Table of Links
- Background
- Problem statement
- Model architecture
- Training data
- Results
- Conclusions
- Impact statement
- Future directions
- Contributions
- Acknowledgements and References
4 Training data
We pretrained Toto with a dataset of approximately one trillion time series points. Of these, roughly three-quarters are anonymous observability metrics from the Datadog platform. The remaining points come from the LOTSA dataset [15], a compilation of publicly-available time series datasets across many different domains.
4.1 Datadog dataset
The Datadog platform ingests more than a hundred trillion events per day. However, much of this data is sparse, noisy, or too granular or high in cardinality to be useful in its raw form. To curate a highquality dataset for efficient model training, we sample queries based on quality and relevance signals from dashboards, monitor alerts, and notebooks. This provides a strong signal that the data resulting from these queries is of critical importance and sufficient quality for observability of real-world applications.
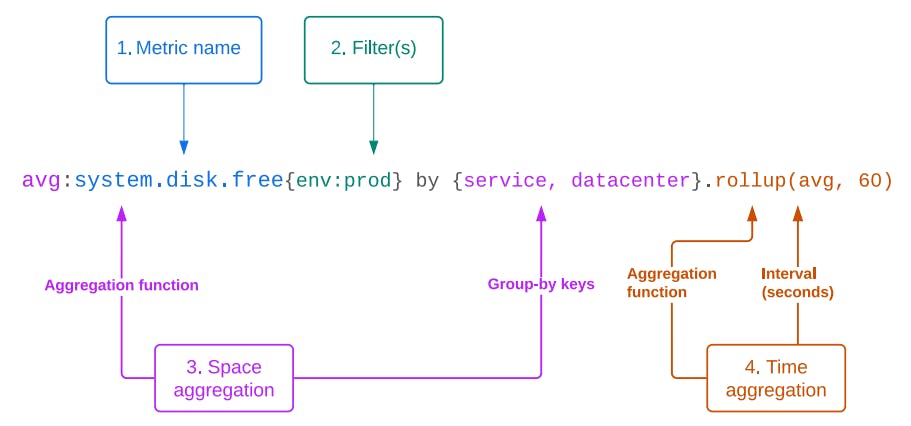
Datadog metrics are accessed using a specialized query language supporting filters, group-bys, time aggregation, and various transformations and postprocessing functions [43]. We consider groups returned from the same query to be related variates in a multivariate time series (Fig. 4). After we retrieve the query results, we discard the query strings and group identifiers, keeping only the raw numeric data.
Handling this vast amount of data requires several preprocessing steps to ensure consistency and quality. Initially, we apply padding and masking techniques to align the series lengths, making them divisible by the patch stride. This involves adding necessary left-padding to both the time series data and the ID mask, ensuring compatibility with the model's requirements.
Various data augmentations are employed to enhance the dataset's robustness. We introduce random time offsets to prevent memorization caused by having series always align the same way with the patch grid. After concatenating the Datadog and LOTSA datasets for training, we also implement a variate shuffling strategy to maintain diversity and representation. Specifically, 10% of the time, we combine variates that are not necessarily related, thus creating new, diverse combinations of data points. To sample the indices, we employ a normal distribution with a standard deviation of 1000, favoring data points that were closer together in the original datasets. This Gaussian sampling ensures that, while there is a preference for adjacent data points, significant randomness is introduced to enhance the diversity of the training data. This approach improves the model's ability to generalize across different types of data effectively.
By implementing these rigorous preprocessing steps and sophisticated data handling mechanisms, we ensure that the training data for Toto is of the highest quality, ultimately contributing to the model's superior performance and robustness.
4.2 Synthetic data
We use a synthetic data generation process similar to TimesFM [19] to supplement our training datasets, improving the diversity of the data and helping to teach the model basic structure. We simulate time series data through the composition of components such as piecewise linear trends, ARMA processes, sinusoidal seasonal patterns, and various residual distributions. We randomly combine five of these processes per variate, introducing patterns not always present in our real-world datasets. The generation process involves creating base series with random transformations, clipping extreme values, and rescaling to a specified range. By making synthetic data approximately 5% of our training dataset, we ensure a wide range of time-series behaviors are captured. This diversity exposes our models to various scenarios during training, improving their ability to generalize and effectively handle real-world data.
Authors:
(1) Ben Cohen (ben.cohen@datadoghq.com);
(2) Emaad Khwaja (emaad@datadoghq.com);
(3) Kan Wang (kan.wang@datadoghq.com);
(4) Charles Masson (charles.masson@datadoghq.com);
(5) Elise Rame (elise.rame@datadoghq.com);
(6) Youssef Doubli (youssef.doubli@datadoghq.com);
(7) Othmane Abou-Amal (othmane@datadoghq.com).
This paper is
[story continues]
tags