Authors:
(1) Will Hawkins, Oxford Internet Institute University of Oxford;
(2) Brent Mittelstadt, Oxford Internet Institute University of Oxford;
(3) Chris Russell, Oxford Internet Institute University of Oxford.
Table of Links
- Abstract and Introduction
- Related Work
- Experiments
- Discussion
- Limitations and Future Work
- Conclusion, Acknowledgments and Disclosure of Funding, and References
Abstract
Fine-tuning language models has become increasingly popular following the proliferation of open models and improvements in cost-effective parameter efficient fine-tuning. However, fine-tuning can influence model properties such as safety. We assess how fine-tuning can impact different open models’ propensity to output toxic content. We assess the impacts of fine-tuning Gemma, Llama, and Phi models on toxicity through three experiments. We compare how toxicity is reduced by model developers during instruction-tuning. We show that small amounts of parameter-efficient fine-tuning on developer-tuned models via low-rank adaptation on a non-adversarial dataset can significantly alter these results across models. Finally, we highlight the impact of this in the wild, demonstrating how toxicity rates of models fine-tuned by community contributors can deviate in hard-to-predict ways.
1 Introduction
Following the breakthrough of transformers there has been an acceleration in research and applications of large language models (LLMs) (Vaswani et al., 2017). Models such as GPT-4, Claude 3 Opus, and Gemini 1.5 have emerged in ‘closed source’ environments to power user-facing applications including ChatGPT, Claude and Gemini App (Anthropic, 2023; Gemini Team et al., 2024; OpenAI et al., 2024). Alongside this rise has emerged another phenomenon: increasingly competitive, often smaller, open generative models, whose weights have been made available for download online. These open models are generally less capable at a wide-range of tasks compared with closed-sourced competitors, but widely accessible via platforms such as Hugging Face, and sufficiently computeefficient to run locally using relatively small amounts of resources (Hugging Face, 2024). Open models have increased access to language models to a wider audience, being built upon by developers to create bespoke systems (Taraghi et al., 2024). Major AI developers have embraced open model developments with Google (Gemma), Meta (Llama-3), and Microsoft (Phi-3) releasing prominent open models indicating growing investment (Bilenko, 2024; Gemma Team et al., 2024; Meta, 2024).
Open models have the benefit of enabling local fine-tuning, or adjusting model parameters to improve performance on specified domains or tasks. This has risen in popularity in order to improve model performance on specified tasks, for example, to improve multilingual capabilities, or to tailor a chatbot experience. Fine-tuning can be undertaken on all parameters of a model, or on smaller subsets of a model, via parameter-efficient fine-tuning (PEFT) techniques such as Low-Rank Adaptation (LoRA) (Hu et al., 2021). PEFT techniques enable faster, cheaper fine-tuning of models, often preferable for developers and users of models with limited compute budgets. LoRA has been shown to deliver surprisingly good performance across a range of natural language processing tasks, leading to its widespread popularity among the open model community (Fu et al., 2022; Zeng & Lee, 2024).
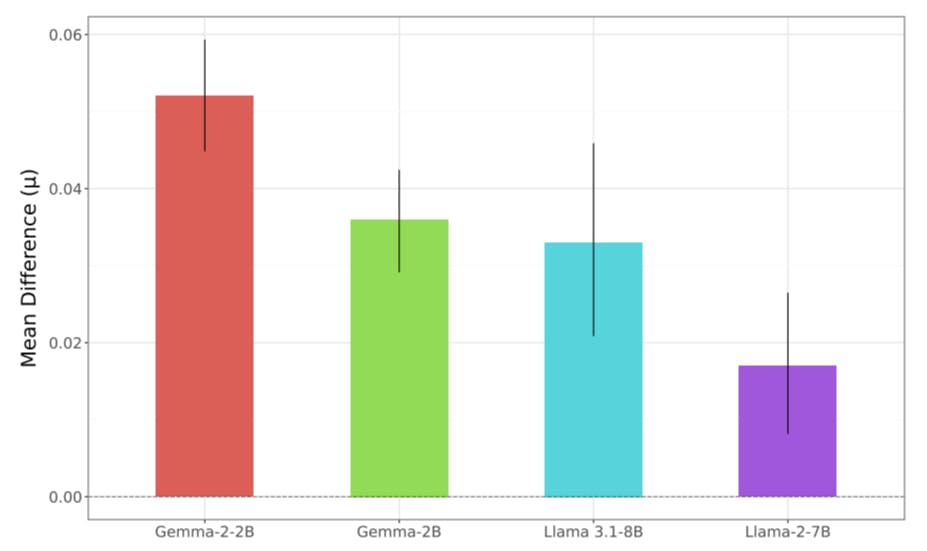
Whilst fine-tuning can improve performance in targeted domains it may also impact other model behaviors in unexpected ways. One such property is model safety, or the propensity or capability of a model to output unsafe responses to queries, including issues such as generating code for cyberattacks or creating instructions for developing malicious weapons (Weidinger et al., 2021). Model developers often describe their efforts to ensure deployment of safe models upon release, with safety and fairness referenced in release documentation for each of Gemma, Llama 3, Phi-3 and (Bilenko, 2024; Meta, 2024b; Microsoft, 2024). However, prior work has demonstrated how model safety can be impacted by fine-tuning, even when the data being used for fine-tuning does not include any data related to safety (Lermen et al., 2023; Qi et al., 2023).
This work contributes to prior literature on analyzing the impacts of fine-tuning by demonstrating the brittleness of toxicity mitigations in deployed open language models. In this paper we:
-
Measure how instruction-tuning reduces toxic language generation by models.
-
Track how these mitigations are inadvertently reversed via parameter efficient fine-tuning using non adversarial datasets.
-
Demonstrate the impact of this in the real world by showing how different community-created variants of models can deviate in seemingly unpredictable ways in their propensity to generate toxic content.
This paper is available on arxiv under CC 4.0 license.