
How Nvidia Learned to Stop Worrying and Acquired Groq
0. Preface
On Christmas Eve 2025, the AI world was rocked. Nvidia, the undisputed king of AI hardware, made its largest acquisition to date: a staggering $20 billion bid for Groq, a name few outside the industry had heard of. Why would Nvidia pay such a colossal sum for this dark horse?
I got interested in Groq’s technology and commercial potential since 2023, and have been testing their cloud-based inference service for open source LLM. I’m both excited and not surprised that Groq’s singular focus, killer technology and years of hardwork finally paid off.
This article dives deep into the Groq architecture, revealing why it's shattering LLM inference speed records. We'll pit Groq’s Language Processing Unit (LPU) against the giants: Nvidia GPU and Google TPU, to see if the crown is truly changing hands. Plus, discover the incredible backstory of Groq’s founder & CEO, Jonathan Ross, who happens to be one of the original masterminds behind the very Google TPU that Groq is now challenging.
1. Introduction: The Millisecond Imperative
In modern data centers, the focus is shifting from AI training to AI inference - the instantaneous application of digital minds. For users interacting with Large Language Models (LLMs), the defining constraint is latency. This delay is not a software failure, but a hardware limitation, as existing architectures like the Graphics Processing Unit (GPU) were not designed for token-by-token language generation.
Groq, founded by the architects of Google’s original Tensor Processing Unit (TPU), tackles this specific challenge. Their solution is the Language Processing Unit (LPU), a "software-defined" chip that abandons traditional processor design for speed. By using deterministic, clockwork execution and static scheduling, Groq's LPU breaks the "Memory Wall," achieving text generation speeds exceeding 1,600 tokens per second, vastly outpacing human reading speed.
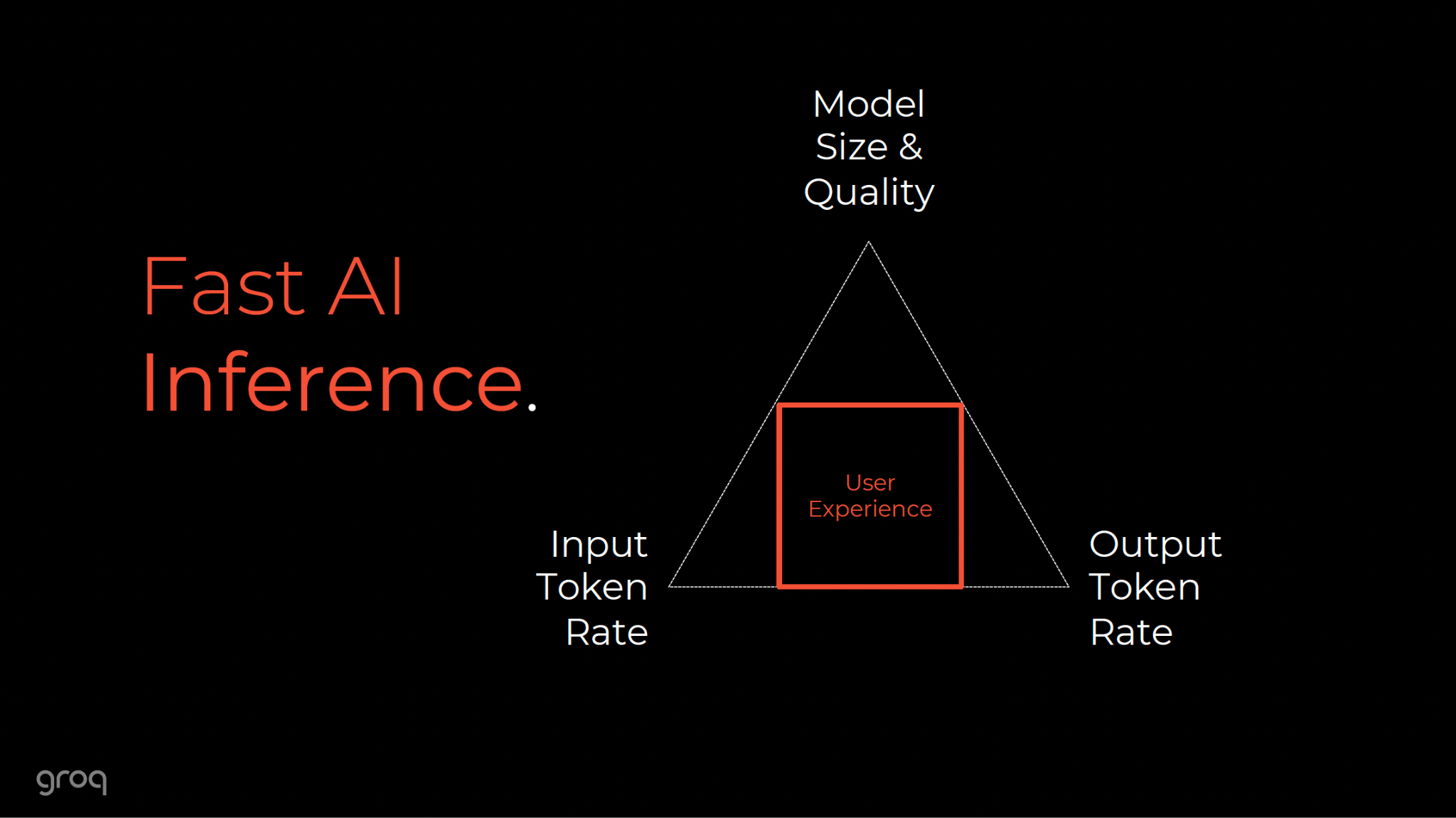
2. The Inference Crisis: Why Modern AI is "Slow"
To understand Groq’s innovation, one must first appreciate the specific behavior of Large Language Models on current hardware. The computational workload of an AI model changes drastically depending on whether it is learning (training) or thinking (inference).
2.1 The Physics of Autoregressive Generation
Training a model is a high-bandwidth, parallel task. You feed the system thousands of sentences simultaneously, and the chip updates its internal weights based on the aggregate error. It is like grading a thousand exams at once; you can optimize the workflow for throughput.
Inference, however, specifically for LLMs, is "autoregressive." The model generates one word (or token) at a time. It predicts the first word, appends it to the input, predicts the second word, appends it, and so on. This process is inherently serial. You cannot calculate the tenth word until you have calculated the ninth.
For a hardware engineer, this is a nightmare. In a modern GPU architecture, the compute cores (where the math happens) are separated from the memory (where the model lives) by a physical distance. This separation creates the "Von Neumann Bottleneck." Every time the model needs to generate a token, the GPU must fetch the entire model from memory, process it, and send it back.
For a 70-billion parameter model like Llama 3, which can weigh around 140 gigabytes (at 16-bit precision), this means the chip must move 140GB of data across the wire just to generate a single word.3 It must do this over and over again, tens of times per second.
2.2 The Memory Wall
The result is that the most powerful compute engines in the world spend most of their time waiting. This phenomenon is known as the "Memory Wall."
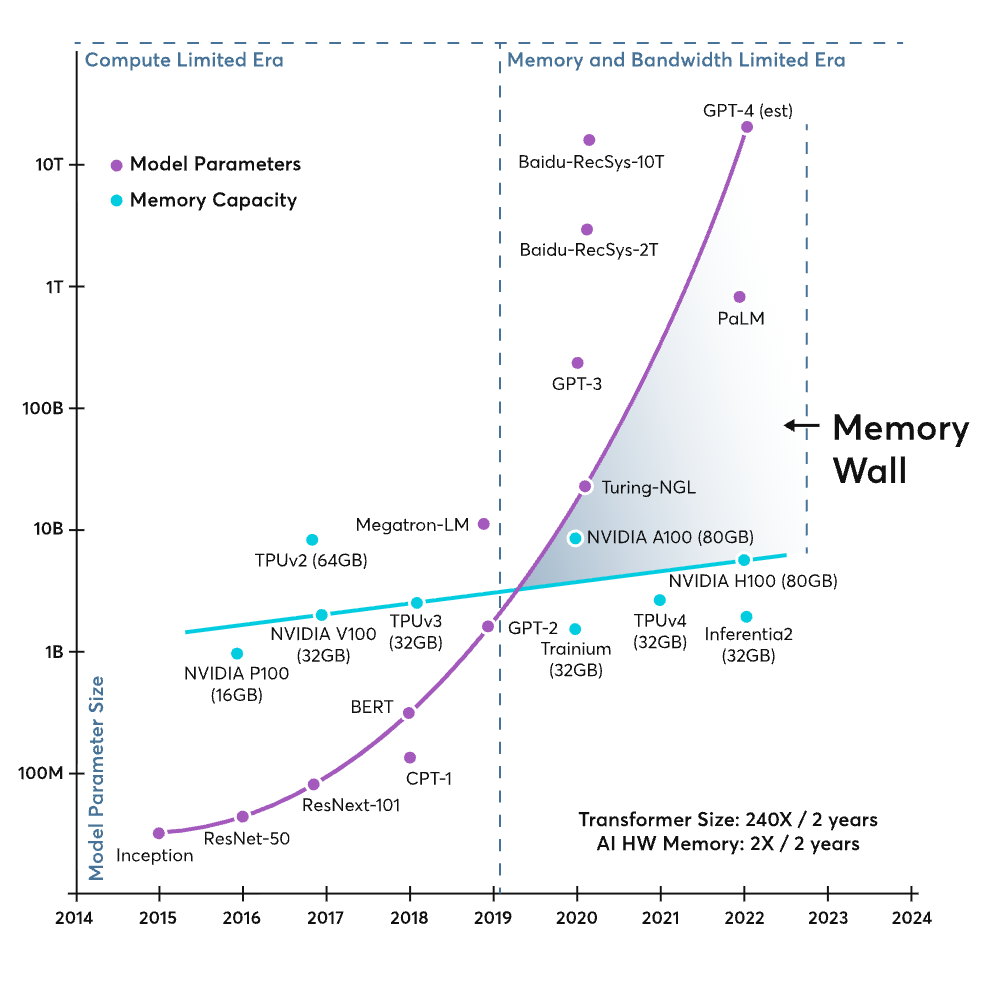
- Starvation: In a typical inference scenario (Batch Size 1), the arithmetic units of an Nvidia H100 are idle for a vast majority of the clock cycles, waiting for data to arrive from the High Bandwidth Memory (HBM).
- The Bandwidth Limit: Even with the H100’s impressive 3.35 Terabytes per second (TB/s) of memory bandwidth, the physics of moving data limits the generation speed to roughly 100-200 tokens per second under ideal conditions.4
- Energy Waste: It costs significantly more energy to move data than to compute on it. A study by Groq suggests that traditional GPU setups burn 10 to 30 Joules per token, largely due to this constant shuttling of data between HBM and the core. In contrast, keeping data local reduces this to 1-3 Joules.6
2.3 The Tail Latency Problem
The problem is compounded by the "dynamic" nature of modern processors. CPUs and GPUs are designed to be generalists. They have complex hardware components—caches, branch predictors, out-of-order execution engines—that try to guess what the software wants to do next.
When these guesses are wrong (a "cache miss" or "branch misprediction"), the processor stalls. In a shared data center environment, where multiple users are competing for resources, this leads to "jitter" or variable latency.
- Tail Latency: This is the latency of the slowest requests—the 99th percentile. For real-time applications like voice agents or algorithmic trading, the average speed doesn't matter; the slowest speed does. If one token takes 10ms and the next takes 50ms, the user experience fractures.8
- The Orchestration Tax: To manage this chaos, GPUs use complex software kernels (like CUDA) and hardware schedulers. These add overhead. The chip is constantly stopping to ask: "What do I do next? Is the data here yet?"
Groq’s founding thesis was simple: What if we removed the question mark? What if the chip never had to ask what to do, because it already knew?
3. The Philosophy of the LPU: Software-Defined Hardware

The Language Processing Unit (LPU) is the physical manifestation of a philosophy that rejects the last thirty years of processor evolution. Founded by Jonathan Ross, who previously led the Google TPU project, Groq started with a "Software-First" approach.10
3.1 The Compiler is the Captain
In a traditional system, the compiler (the software that translates code into chip instructions) is subservient to the hardware. It produces a rough guide, and the hardware’s internal logic (schedulers, reorder buffers) figures out the details at runtime.
Groq flips this. The LPU hardware is deliberately "dumb." It has no branch predictors. It has no cache controllers. It has no out-of-order execution logic. It is a massive array of arithmetic units and memory banks that do exactly what they are told, when they are told.11
The intelligence resides entirely in the Groq Compiler.
- Static Scheduling: Before the model runs, the compiler analyzes the entire program. It calculates the exact execution time of every operation. It knows that a specific matrix multiplication will take exactly 400 clock cycles.
- Spatial Orchestration: The compiler maps the data flow across the physical geometry of the chip. It knows that at Cycle 1,000,050, a packet of data will be exactly at coordinate (X, Y) on the chip, ready to be consumed by an arithmetic unit.
- Zero Variance: Because the schedule is fixed at compile time, there is zero variance. If the compiler says the task will take 28.5 milliseconds, it will take 28.5 milliseconds. Every single time. This is "Deterministic Execution".9
3.2 The Assembly Line Analogy
To understand the difference, imagine a factory floor.
- The GPU (Dynamic): Workers (cores) stand at stations. A manager (scheduler) shouts orders based on what materials just arrived. Sometimes a worker is idle because the forklift (memory bus) is stuck in traffic. Sometimes two workers try to grab the same tool (resource contention) and one has to wait. The output is high, but unpredictable.
- The LPU (Deterministic): There are no managers. The materials move on a high-speed conveyor belt that never stops. The workers are robotic arms programmed to perform a weld exactly 3.2 seconds after the part enters their zone. They do not check if the part is there; the system guarantees it is there. The efficiency is absolute.10
This architectural choice allows Groq to utilize nearly 100% of its compute capacity for the actual workload, whereas GPUs often run at 30-40% utilization during inference because they are waiting on memory.13
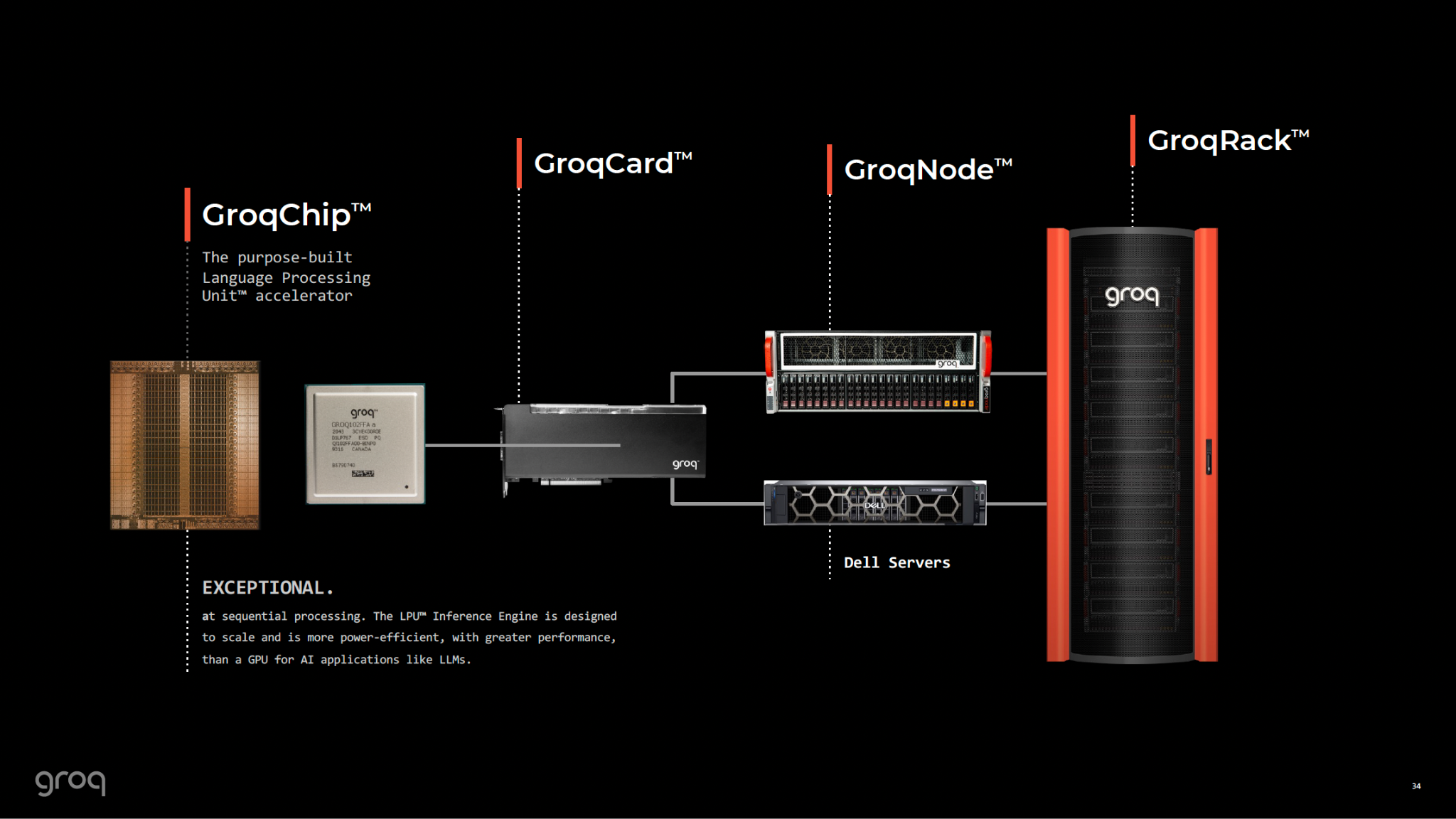
4. Anatomy of the LPU: Deconstructing the Hardware
The physical implementation of the LPU (specifically the GroqChip architecture) is a study in radical trade-offs. It sacrifices density and capacity for raw speed and predictability.

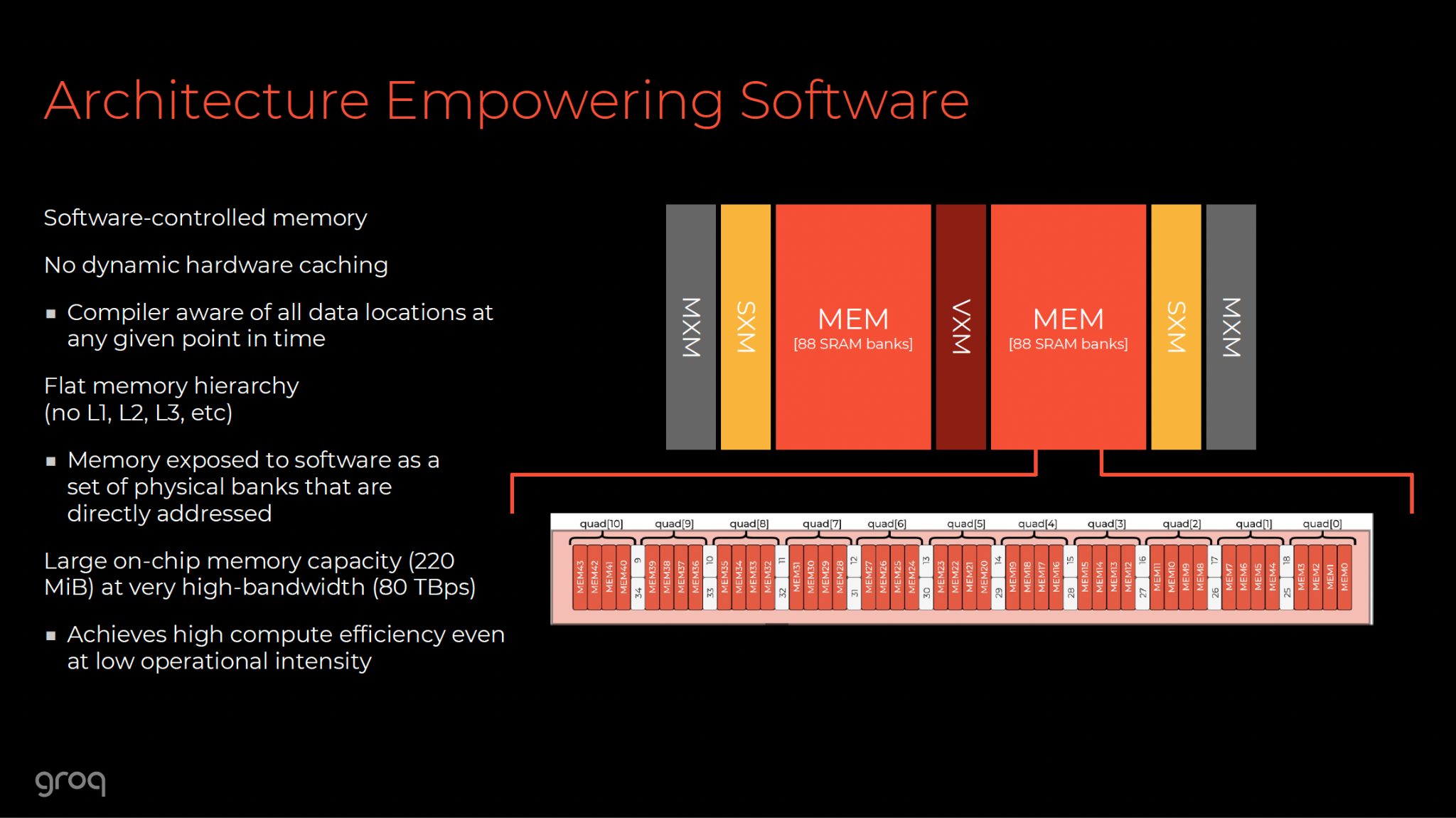
4.1 SRAM: The Speed of Light Storage
The most critical architectural differentiator is the memory. Nvidia and Google use HBM (High Bandwidth Memory), which comes in massive stacks (80GB+) sitting next to the compute die.
Groq uses SRAM (Static Random Access Memory).
- The Hierarchy Flattened: In a standard CPU, SRAM is used only for tiny caches (L1/L2/L3) because it is expensive and physically large (it takes 6 transistors to store a bit, vs. 1 transistor for DRAM). Groq, however, uses SRAM for the primary memory of the chip.
- Bandwidth Supremacy: Because the memory is physically integrated into the compute die, the bandwidth is astronomical. A single LPU boasts an internal memory bandwidth of 80 TB/s. Compare this to the H100’s 3.35 TB/s. This is a 24x advantage in the speed at which data can be fed to the math units.10
- Latency Elimination: Accessing HBM takes hundreds of nanoseconds. Accessing on-chip SRAM takes single digit clock cycles. This effectively removes the Memory Wall for data that fits on the chip.8
4.2 The Capacity Constraint
The trade-off is capacity. A single Groq chip contains only 230 MB of SRAM.12 This is microscopic compared to the 80GB of an H100.
- Implication: You cannot fit a Large Language Model on one Groq chip. You cannot even fit a small one.
- The Solution: You must link hundreds of chips together. To run Llama 3 70B, Groq does not use one chip; it uses a rack of roughly 576 chips.7
This necessitates a completely different approach to system design. The "computer" is not the chip; the computer is the rack.
4.3 The Tensor Streaming Processor (TSP)
Inside the chip, the architecture is arranged specifically for the linear algebra of Deep Learning.
- Vector and Matrix Units: The chip features specialized units for matrix multiplication (MXM) and vector operations.
- Directional Flow: Data flows horizontally (East-West) across the chip, while instructions flow vertically (North-South). This "systolic" flow means data is pumped through the functional units in a rhythmic wave.12
- 14nm Process: Surprisingly, the first generation GroqChip is built on a mature 14nm process at GlobalFoundries.7 In an industry racing to 3nm (like Nvidia's Blackwell), this seems archaic. However, because the design lacks complex schedulers and relies on SRAM, it does not need the extreme density of 3nm to achieve performance. This offers a significant cost and yield advantage, although it impacts the physical size of the die (a massive 725mm²).12
4.4 TruePoint Numerics
To maximize the limited 230MB of memory, Groq employs a novel precision strategy called TruePoint.
- The Precision Trap: Traditional hardware often quantizes models to INT8 (8-bit integers) to save space, which can degrade accuracy.
- Mixed Precision: TruePoint stores weights in lower precision (like INT8 or FP8) to save space but performs the actual math in high precision (FP32) for sensitive operations like attention logits. It maintains a 100-bit intermediate accumulation register to ensure no data is lost during the summation of matrix products.8
- Result: This allows Groq to achieve the speed of quantized models with the accuracy levels typically reserved for higher-precision implementations.
5. The Network is the Computer: RealScale Technology
Because no single LPU can hold a model, the network connecting the chips is as important as the chips themselves. If the connection between Chip A and Chip B is slow, the 80 TB/s of internal bandwidth is wasted.
5.1 RealScale: A Switchless Fabric
Traditional data center networks use Ethernet or InfiniBand switches. When a server sends data, it goes to a switch, which routes it to the destination. This adds latency and introduces the possibility of congestion (traffic jams).
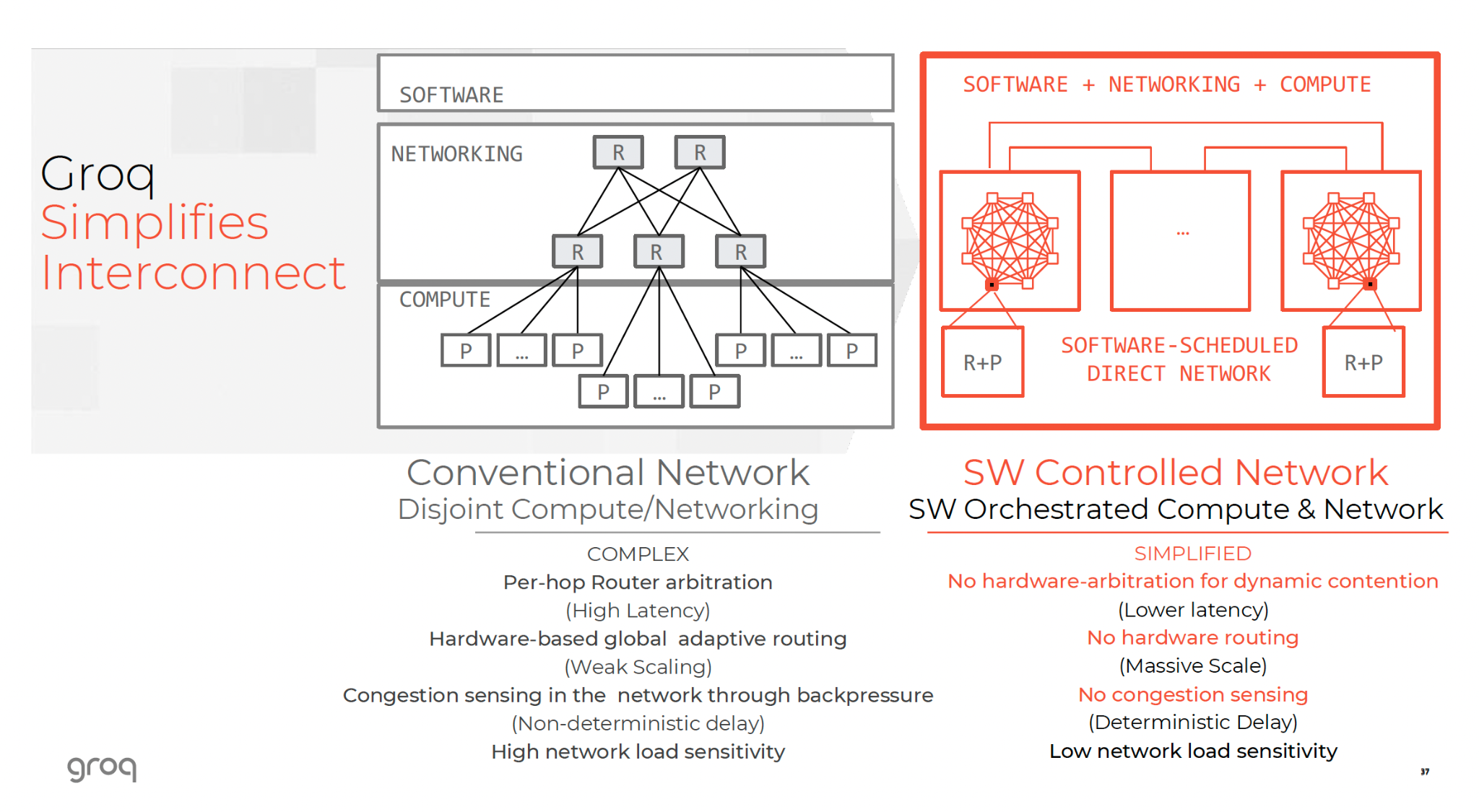
Groq’s RealScale network connects chips directly to each other.
- Plesiosynchronous System: The chips are synchronized to a common time base. They are not perfectly synchronous (which is physically impossible at scale), but they are "plesiosynchronous" (near-synchronous) with a known drift that the compiler accounts for.11
- Software-Scheduled Packets: Just as the compiler schedules the math, it schedules the network packets. It knows that Chip 1 will send a vector to Chip 2 at Cycle 500. It guarantees that Chip 2 will be ready to receive it at Cycle 505.
- No Switches: The network is a direct mesh (specifically a Dragonfly topology variant). There are no external switches to add latency or cost. The routing is deterministic. This allows the rack of 576 chips to function as a single, coherent memory space.6
5.2 Tensor Parallelism at Scale
This networking allows Groq to employ Tensor Parallelism efficiently.
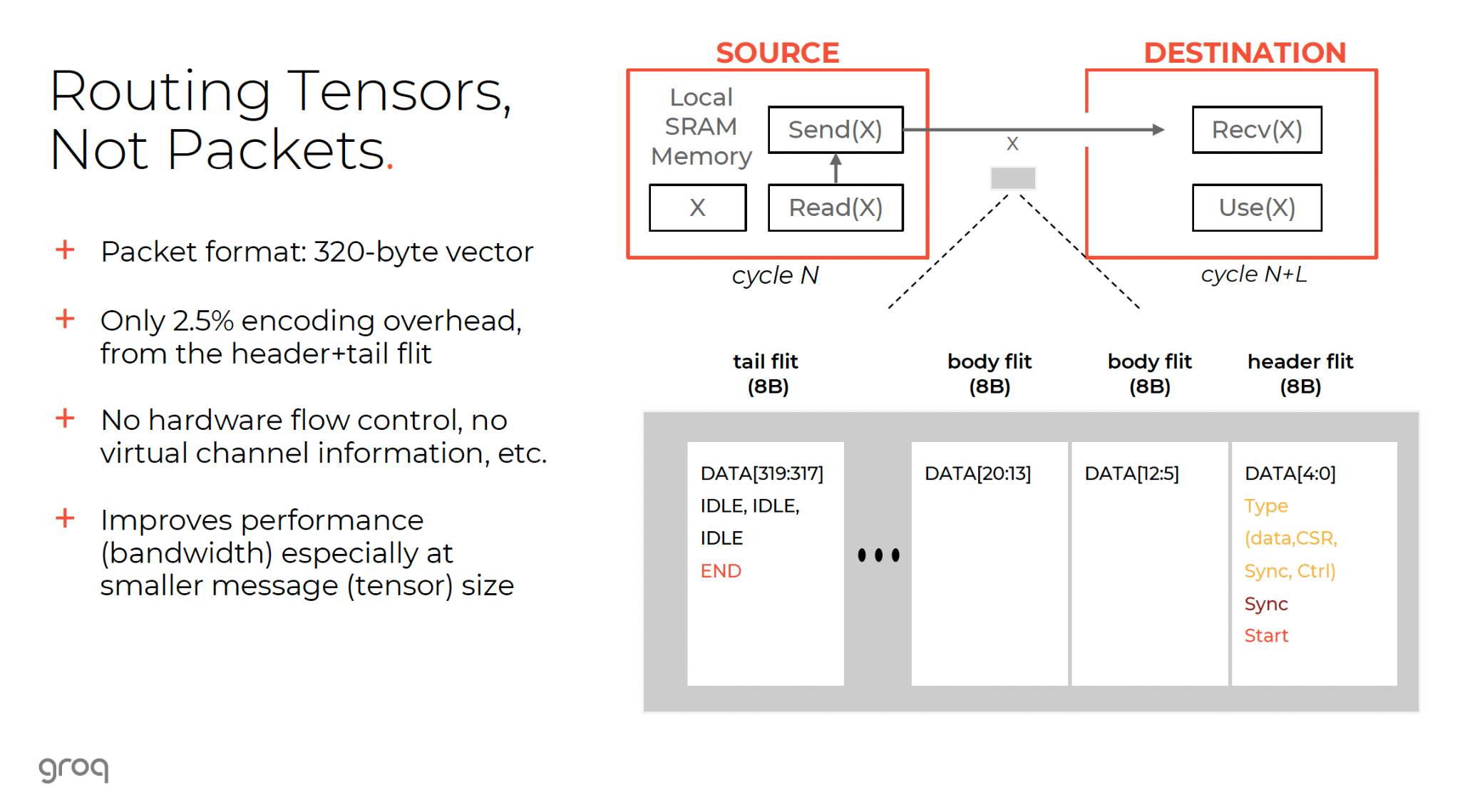
- Slicing the Brain: The Llama 3 70B model is sliced across the 576 chips. Every layer of the neural network is distributed.
- Simultaneous Execution: When a token is generated, all 576 chips activate simultaneously. Each computes a tiny fraction of the result. They exchange data instantly via the RealScale network, aggregate the result, and move to the next layer.
- Latency Benefit: Because the compute is parallelized across so many chips, the calculation happens incredibly fast. And because the weights are in SRAM, there is no load time. The result is a system that scales linearly: adding more chips makes the model run faster, without the diminishing returns seen in GPU clusters due to communication overhead.8
6. The Titans Compared: Groq vs. Nvidia vs. Google vs. Cerebras
The AI hardware landscape is a battle of philosophies. We can categorize the major players into three camps: The Generalists (Nvidia), The Hyperscale Specialists (Google), and The Radical Innovators (Groq, Cerebras).
6.1 Nvidia H200 (The Generalist)
- Architecture: GPU with HBM3e and HBM3. Dynamic scheduling via CUDA.
- Philosophy: "One chip to rule them all." Optimize for throughput, increased memory bandwidth, and versatility.
- Strengths: Unrivaled ecosystem (CUDA), massive memory capacity and bandwidth per chip (141GB HBM3e/HBM3), capable of both training and inference.
- Weaknesses: The Memory Wall limits Batch-1 inference speed. Tail latency due to dynamic scheduling. High power consumption per token for small batches.17
6.2 Google TPU v5p (The Hyperscale Specialist)
- Architecture: Systolic Array ASIC with HBM.
- Philosophy: Optimize for Google’s specific workloads (Transformer models).
- Strengths: Highly efficient matrix math. Inter-Chip Interconnect (ICI) allows for massive pods (8,960 chips) for training. Cost-effective for massive throughput.18
- Weaknesses: Still relies on HBM (latency bottleneck). Limited availability outside Google Cloud. Less flexible than GPUs.
6.3 Cerebras CS-3 (The Wafer-Scale Giant)
- Architecture: A single chip the size of a dinner plate (Wafer-Scale Engine).
- Philosophy: "Don't cut the wafer." Keep everything on one giant piece of silicon to eliminate interconnect latency.
- Strengths: Massive on-chip memory (44GB SRAM) and bandwidth (21 PB/s). Can hold large models on a single device.
- Weaknesses: Physical manufacturing complexity. Power density. Still requires a cluster for the largest models. Cerebras focuses on throughput (tokens/sec) more than pure latency (time to first token) compared to Groq.20
6.4 Groq LPU (The Low-Latency Sniper)
- Architecture: Disaggregated SRAM-based ASIC. Software-defined.
- Philosophy: "Determinism is speed." Sacrifice density for latency.
- Strengths: Unmatched Time-to-First-Token (TTFT) and throughput for small-batch inference. Deterministic performance (no jitter).
- Weaknesses: Low memory capacity per chip requires massive chip counts (high rack footprint). Not suitable for training.21
Table 1: Architectural Comparison Summary
|
Feature |
Groq LPU (TSP) |
Nvidia H200 (Hopper) |
Google TPU v5p |
Cerebras CS-3 |
|---|---|---|---|---|
|
Primary Focus |
Inference (Latency) |
Training & Inference |
Training & Inference |
Training & Inference |
|
Memory Architecture |
On-chip SRAM |
Off-chip HBM3 |
Off-chip HBM |
On-Wafer SRAM |
|
Memory Bandwidth |
80 TB/s (Internal) |
3.35 TB/s (External) |
~2.7 TB/s |
21 PB/s (Internal) |
|
Control Logic |
Software (Compiler) |
Hardware (Scheduler) |
Hybrid (XLA) |
Software (Compiler) |
|
Networking |
RealScale (Switchless) |
NVLink + InfiniBand |
ICI (Torus) |
SwarmX |
|
Batch-1 Efficiency |
Extremely High |
Low (Memory Bound) |
Medium |
Extremely High |
|
Llama 3 70B Speed |
~1,660 (w/ SpecDec)~280 (Native) |
~100-300 T/s |
~50 T/s (chip) |
~2,237 tokens/second |
Editor’s note: an earlier version of this article showed Cerebras’ throughput was ~450 tokens/second cited. It has been updated to reflect ~2,237 tokens/second per Groq’s more recent speculative decoding figure of ~1,600 tokens/second.
7. Performance Benchmarks: The Speed of Thought
25 millions tokens per second! I vividly remember hearing this bold prediciton from Jonathan Ross (Groq CEO) in late May 2024, when we invited him to speak at the GenAI Summit Silicon Valley. (Yes I took that photo for record. 🙂) Even though Groq is nowhere near that yet, its performance numbers have been truly impressive.

The theoretical advantages of the LPU have been validated by independent benchmarking, most notably by Artificial Analysis. The numbers reveal a stark divide in performance tiers.
7.1 Throughput and Latency
For the Llama 3 70B model, a standard benchmark for enterprise-grade LLMs:
- Groq: consistently delivers 280 - 300 tokens per second (T/s) in standard mode.6
- Nvidia H100: Typically delivers 60 - 100 T/s in standard deployments, pushing up to ~200 T/s only with heavy optimization and batching that compromises latency.24
- Latency (Time to First Token): Groq achieves a TTFT of 0.2 - 0.3 seconds, making the response feel instantaneous. Nvidia solutions often lag between 0.5 to 1.0+ seconds as the request queues and the GPU spins up.23
7.2 The Speculative Decoding Breakthrough
In late 2024, Groq unveiled a capability that widened the gap from a ravine to a canyon: Speculative Decoding. This technique allows Groq to run Llama 3 70B at over 1,660 tokens per second.1
The Mechanism:
Speculative decoding uses a small "Draft Model" (e.g., Llama 8B) to rapidly guess the next few words. The large "Target Model" (Llama 70B) then verifies these guesses in parallel.
- Why it fails on GPUs: On a GPU, loading the Target Model to verify the guesses is expensive due to the Memory Wall. The "verification cost" often outweighs the speed gain.
- Why it flies on Groq: Because the 70B model is distributed across the SRAM of the Groq rack, the verification step is nearly instant. The LPU can verify a sequence of tokens as fast as it can generate one. This allows Groq to output text faster than a human can blink.1
7.3 Energy Efficiency
While a rack of 576 chips consumes significant power (likely in the hundreds of kilowatts), the efficiency per unit of work is surprising.
- Joules per Token: Groq reports an energy consumption of 1-3 Joules per token.
- Comparison: Nvidia H100-based systems typically consume 10-30 Joules per token.6
- The Physics: The energy savings come from not moving data. Accessing external HBM is energy-intensive. Accessing local SRAM is cheap. Furthermore, because the Groq chip finishes the task 10x faster, it spends less time in a high-power active state for a given workload.
8. The Economics of the LPU: CapEx, OpEx, and TCO
The most controversial aspect of Groq’s architecture is the "Chip Count." Critics argue that needing hundreds of chips to run a model is economically unviable. This requires a nuanced Total Cost of Ownership (TCO) analysis.
8.1 The Cost of the Rack vs. The Cost of the Token
It is true that a Groq rack (running Llama 70B) contains ~576 chips.
- Manufacturing Cost: However, these chips are 14nm (cheap to make) and utilize standard packaging (no expensive CoWoS or HBM). A Groq chip costs a fraction of an Nvidia H100 to manufacture.7
- System Cost: While specific rack pricing is opaque, estimates suggest a Groq rack is expensive in absolute CapEx terms due to the sheer volume of silicon and power infrastructure.
- Throughput Value: Groq argues the metric that matters is Tokens per Dollar. If a Groq rack costs $1 million but generates 200,000 tokens per second (aggregate), and an Nvidia cluster costs $500,000 but generates only 20,000 tokens per second, the Groq rack is 5x more cost-effective per unit of output.13
8.2 Pricing Strategy
Groq has aggressively priced its API services to prove this point.
- Input Price: $0.59 per million tokens.
- Output Price: $0.79 - $0.99 per million tokens.2
- Comparison: This undercuts many traditional GPU-based cloud providers, who often charge $2.00 - $10.00 for similar models. This pricing signals that Groq’s internal TCO is indeed competitive, despite the hardware footprint.
8.3 Physical Footprint and Power
The downside is density. Replacing a single 8-GPU Nvidia server with multiple racks of Groq chips consumes significantly more data center floor space and requires robust cooling solutions. This makes Groq less attractive for on-premise deployments where space is tight, but viable for hyperscale cloud providers where floor space is less of a constraint than power efficiency.21
9. Use Cases: Who Needs Instant AI?
Is 1,600 tokens per second necessary? For a human reading a chatbot response, 50 tokens/sec is sufficient. However, the LPU is targeting a new class of applications.
9.1 Agentic AI and Reasoning Loops
Future AI systems will not just answer; they will reason. An "Agent" might need to generate 10,000 words of internal "Chain of Thought" reasoning to answer a single user question.
- The Math: If a model needs to "think" for 10,000 tokens:
- On Nvidia (100 T/s): The user waits 100 seconds. (Unusable).
- On Groq (1,600 T/s): The user waits 6 seconds. (Viable).
Groq’s speed unlocks the ability for models to "think" deeply before they speak.
9.2 Real-Time Voice
Voice conversation requires latency below 200-300ms to feel natural. Any delay creates awkward pauses (the "walkie-talkie" effect).
- Groq’s Role: With a TTFT of <200ms, Groq enables voice agents that can interrupt, backchannel, and converse with human-level cadence. Tenali, a real-time sales agent company, reported a 25x improvement in latency by switching to Groq, dropping response times from seconds to milliseconds.26
9.3 Code Generation
Coding assistants often need to read an entire codebase and regenerate large files. A developer waiting 30 seconds for a refactor breaks flow. Groq reduces this to sub-second completion.
10. The Software Stack: Escaping the CUDA Trap
Nvidia’s dominance is largely due to CUDA, its proprietary software platform. Groq knows it cannot win by emulating CUDA.
10.1 The "Hardware-Is-Software" Approach
Groq’s compiler is the heart of the product. It was built before the chip.
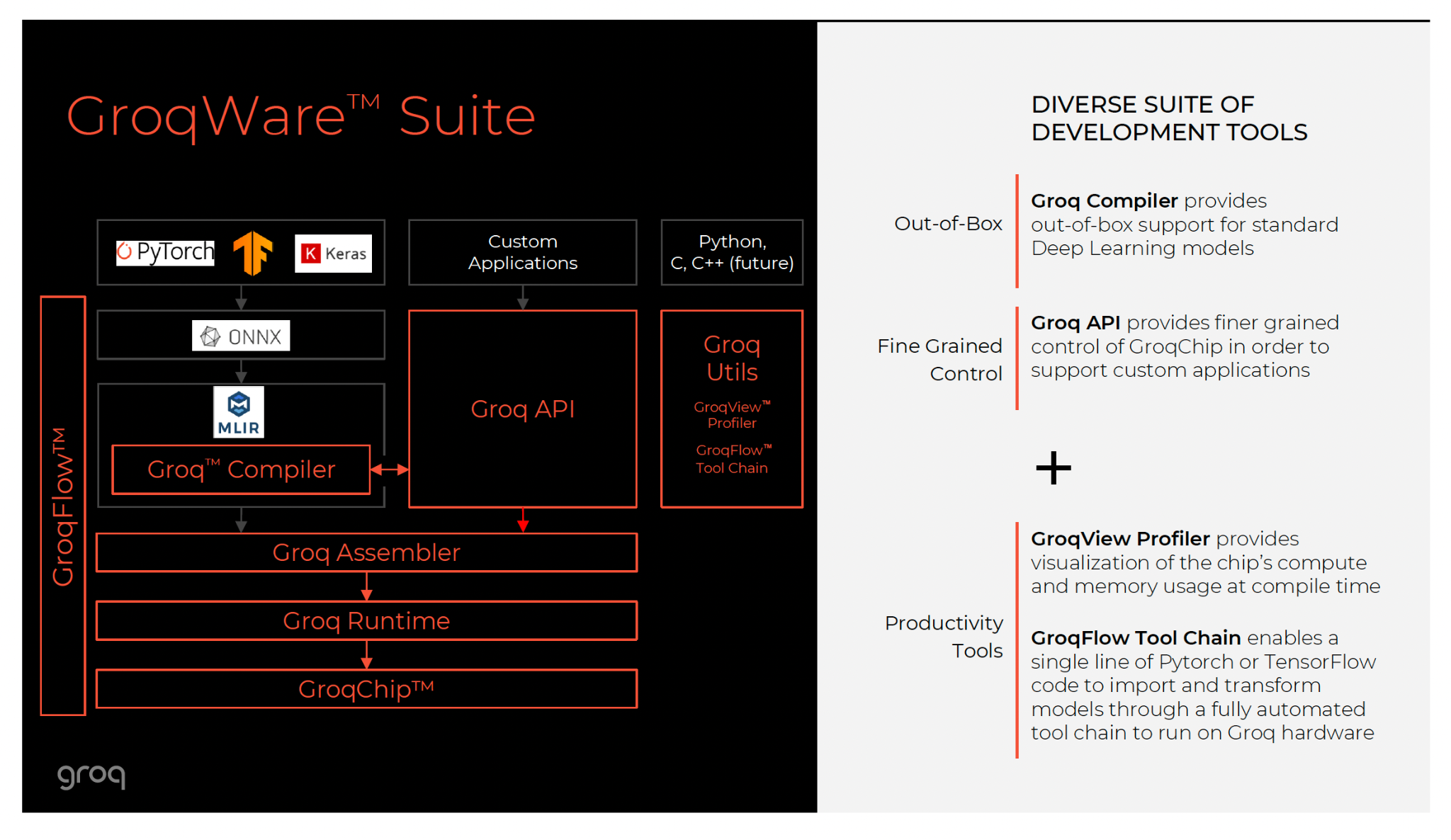
- Ease of Use: Developers use standard frameworks like PyTorch, TensorFlow, or ONNX. The compiler handles the translation to the LPU.
- GroqWare: The software suite manages the complexity of the rack. To the developer, the rack looks like one giant device.
- Challenges: The downside of static scheduling is compile time. Compiling a new model for the LPU can take significant time as the compiler solves the "Tetris" problem of scheduling millions of operations. This makes Groq less ideal for research (where models change hourly) but perfect for production (where models run for months).21
11. Conclusion: The Deterministic Future
The Groq LPU's success proves that the Von Neumann architecture is a liability for serial LLM inference. Groq's shift to SRAM and determinism created a machine that operates at the speed of light, enabling Agentic AI—systems capable of thousands of self-correcting reasoning steps in the blink of an eye.
With Nvidia's acquisition of Groq on 12/24/2025, the LPU's proven thesis—that determinism is destiny for future AI speed - will now be integrated into the GPU giant's roadmap. This merger signals a profound shift, acknowledging that raw power is meaningless without the speed and deterministic architecture Groq pioneered to use it effectively.
12. Bonus story - The Architect of Acceleration: Jonathan Ross and the Groq Journey

Jonathan Ross, Groq's founder and CEO, is central to two major AI hardware innovations: the Google TPU and the Groq LPU.
Before Groq, Ross was a key innovator on the Google Tensor Processing Unit (TPU). Introduced publicly in 2016, the TPU was Google's specialized chip for neural network calculations, designed to surpass the limitations of CPUs and GPUs. Ross helped conceptualize the first-generation TPU, which utilized a revolutionary systolic array architecture to maximize computational throughput and power efficiency for AI. His work at Google set the foundation for his later endeavors.
Leaving Google in 2016, Ross founded Groq (originally Think Silicon) with the goal of creating the world's fastest, lowest-latency AI chip with deterministic performance. He recognized that GPU unpredictability - caused by elements like caches and thread scheduling - was a bottleneck for real-time AI. Groq's mission became eliminating these sources of variability.
This philosophy gave rise to Groq’s flagship hardware: the Language Processor Unit (LPU) and its foundational GroqChip. The Groq architecture is a departure from the GPU-centric approach. It features a massive single-core, tiled design where all compute elements are connected by an extremely high-speed, on-chip network.
Groq’s Historical Arc: Ups, Downs, and Pivots
The path from an ambitious startup to a leading AI hardware provider was not linear for Groq. The company’s history is marked by necessary pivots and strategic refinements:
- Early Years (2016–2018): The Autonomous Driving Focus: Initially, Groq focused heavily on the autonomous vehicle market, where predictable, real-time decision-making is a critical requirement. The deterministic nature of the Groq chip was a perfect fit for this safety-critical domain, securing significant early partnerships.
- The Hardware Evolution (2018–2021): Designing the First Chip: This period was dedicated to the grueling process of designing, taping out, and optimizing the first generation of the GroqChip. Securing funding and attracting top talent from companies like Google and AMD were key milestones.
- The LLM Pivot (2022–Present): Finding the Killer App: As the autonomous vehicle market matured slower than anticipated and, crucially, as the transformer architecture exploded with the rise of models like GPT-3, Groq recognized a new, massive opportunity. The extreme scale and high demand for low-latency inference in LLMs made them the ideal workload for the Groq LPU. The LPU designation was adopted, effectively pivoting the company’s focus from general-purpose AI acceleration to specifically dominating the market for ultra-fast, predictable LLM inference.
- The Public Spotlight (2024–Beyond): Inference Dominance: Groq achieved widespread recognition by demonstrating staggering, industry-leading token-per-second performance on open-source LLMs like Llama and Mixtral. This sudden visibility cemented their position as a high-performance alternative to Nvidia GPUs for large-scale, low-latency AI deployment, marking a massive turning point in the company’s trajectory from a specialized hardware provider to a recognized leader in AI inference speed.
- Nvidia acquired Groq for $20B on December 24, 2025.
Jonathan Ross’s enduring contribution is the creation of a fundamentally different kind of computer - one engineered for predictable performance at scale. From co-designing the TPU architecture that powered Google’s AI revolution to pioneering the deterministic LPU at Groq, he has consistently championed the idea that the future of AI requires hardware tailored specifically for the workload, not the other way around.
Appendix: Data Tables
Table 2: Economic & Operational Metrics
|
Metric |
Groq LPU Solution |
Nvidia H100 Solution |
Implication |
|---|---|---|---|
|
OpEx (Energy/Token) |
1 - 3 Joules |
10 - 30 Joules |
Groq is greener per task. |
|
CapEx (Initial Cost) |
High (Rack scale) |
High (Server scale) |
Groq requires more hardware units. |
|
Space Efficiency |
Low (576 chips/rack) |
High (8 chips/server) |
Groq requires more floor space. |
|
Cost Efficiency |
High (Token/$) |
Low/Medium (Token/$) |
Groq wins on throughput economics. |
Table 3: The Physics of Memory
|
Memory Type |
Used By |
Bandwidth |
Latency |
Density (Transistors/Bit) |
|---|---|---|---|---|
|
SRAM |
Groq LPU |
~80 TB/s |
~1-5 ns |
6 (Low Density) |
|
HBM3 |
Nvidia H100 |
3.35 TB/s |
~100+ ns |
1 (High Density) |
|
DDR5 |
CPUs |
~0.1 TB/s |
~100+ ns |
1 (High Density) |
References
- Groq 14nm Chip Gets 6x Boost: Launches Llama 3.3 70B on GroqCloud, accessed December 25, 2025,
https://groq.com/blog/groq-first-generation-14nm-chip-just-got-a-6x-speed-boost-introducing-llama-3-1-70b-speculative-decoding-on-groqcloud - Llama-3.3-70B-SpecDec - GroqDocs, accessed December 25, 2025,
https://console.groq.com/docs/model/llama-3.3-70b-specdec - Introducing Cerebras Inference: AI at Instant Speed, accessed December 25, 2025,
https://www.cerebras.ai/blog/introducing-cerebras-inference-ai-at-instant-speed - Evaluating Llama‑3.3‑70B Inference on NVIDIA H100 and A100 GPUs - Derek Lewis, accessed December 25, 2025,
https://dlewis.io/evaluating-llama-33-70b-inference-h100-a100/ - Unlocking the full power of NVIDIA H100 GPUs for ML inference with TensorRT - Baseten, accessed December 25, 2025,
https://www.baseten.co/blog/unlocking-the-full-power-of-nvidia-h100-gpus-for-ml-inference-with-tensorrt/ - Why Meta AI's Llama 3 Running on Groq's LPU Inference Engine Sets a New Benchmark for Large Language Models | by Adam | Medium, accessed December 25, 2025,
https://medium.com/@giladam01/why-meta-ais-llama-3-running-on-groq-s-lpu-inference-engine-sets-a-new-benchmark-for-large-2da740415773 - Groq Says It Can Deploy 1 Million AI Inference Chips In Two Years - The Next Platform, accessed December 25, 2025,
https://www.nextplatform.com/2023/11/27/groq-says-it-can-deploy-1-million-ai-inference-chips-in-two-years/ - Inside the LPU: Deconstructing Groq's Speed | Groq is fast, low cost inference., accessed December 25, 2025,
https://groq.com/blog/inside-the-lpu-deconstructing-groq-speed - Determinism and the Tensor Streaming Processor. - Groq, accessed December 25, 2025,
https://groq.sa/GroqDocs/TechDoc_Predictability.pdf - What is a Language Processing Unit? | Groq is fast, low cost inference., accessed December 25, 2025,
https://groq.com/blog/the-groq-lpu-explained - LPU | Groq is fast, low cost inference., accessed December 25, 2025,
https://groq.com/lpu-architecture - GROQ-ROCKS-NEURAL-NETWORKS.pdf, accessed December 25, 2025,
http://groq.com/wp-content/uploads/2023/05/GROQ-ROCKS-NEURAL-NETWORKS.pdf - Groq Pricing and Alternatives - PromptLayer Blog, accessed December 25, 2025,
https://blog.promptlayer.com/groq-pricing-and-alternatives/ - Comparing AI Hardware Architectures: SambaNova, Groq, Cerebras vs. Nvidia GPUs & Broadcom ASICs | by Frank Wang | Medium, accessed December 25, 2025,
https://medium.com/@laowang_journey/comparing-ai-hardware-architectures-sambanova-groq-cerebras-vs-nvidia-gpus-broadcom-asics-2327631c468e - The fastest big model bombing site in history! Groq became popular overnight, and its self-developed LPU speed crushed Nvidia GPUs, accessed December 25, 2025,
https://news.futunn.com/en/post/38148242/the-fastest-big-model-bombing-site-in-history-groq-became - New Rules of the Game: Groq's Deterministic LPU™ Inference Engine with Software-Scheduled Accelerator & Networking, accessed December 25, 2025,
https://ee.stanford.edu/event/01-18-2024/new-rules-game-groqs-deterministic-lputm-inference-engine-software-scheduled - TPU vs GPU : r/NVDA_Stock - Reddit, accessed December 25, 2025,
https://www.reddit.com/r/NVDA_Stock/comments/1p66o4e/tpu_vs_gpu/ - GPU and TPU Comparative Analysis Report | by ByteBridge - Medium, accessed December 25, 2025,
https://bytebridge.medium.com/gpu-and-tpu-comparative-analysis-report-a5268e4f0d2a - Google TPU vs NVIDIA GPU: The Ultimate Showdown in AI Hardware - fibermall.com, accessed December 25, 2025,
https://www.fibermall.com/blog/google-tpu-vs-nvidia-gpu.htm - Cerebras CS-3 vs. Groq LPU, accessed December 25, 2025,
https://www.cerebras.ai/blog/cerebras-cs-3-vs-groq-lpu - The Deterministic Bet: How Groq's LPU is Rewriting the Rules of AI Inference Speed, accessed December 25, 2025,
https://www.webpronews.com/the-deterministic-bet-how-groqs-lpu-is-rewriting-the-rules-of-ai-inference-speed/ - Best LLM inference providers. Groq vs. Cerebras: Which Is the Fastest AI Inference Provider? - DEV Community, accessed December 25, 2025,
https://dev.to/mayu2008/best-llm-inference-providers-groq-vs-cerebras-which-is-the-fastest-ai-inference-provider-lap - Groq Launches Meta's Llama 3 Instruct AI Models on LPU™ Inference Engine, accessed December 25, 2025,
https://groq.com/blog/12-hours-later-groq-is-running-llama-3-instruct-8-70b-by-meta-ai-on-its-lpu-inference-enginge - Groq vs. Nvidia: The Real-World Strategy Behind Beating a $2 Trillion Giant - Startup Stash, accessed December 25, 2025,
https://blog.startupstash.com/groq-vs-nvidia-the-real-world-strategy-behind-beating-a-2-trillion-giant-58099cafb602 - Performance — NVIDIA NIM LLMs Benchmarking, accessed December 25, 2025,
https://docs.nvidia.com/nim/benchmarking/llm/latest/performance.html - How Tenali is Redefining Real-Time Sales with Groq, accessed December 25, 2025,
https://groq.com/customer-stories/how-tenali-is-redefining-real-time-sales-with-groq
[story continues]
tags