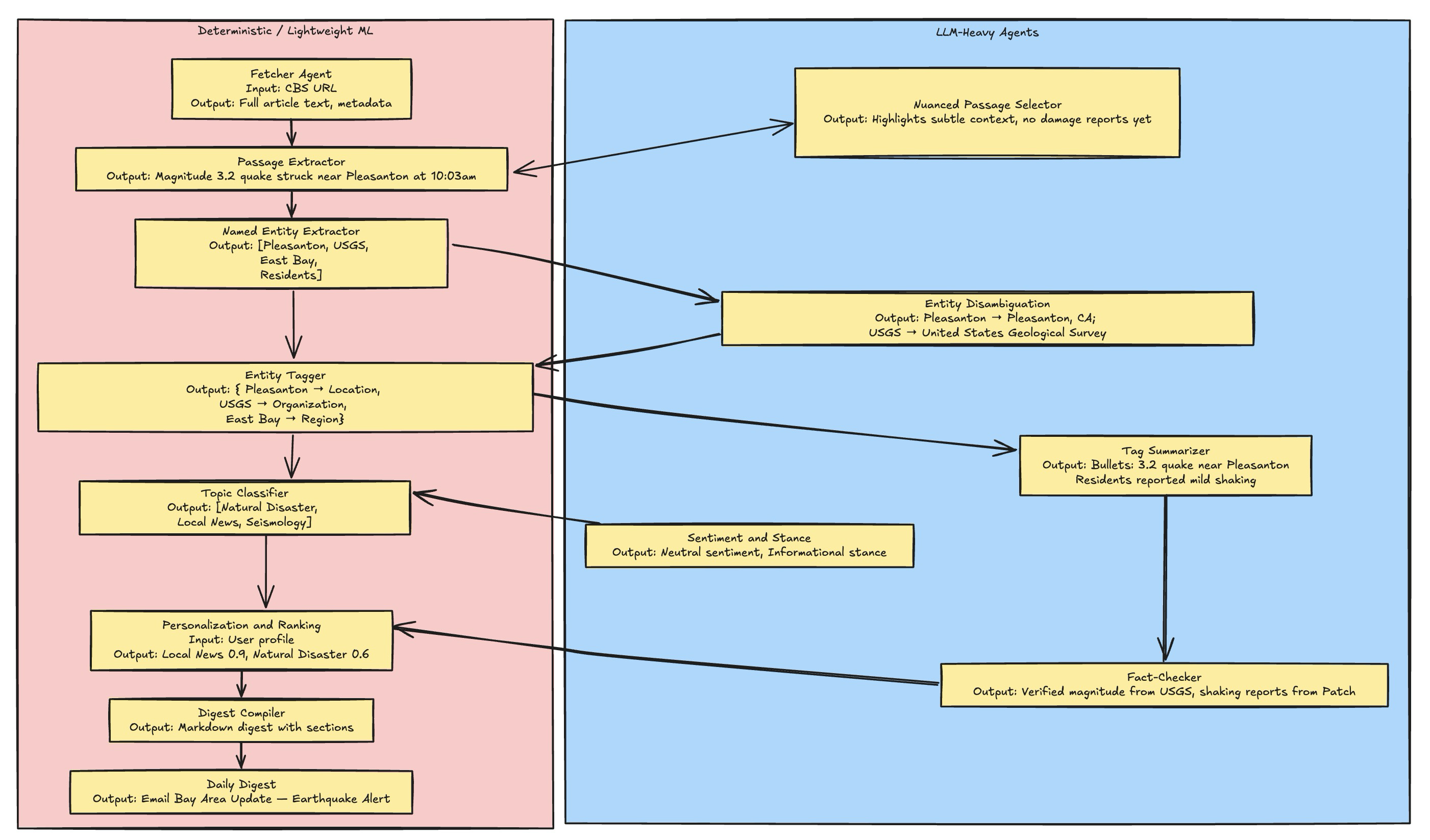
Each of the agents’ responsibilities is summarized below:
- Fetcher Agent: pulls the article text.
- Passage Extractor: highlights quake magnitude, timing, location, and shaking.
- Entity Extractor: identifies Pleasanton, USGS, East Bay.
- Entity Disambiguation: resolves to Pleasanton, CA, and the United States Geological Survey.
- Entity Tagger: classifies Pleasanton → Location; USGS → Organization.
- Topic Classifier: tags as Natural Disaster, Local News, Seismology.
- Sentiment & Stance: neutral, informational.
- Tag Summarizer:
- Local News: “A 3.2-magnitude quake hit Pleasanton; residents felt weak shaking.”
- Natural Disaster: “USGS confirmed the quake’s magnitude; no damage reported.”
- Fact-Checker: confirms magnitude via USGS and shaking reports via Patch.
- Personalization & Ranking: emphasizes Local News (user profile weighted to the Bay Area).
- Digest Compiler + Delivery: sends email with subject “Your Bay Area Update — Earthquake Alert.”
What started as a raw headline became a structured, ranked, fact-checked digest.
Beyond News: Generalizing to Other Feeds
What’s powerful about this agent pipeline is that nothing in it is tied only to news. It’s really a framework for taking any content feed → extracting structure → producing a personalized digest.
Let’s take another example: arXiv papers.
Every day, hundreds of research papers drop across categories like Machine Learning, Computer Vision, or Quantum Computing. For a researcher, the challenge is the same as the news: too much volume, too little time, and only a few papers are truly relevant.
How the Same Agents Apply
Fetcher Agent
- Input: arXiv RSS feed or API query.
- Output: Paper metadata (title, authors, abstract, category).
Passage Extractor Agent
- Input: Abstract text.
- Output: Key sentences (problem statement, method, result).
Named Entity Extractor Agent
- Input: Abstract.
- Output: Entities like “transformer,” “federated learning,” “TPU v5e.”
Entity Disambiguation Agent
- Input: Entities + context.
- Output: Links to canonical IDs (e.g., arXiv subject codes, Wikipedia entries).
Entity Tagger Agent
- Input: Resolved entities.
- Output: Categories: Algorithm, Dataset, Hardware, Domain.
Topic Classifier Agent
- Input: Abstract embeddings.
- Output: Tags like {Deep Learning, Reinforcement Learning, Distributed Systems}.
Sentiment & Stance Agent
- Input: Abstract.
- Output: “Positive result” (model beats SOTA by 2%), “Critical” (paper refutes prior claim).
Tag Summarizer Agent
- Input: Entities + topics.
- Output:
-
Distributed Training: “New optimizer reduces GPU communication overhead by 30%.”
-
NLP: “Transformer variant improves long-context understanding.”
-
Fact-Checker Agent
- Input: Claims in abstract.
- Output: Basic validation against cited benchmarks, prior arXiv papers.
Personalization & Ranking Agent
- Input: Summaries + user profile.
- Output: Weighted list — e.g., ML (0.9), Systems (0.7), Theory (0.2).
Digest Compiler Agent
- Output: A daily “Research Digest” grouped by topics you care about.
Daily Digest Agent
- Output: Email / Slack message titled “Your Research Updates — Sept 7, 2025.”
Example Output
Machine Learning
- “A new optimizer for distributed training reduces GPU communication overhead by 30%.”
- “Transformer variant improves long-context understanding.”
Systems
- “Novel checkpointing approach for TPU workloads improves reliability.”
Theory
- “Paper refutes prior bounds on sparse recovery in high-dimensional settings.”
The General Principle
Whether it’s:
- News articles (politics, finance, Bay Area local updates),
- Academic papers (arXiv, PubMed),
- Internal company reports (logs, metrics dashboards),
…the same agent pipeline applies.
You’re always doing:
- Fetch content.
- Extract passages.
- Identify entities, disambiguate them.
- Tag and classify.
- Summarize and fact-check.
- Rank based on user profile.
- Deliver as a digest.
That’s the feed-to-digest pattern, and agents are a natural way to implement it.
MCP: The Protocol That Lets Agents Talk
When you chain multiple agents together, two big challenges show up:
-
Inter-agent communication — How does the Passage Extractor know how to hand results to the Entity Disambiguation Agent?
-
External integrations — How do agents fetch data from APIs (like arXiv, USGS, or RSS feeds) without each agent reinventing its own protocol?
This is where MCP (Model Context Protocol) comes in.
What is MCP?
Think of MCP as the USB standard for AI agents.
- It defines interfaces for tools and services.
- It specifies how agents pass context (inputs, outputs, metadata).
- It allows interoperability — meaning you can swap one agent out for another without breaking the pipeline.
With MCP, the Passage Extractor doesn’t need to “know” the implementation details of the Entity Tagger. It just sends structured data (text + embeddings + tags) in a format MCP understands.
Internal Communication
Inside our pipeline:
- Fetcher Agent outputs
{title, body, url, timestamp}in MCP format. - Passage Extractor takes
{body}and returns{passages, embeddings}. - Named Entity Extractor consumes
{passages}and produces{entities}. - Entity Disambiguation consumes
{entities, context}and produces{entity_id}.
Each agent talks the same “language” thanks to MCP.
External Communication
MCP also works outward. For example:
- The Fetcher Agent uses MCP to call an arXiv API or an RSS feed.
- The Fact-Checker Agent uses MCP to query Wikipedia or a news database.
- The Daily Digest Agent uses MCP to deliver results via email or Slack.
The benefit is that agents can integrate with any external tool as long as that tool speaks MCP, just like plugging any USB device into your laptop.
Why This Matters
Without MCP, every agent would need custom adapters — a brittle mess of one-off integrations. With MCP:
- Standardized contracts → each agent’s input/output is predictable.
- Plug-and-play architecture → you can replace the Sentiment Agent with a better one tomorrow.
- Scalability → dozens of agents can coordinate without spaghetti code.
In other words, MCP is what turns a collection of scripts into a modular, extensible agent platform.
Closing Thoughts
The journey from a flat, keyword-based feed → to a newsroom of agents → to a generalized digesting platform mirrors how software evolves: from scripts to systems to ecosystems.
News today, arXiv tomorrow, logs and dashboards the day after. The pattern is the same: feed-to-digest, powered by agents. And with MCP providing the glue, these agents stop being isolated hacks and start working as part of a larger, interoperable system.
Don’t get caught up in the “agentic AI” hype — write better tools with strong fundamentals, and leverage LLMs where they add value: to refine, summarize, and iterate.
In the next part, I’ll dive into how you can implement the multi-agent systems with MCP.
[story continues]
tags