Table of Links
-
Harnessing Block-Based PC Parallelization
4.1. Fully Connected Sum Layers
4.2. Generalizing To Practical Sum Layers
-
Conclusion, Acknowledgements, Impact Statement, and References
B. Additional Technical Details
D. Additional Experiments
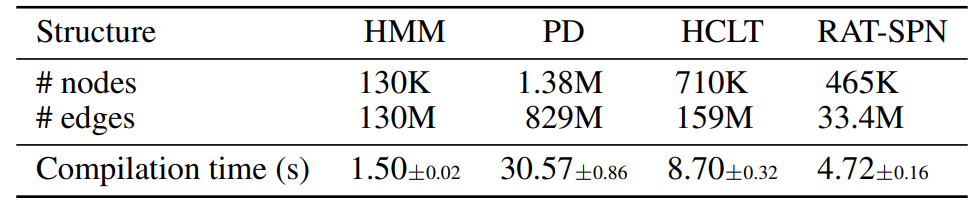
D.1. Speed of the Compilation Process
In Table 5, we show the compilation speed of PCs with different structures and different sizes. Experiments are conducted on a server with an AMD EPYC 7763 64-Core Processor and 8 RTX 4090 GPUs (we only use one GPU). The results demonstrate the efficiency of the compilation process, where even the PD model with close to 1B parameters can be compiled in around 30 seconds.
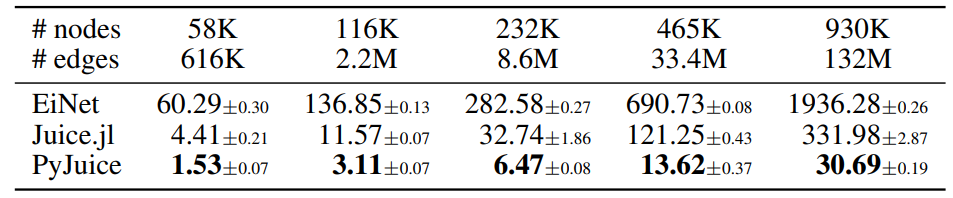
D.2. Runtime on Different GPUs
In addition to the RTX 4090 GPU adopted in the experiments in Table 1, we compare the runtime of PyJuice with the baselines on an NVIDIA A40 GPU. As shown in the following table, PyJuice is still significantly faster than all baselines for PCs of different sizes.
D.3. Runtime on Different Batch Sizes
As a supplement to Table 1, we report the runtime for a RAT-SPN (Peharz et al., 2020b) with 465K nodes and 33.4M edges using batch sizes {8, 16, 32, 64, 128, 256, 512}. To minimize distractions, we only record the time to compute the forward and backward process, but not the time used for EM updates. Results are shown in the table below.

Authors:
(1) Anji Liu, Department of Computer Science, University of California, Los Angeles, USA (liuanji@cs.ucla.edu);
(2) Kareem Ahmed, Department of Computer Science, University of California, Los Angeles, USA;
(3) Guy Van den Broeck, Department of Computer Science, University of California, Los Angeles, USA;
This paper is
[story continues]
tags