
1.0 Introduction
A traditional offline RAG system works for straightforward question-answering effectively: a question goes in, relevant document chunks are retrieved, and an answer comes out.
But real-world applications quickly expose limitations. Some queries require multiple retrieval passes to gather comprehensive context. Others need no retrieval at all; asking “What is 25 times 4?” shouldn't trigger a document search. Asking a follow up question regarding previous outputs should be handled through proper planning, not direct retrievals. Also, when generated answers miss the mark, there's no mechanism to catch errors and retry intelligently.
This post addresses these limitations by evolving from basic RAG to Agentic RAG: a four-agent architecture where specialized agents collaborate to handle queries far more intelligently than a single-pass system. The system plans before acting, evaluates its own output, and retries when necessary; all while maintaining complete offline operation.
While this serves as a sequel to the original post, everything needed to understand and implement this system is covered here. Readers can follow along step-by-step without prior context. The previous article, Building a RAG System That Runs Completely Offline (available at https://hackernoon.com/building-a-rag-system-that-runs-completely-offline), demonstrated how to create a privacy-focused offline based RAG system using Ollama, FAISS, and Llama 3.2.
TLDR: Full notebook implementation here: https://github.com/teedonk/offline-Agentic-RAG-system
1.1 What Makes This "Agentic"?
Traditional RAG systems follow a simple linear pipeline: retrieve relevant documents from a vector database, add them as context to a user query, and generate an answer using an LLM. This approach operates as a single-pass process which makes every query triggers retrieval with no quality checks or ability to adapt if retrieval fails or the answer is poor. This agentic system transforms that rigid pipeline into an adaptive, multi-agent architecture where four specialized agents: Planning, Retrieval, Generator, and Judge; work collaboratively with distinct responsibilities. The key difference is autonomous decision-making and intelligent feedback loops: the Judge agent evaluates answer quality and triggers retries with specific improvement strategies like query expansion or context deepening, while agents use tools strategically and maintain conversation memory across queries. Instead of blindly executing a fixed sequence, this system reasons about tasks, adapts its approach based on feedback, and self-corrects until producing high-quality answers; a characteristics that define true agentic behavior rather than simple automation.
The implementation covered in this post realizes all of these capabilities through four specialized agents, each with clear responsibilities, specific tool access, and strict boundaries.
1.2 The Four-Agent Architecture
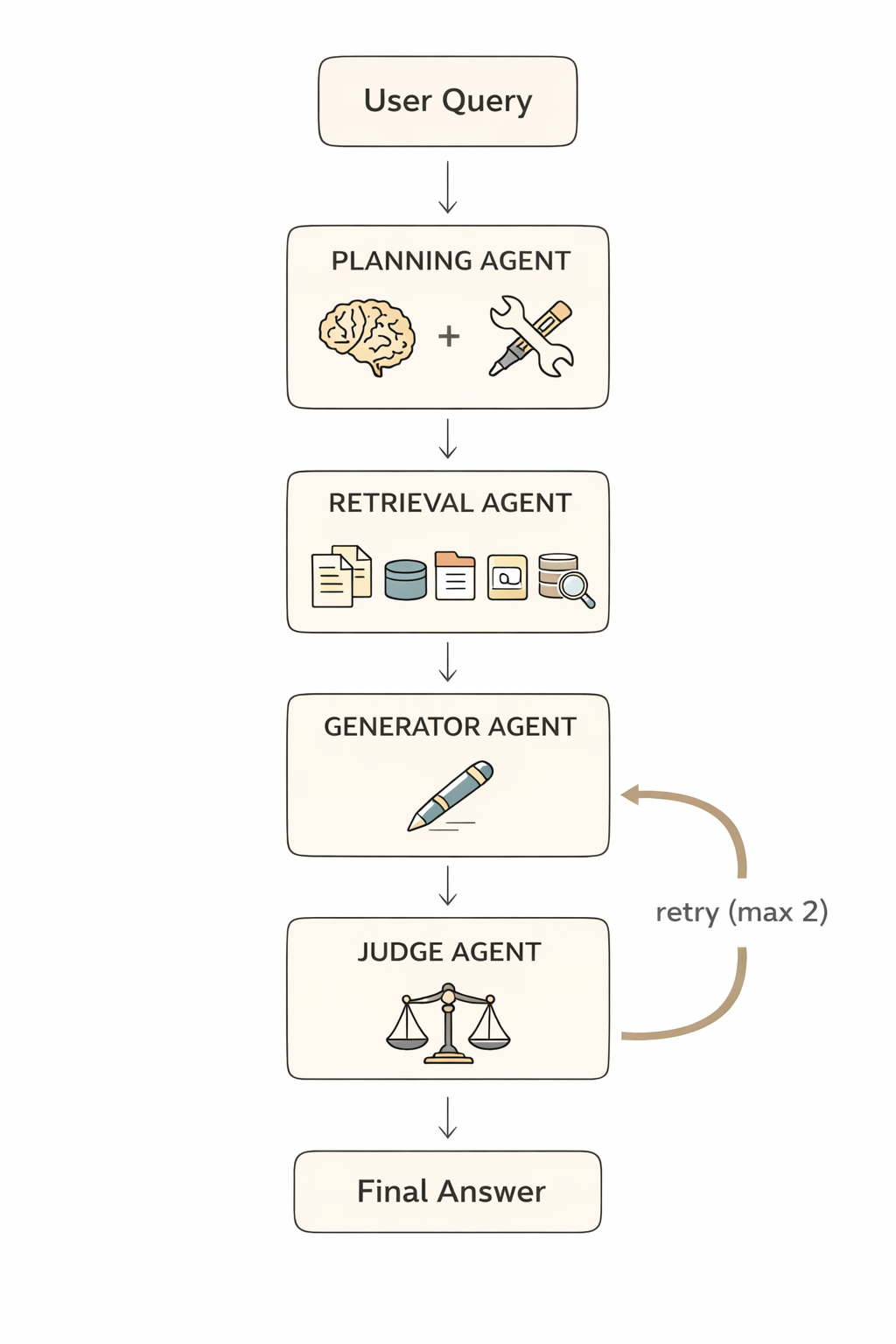
The pipeline processes queries through four sequential stages:
Planning Agent receives the user query and makes a critical decision: Does this need document retrieval? If yes, what specific queries should be executed? The agent outputs a structured JSON plan with retrieval queries and reasoning.
Retrieval Agent executes that plan using hybrid search (combining semantic FAISS search with BM25 keyword matching). It gathers relevant chunks, calculates confidence scores, and aggregates context. Importantly, this agent does not generate answers; that responsibility belongs elsewhere.
Generator Agent takes the retrieved context and synthesizes an answer. This agent has zero tool access; an intentional design choice. By restricting it to only the provided context, hallucination is prevented. The generator cannot fetch additional information that might lead to unfounded claims.
Judge Agent evaluates the generated answer on three criteria: coverage (did it address all parts of the query?), relevance (is it actually about what was asked?), and faithfulness (does it stay true to the context without hallucination?). If evaluation fails, the Judge provides specific feedback and triggers regeneration.
Bounded Iteration: The system allows a maximum of two regeneration attempts. This prevents infinite loops while still catching and correcting obvious failures. The system will always return a result in predictable time.
1.3 Prerequisites and Setup;
Before starting, ensure the following are installed and configured:
# Windows:
Visit: https://ollama.com/download
Download the Windows installer
Run the installer
Open PowerShell and verify: ollama --version
# Install Ollama (Linux)
curl -fsSL https://ollama.com/install.sh | sh
# Start Ollama service
ollama serve
# Download models (one-time, requires internet)
ollama pull llama3.2
ollama pull nomic-embed-text
# Install Python packages
pip install langchain langchain-ollama langchain-community faiss-cpu PyPDF2 psutil
Ollama makes running LLMs locally straightforward with one-command model downloads, automatic GPU detection, and built-in memory management. The langchain-ollama integration works seamlessly for both chat and embeddings.
Llama 3.2 was chosen as the Base Model. The 3B parameter version fits comfortably on consumer hardware while delivering solid reasoning and instruction-following. For an agentic system, reliable structured JSON output is essential; Llama 3.2 handles this consistently well with low temperature settings (0.1), making it ideal for the multi-agent architecture where agents must communicate through structured formats. LangChain for Agent Orchestration. LangChain provides the abstractions needed for agent-based systems; prompt templates, output parsers, tool definitions, and chain composition. FAISS + BM25 for Hybrid Search. This implementation combines FAISS semantic search with BM25 keyword matching for comprehensive retrieval.
Once models and libraries are downloaded, everything runs completely offline. No API keys, no usage costs, no data leaving the machine.
2.0 Implementation
2.1 Configuration and Memory Optimization
Setting environment variables before importing LangChain prevents memory issues during embedding generation:
import os
from pathlib import Path
# Force offline mode
os.environ["TRANSFORMERS_OFFLINE"] = "1"
os.environ["HF_DATASETS_OFFLINE"] = "1"
# Ollama memory optimization (MUST be set BEFORE imports)
os.environ["OLLAMA_MAX_LOADED_MODELS"] = "1" # Single model only
os.environ["OLLAMA_NUM_PARALLEL"] = "1" # No parallel requests
os.environ["OLLAMA_FLASH_ATTENTION"] = "1" # Flash attention
os.environ["OLLAMA_MMAP"] = "1" # Memory mapping
# Configuration
OLLAMA_BASE_URL = "http://localhost:11434"
LLM_MODEL = "llama3.2"
EMBEDDING_MODEL = "nomic-embed-text"
CHUNK_SIZE = 1000
CHUNK_OVERLAP = 200
Memory optimization requires setting environment variables before importing LangChain:
2.2 Initializing the LLM and Embeddings
With LangChain's Ollama integration, model setup is straightforward. Low temperature (0.1) produces deterministic, focused outputs; important for reliable JSON from the Planning Agent:
from langchain_ollama import ChatOllama, OllamaEmbeddings
def create_llm(temperature=0.1, max_tokens=2048):
return ChatOllama(
model=LLM_MODEL,
base_url=OLLAMA_BASE_URL,
temperature=temperature,
num_predict=max_tokens
)
def create_embeddings():
return OllamaEmbeddings(
model=EMBEDDING_MODEL,
base_url=OLLAMA_BASE_URL
)
llm = create_llm()
embeddings = create_embeddings()
2.3 The Tool System
Tools are functions that agents can call. The current tool design is tailored for the current solution; the tools setup can be extended for further agentic operations. The key design principle implemented: not every agent gets every tool. This enforces separation of concerns and prevents agents from overstepping their roles.
Five tools are available, each with a specific purpose:
• retrieve_documents: Hybrid semantic + BM25 search with dynamic k, query expansion, and confidence scoring
• list_available_documents: Lists files in the documents directory with metadata
• read_document: Reads full document content with enhanced PDF extraction
• search_metadata: Keyword search in filenames and metadata
• summarize_text: LLM-enhanced or rule-based text summarization
Tool Access by Agent:
• Planning Agent: list_available_documents, search_metadata (2 tools)
• Retrieval Agent: All five tools
• Generator Agent: None (forces use of provided context only)
• Judge Agent: None (evaluates based on provided information)
For simplicity, the implementation of the tools is not covered in this post. The full implementation can be found in the Github repo
2.4 Hybrid Retrieval with Confidence Scoring
The retrieval function combines semantic and keyword search for comprehensive results:
def retrieve_documents_fn(query: str, k: int = None) -> str:
"""Hybrid semantic + BM25 retrieval with confidence scoring."""
# Calculate dynamic k based on query complexity
if k is None:
k = calculate_dynamic_k(query)
# Expand query with synonyms
expanded_terms = expand_query(query)
# 1. Semantic search with FAISS
semantic_results = vector_store.similarity_search_with_score(
query, k=k * 2 # Fetch more for re-ranking
)
# 2. BM25 scoring for keyword matching
bm25_scores = calculate_bm25_scores(query, documents)
# 3. Combine scores: 60% semantic + 40% BM25
hybrid_score = 0.6 * semantic_sim + 0.4 * bm25_normalized
# 4. Calculate confidence and highlight sources
confidence, explanation = calculate_confidence_score(...)
highlighted = highlight_sources(content, query)
This implementation combines FAISS semantic search with BM25 keyword matching for comprehensive retrieval. Semantic search captures conceptual similarity while BM25 ensures exact keyword matches aren't missed. Results are re-ranked using a weighted combination (60% semantic, 40% BM25). Enhanced features include dynamic k calculation based on query complexity, query expansion with synonyms, confidence scoring for result quality, and source highlighting for relevant passages.
2.5 The Planning Agent
The Planning Agent interprets queries and creates structured retrieval plans. It recognizes when no retrieval is needed (arithmetic, greetings) versus when document search is essential.
PLANNING_AGENT_PROMPT = """You are a Planning Agent. Analyze the query
and create a retrieval plan.
AVAILABLE DOCUMENTS: {available_docs}
USER QUERY: {query}
QUERIES THAT DO NOT NEED RETRIEVAL:
- Arithmetic: "What is 5*5?"
- Greetings: "Hello", "How are you?"
- General knowledge not in documents
OUTPUT FORMAT (JSON only):
{{
"needs_retrieval": true or false,
"retrieval_queries": ["query1", "query2"] or [],
"reasoning": "Brief explanation"
}}"""
The agent class formats the prompt, invokes the LLM, and parses the JSON response with robust fallback handling for malformed output.
2.6 The Generator Agent (No Tools)
This design choice deserves emphasis: the Generator Agent has zero tool access. This was implemented as a feature, not a limitation.
When an LLM has tools, it can fetch additional information. While seemingly helpful, this opens the door to hallucination; the model might confidently state something it "retrieved" that isn't actually in the documents. By restricting the Generator to only the context provided by the Retrieval Agent, the system forces grounded responses.
class GeneratorAgent:
def __init__(self, llm):
self.llm = llm
self.tools = [] # INTENTIONALLY EMPTY
def generate(self, query: str, retrieval_result: Dict) -> Dict:
context = retrieval_result.get("context", "")
if not context: # No retrieval performed
# Use direct answer prompt
messages = self.no_retrieval_prompt.format_messages(query=query)
else:
# Use context-based prompt
messages = self.prompt.format_messages(query=query, context=context)
response = self.llm.invoke(messages)
return {"answer": response.content}
2.7 The Judge Agent and Evaluation
The Judge enables self-correction by evaluating every generated answer on three criteria, each scored 1-5:
1. Coverage: Does the answer address all parts of the query?
2. Relevance: Is the answer actually about what was asked?
3. Faithfulness: Does the answer stay true to the context (no hallucination)?
If all scores are 3 or above, the answer passes. Otherwise, the Judge provides specific feedback, and the system determines the appropriate retry strategy.
2.8 Intelligent Retry Strategies
When the Judge rejects an answer, the system doesn't just blindly retry. It analyzes the feedback to determine the best recovery approach:
reformulate_and_retrieve: When the Judge indicates missing information, the system generates new, targeted queries and performs fresh retrieval.
regenerate_with_instruction: When relevant information exists in the context but was poorly used, the system regenerates with clearer instructions using the same context.
regenerate_stricter: When hallucination is detected, the system regenerates with strict faithfulness constraints, explicitly warning against unsupported claims.
The strategy is determined using LLM-based feedback classification with keyword-based fallback for reliability:
def decide_retry_strategy_with_llm(feedback, context, answer, llm=None):
"""Analyze feedback to determine optimal retry strategy."""
# Try LLM classification first
if llm is not None:
category = llm.invoke(classification_prompt)
if "MISSING" in category:
return "reformulate_and_retrieve"
elif "HALLUCIN" in category:
return "regenerate_stricter"
elif "MISSED" in category:
return "regenerate_with_instruction"
# Fallback to keyword-based classification
return decide_retry_strategy_keywords(feedback, context, answer)
2.9 Conversation Memory
For coherent multi-turn interactions, the system maintains conversation memory storing recent query-answer pairs:
class ConversationMemory:
def __init__(self, max_turns: int = 5):
self.history = deque(maxlen=max_turns)
def add(self, query: str, answer: str, sources: List[str] = None):
"""Add a query-answer pair to memory."""
self.history.append({
"query": query,
"answer": answer[:500] + "..." if len(answer) > 500 else answer,
"sources": sources or []
})
def get_context(self) -> str:
"""Get formatted conversation history."""
# Returns formatted Q1/A1, Q2/A2, etc.
This enables follow-up questions like "Can you elaborate on the first point?" to work correctly by providing the previous context to the agents.
3.0 Testing and Results
The system was tested with various query types to validate the agent coordination and retry mechanisms.
3.1 Basic Retrieval Query
Query: "What are the main topics covered in my documents?"
Output:
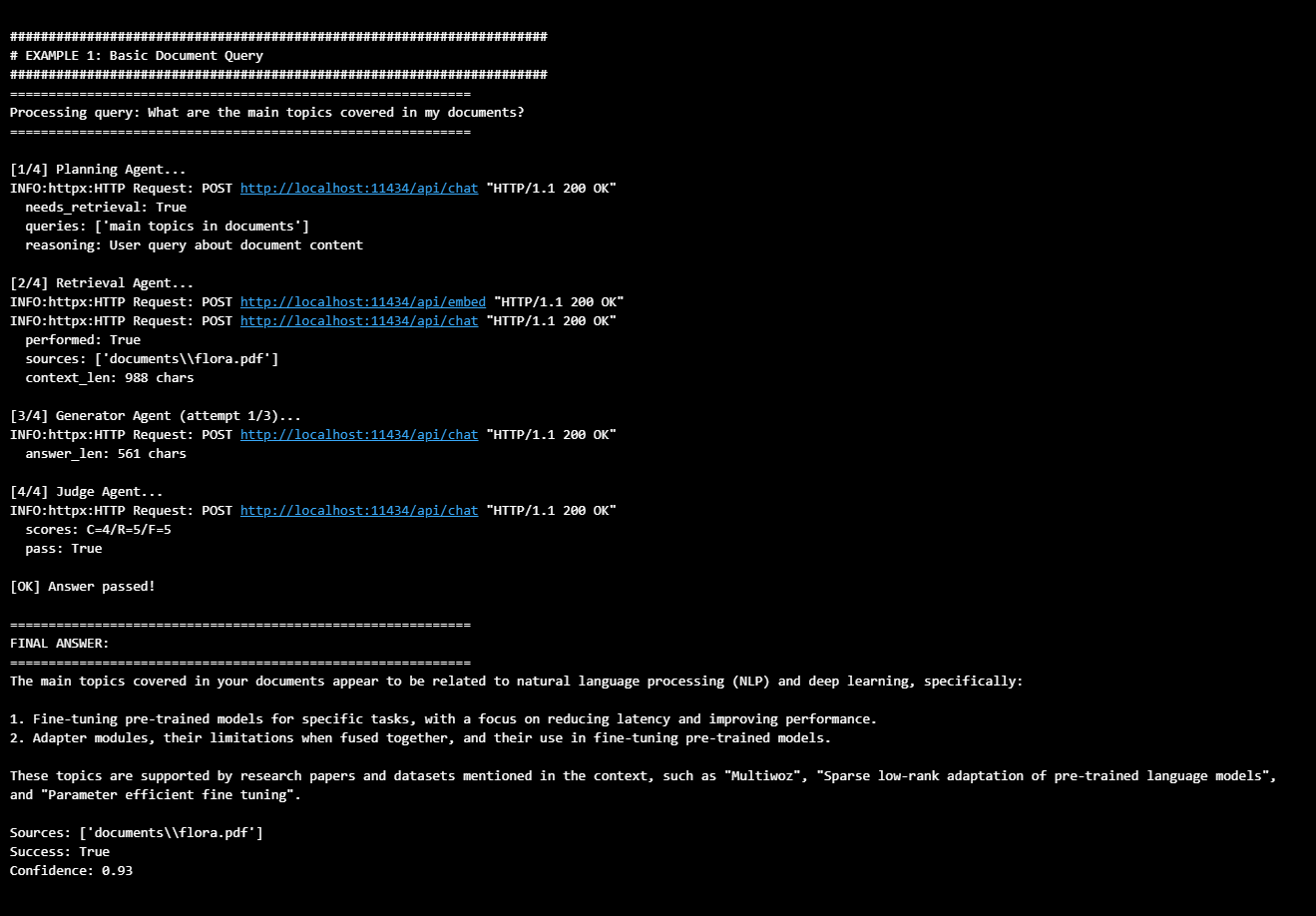
Result: The system correctly identified this as a retrieval task, generated focused queries, retrieved relevant chunks with confidence scores, and produced a grounded answer citing specific sources. Judge scores: Coverage 4/5, Relevance 5/5, Faithfulness 5/5.
3.2 No Retrieval Needed
Query: "What is 25 times 4?"
Output:
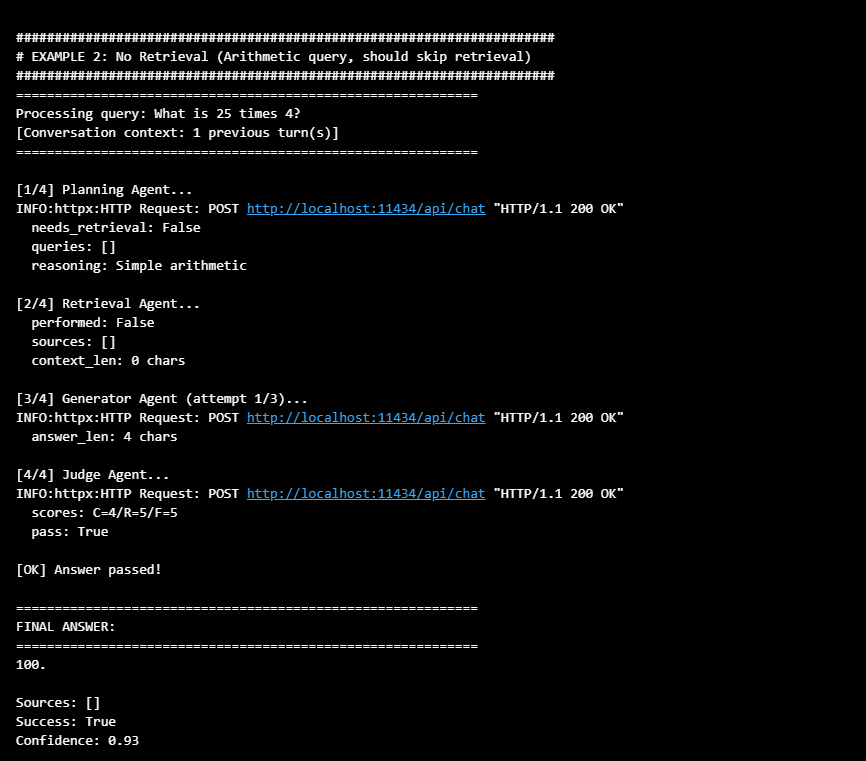
Result: The Planning Agent correctly identified this as not needing retrieval. The Generator answered "100" directly without unnecessary vector searches.
3.3 Complex Query Decomposition
This example tests the planning agent's query decomposition
Query: "Summarize the key concepts and their relationships in my documents."
Output:
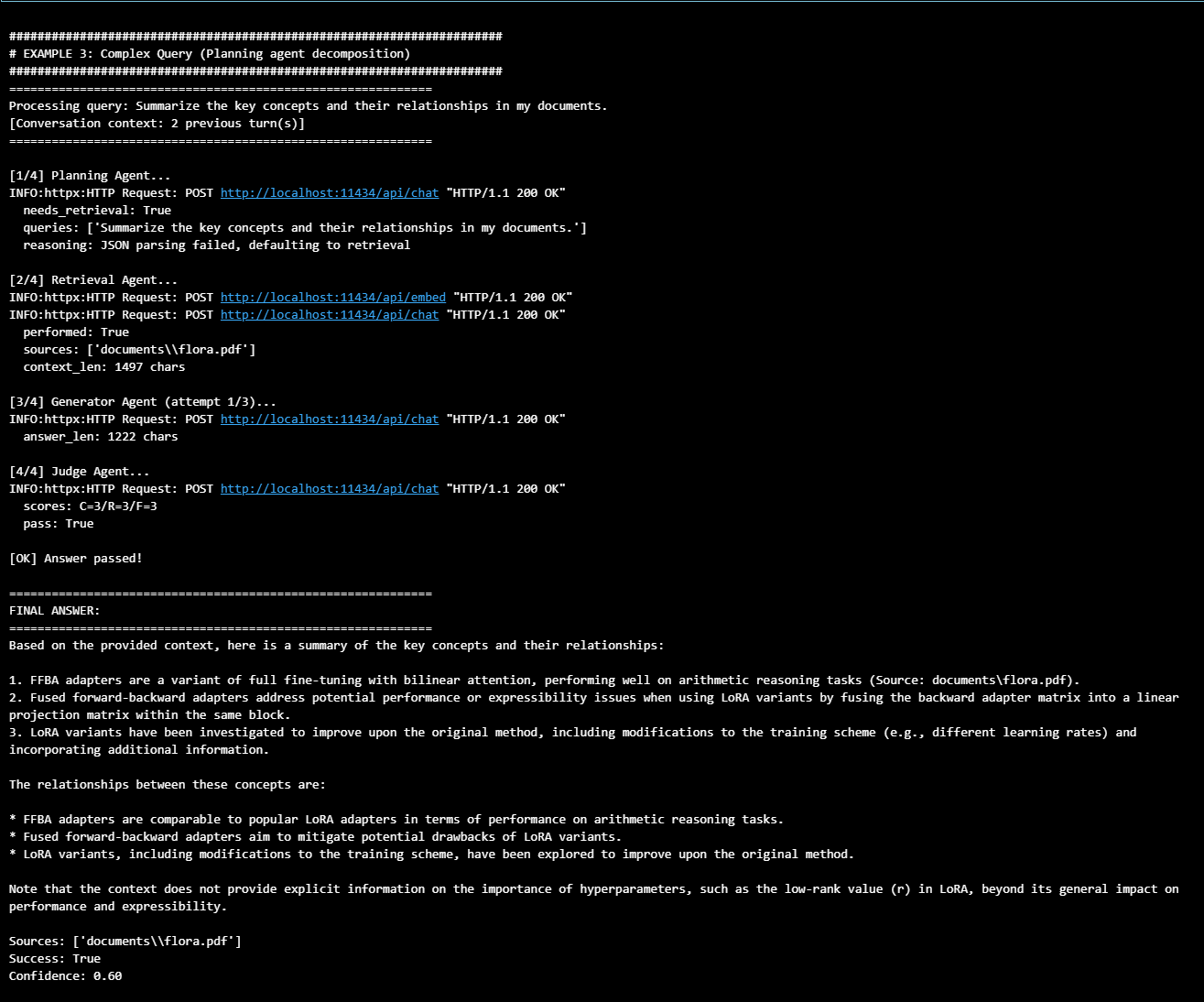
Result: The Planning Agent analyzed the complex summarization query and correctly identified it required document retrieval, maintaining the full query scope rather than over-fragmenting it. The system successfully retrieved relevant context about LoRA variants and FFBA adapters, then the Generator Agent synthesized a structured summary organizing key concepts (FFBA adapters, fused forward-backward adapters, LoRA variants) and their relationships. The Judge Agent validated the answer's completeness with moderate confidence (60%), demonstrating the system's ability to handle multi-faceted queries that require both information gathering and conceptual synthesis.
3.4 Follow-up Query with Memory
This example tests the memory for follow up questions.
Query: "Can you elaborate on the first point you mentioned?"
Output:
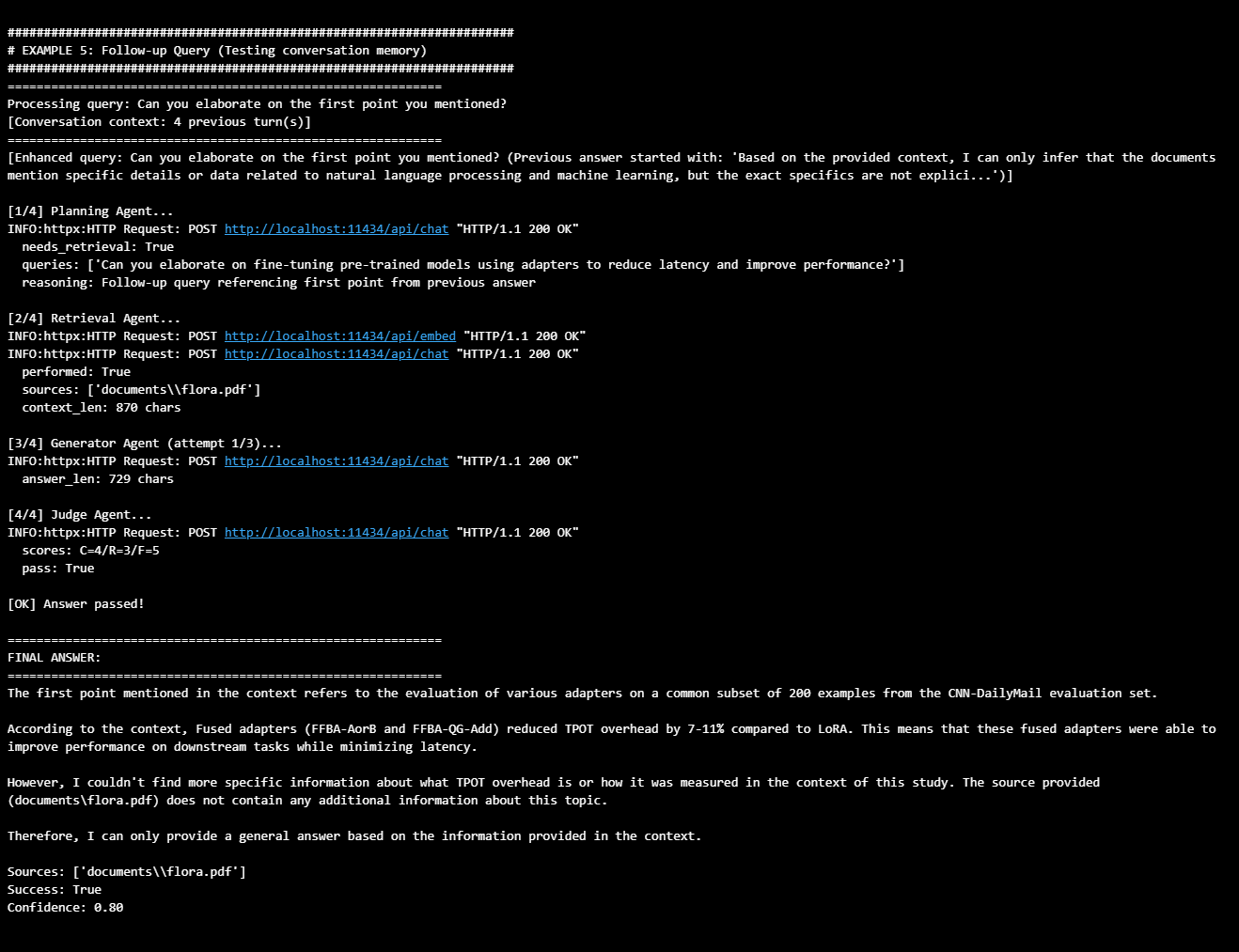
Result: The system successfully handled the ambiguous follow-up query "Can you elaborate on the first point you mentioned?" by leveraging conversation memory from 4 previous turns. The enhanced query mechanism appended a snippet of the previous answer (first 200 characters) to provide context. The Planning Agent analyzed this enhanced query and correctly identified the reference as relating to "fine-tuning pre-trained models using adapters to reduce latency and improve performance," formulating a specific retrieval query rather than a generic pass-through. The Retrieval Agent fetched 870 characters of relevant context from the flora.pdf document. The Generator Agent synthesized an answer explaining that the first point referred to adapter evaluation results, specifically mentioning that Fused adapters (FFBA-AorB and FFBA-QG-Add) reduced TPOT overhead by 7-11% compared to LoRA. The Judge Agent evaluated the answer with scores of C=4/R=3/F=5 and passed it on the first attempt with 80% confidence, requiring no retry. The answer acknowledges information limitations while providing substantive content about the referenced topic, demonstrating functional reference resolution and targeted information retrieval.
4.0 Conclusion
This implementation demonstrates significant advancement from basic offline RAG to an intelligent offline based agentic system. By adding specialized agents with clear responsibilities, bounded tools, self-evaluation, and conversation memory, the system behaves far more intelligently while maintaining complete offline operation.
Key Takeaways:
• Separation matters. Each agent does one thing well. The Planner plans, the Retriever retrieves, the Generator generates, and the Judge evaluates.
• Tool restrictions prevent hallucination. By giving the Generator no tools, the system forces it to use only provided context.
• Hybrid search improves results. Combining semantic FAISS search with BM25 keyword matching catches both conceptual and exact matches.
• Intelligent retry beats blind retry. Analyzing feedback to choose the right strategy (reformulate, instruct, or restrict) produces better recovery.
• Bounded iteration ensures reliability. Maximum two regeneration attempts means predictable execution time.
• Offline operation is fully achievable. With Ollama and FAISS, everything runs locally after initial setup.
The complete implementation is available in the accompanying notebook. The entire implementation can be modified for other agentic tasks by adding more tools and modifying the agent prompts, to adapt the system for specific use cases. Privacy, performance, and intelligence are not competing priorities; with the right architecture, all three are achievable simultaneously.
5.0 References
[1] Part 1: Building a RAG System That Runs Completely Offline - HackerNoon
[2] FLoRA: Low-Rank Core Space for N-dimension (2024), arXiv:2511.00050
[3] LangChain Documentation: python.langchain.com
[4] Ollama Documentation: ollama.com
[5] FAISS: A Library for Efficient Similarity Search - Meta AI Research
[6] BM25: Robertson, S., & Zaragoza, H. (2009). The Probabilistic Relevance Framework
Full notebook file can be found here: https://github.com/teedonk/offline-Agentic-RAG-system
Linkedin: Linkedin
[story continues]
tags