Table of Links
A. Mathematical Formulation of WMLE
C Qualitative Bias Analysis Framework and Example of Bias Amplification Across Generations
D Distribution of Text Quality Index Across Generations
E Average Perplexity Across Generations
F Example of Quality Deterioration Across Generations
5 Results
In this section, we present the results on bias and generation performance of GPT-2 throughout iterative training, both with and without the deployment of mitigation strategies.
5.1 Political Bias
Using an unbiased dataset of 1,518 human-written articles evenly distributed across three politicalleaning categories, we generated 1,518 synthetic articles by deterministically predicting the next 64 tokens based on the previous 64 tokens. If GPT-2 had no pre-existing bias, the resulting distribution would be evenly spread across the three politicalleaning labels. However, as shown in Figure 3, the model generates more center (47.9%) and right
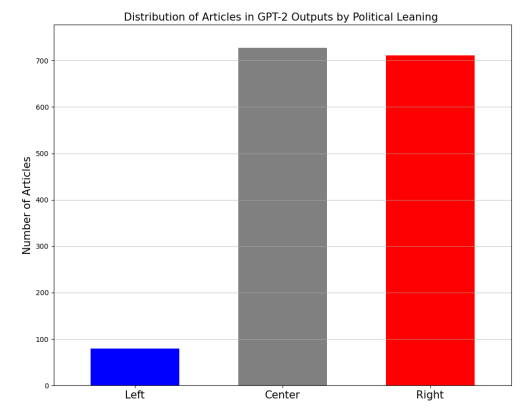
leaning articles (46.8%), indicating a bias toward these categories prior to any fine-tuning.
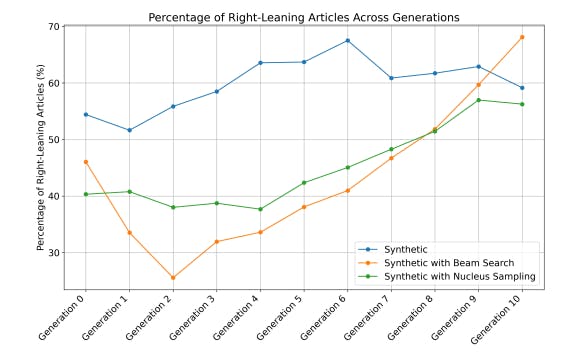
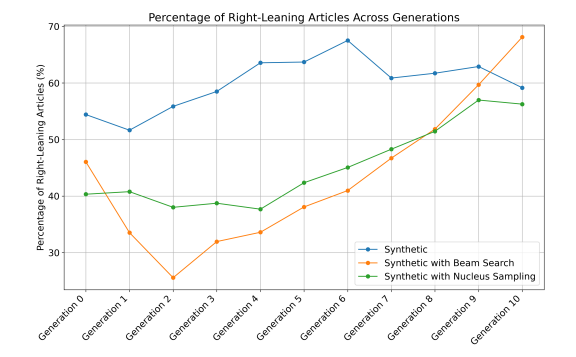
We then fine-tuned GPT-2 to produce Generation 0 and continued the process iteratively using synthetic datasets, up to Generation 10. As shown in Figure 4, the fine-tuned model displayed a significant amplification of bias toward the Right across all three generation setups after Generation 2. Interestingly, Generation 0 in the deterministic setup (the ’Synthetic’ line), which was fine-tuned on an unbiased dataset of real articles, produces an even higher percentage of right-leaning articles (54.5%) compared to the unfine-tuned GPT-2.
To ensure bias classification aligns with human intuition, we further examine model responses with human assistance. For illustration, we analyze a political opinion article, titled "First Read: Why
It’s So Hard for Trump to Retreat on Immigration", from NBC News, a left-leaning outlet rated by AllSides (NBC News, 2016; AllSides, 2024b), critiquing President Trump’s immigration policies. Using a qualitative analysis grounded in foundational media studies (Entman, 1993; Rodrigo-Ginés et al., 2024; Groeling, 2013), we observe a significant rightward shift between generations 0 and 4 for this example, consistent with the classifier’s results (see Appendix C). As the generations progress, the synthetic texts increasingly frame Trump’s immigration policies as strong and effective. While the original article focuses on the dilemma and electoral interests behind Trump’s stance, Generation 0 begins to emphasize his determination and reliability, omitting the criticism present in the original. By Generation 4, the narrative shifts further, focusing almost entirely on portraying Trump’s personal qualities and electoral legitimacy, with statements like "he is not a politician, he is a man of action." Notably, from Generation 0 onward, the term "undocumented immigrant" in the original article is replaced with "illegal immigrants."
5.2 Generation Quality
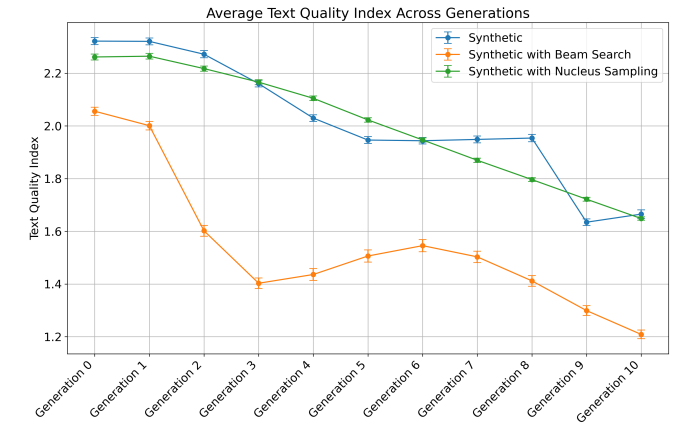
As shown in Figure 5, there is a model collapse in terms of the deterioration of the generation quality across all three generation setups: the average text quality index (defined in Section 4.4) decreases over the iterative training. Moreover, the distributions of the text quality index for all three generation setups shift markedly toward the low-quality region and starts to produce data that is never produced by Generation 0, as shown by the distribution plots in Appendix D. These findings are consistent
with the existing literature on model collapse, such as (Shumailov et al., 2024). However, we did not observe significant variation in variance, as seen in Figure 5 and distribution plots in Appendix D. In contrast, perplexity measurements show a steady decrease across generations for the deterministic and beam search generation setups, generally indicating improved generation quality (see Figure 11 in Appendix E).
For a closer look, as shown by the examples in Appendix F, the generated articles progressively lose coherence and relevance with each successive generation, as repetition and fragmented sentences become more common. By Generation 10, the text is largely incoherent and disconnected from the original content, diminishing its readability and meaning. However, despite the clear deterioration in generation quality, perplexity decreases over generations, as shown by the results at the end of each synthetic output example. This pattern is observed in most other synthetic outputs as well, suggesting that perplexity fails to accurately reflect the model’s true generation capabilities and may be biased toward repetitive content.
5.3 Mitigation Strategies
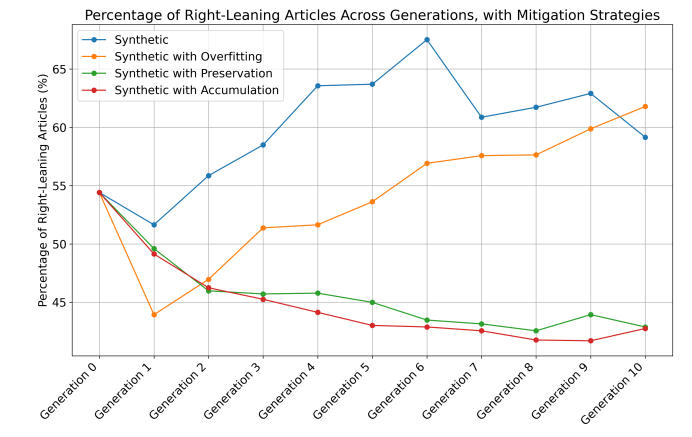
We applied three potential mitigation strategies under the deterministic generation setup: (1) Overfitting, which involved increasing the training epochs to 25 (five times the baseline) and setting weight decay to 0 to reduce regularization and encourage overfitting, as proposed by Taori and Hashimoto (2022) based on their uniformly faithful theorem of bias amplification; (2) Preserving 10% of randomly selected real articles during each round of synthetic

fine-tuning, a method proposed and used in (Shumailov et al., 2024; Alemohammad et al., 2023; Dohmatob et al., 2024b; Guo et al., 2024); and (3) Accumulating all previous fine-tuning datasets along with the new synthetic dataset in each finetuning cycle, which was introduced by Gerstgrasser et al. (2024). As shown in Figure 6, overfitting helps reduce bias amplification in the early generations compared to the no-mitigation setup (the ’Synthetic’ line), but it fails to prevent bias amplification in the later generations. Additionally, it incurs a significant cost—further deterioration in generation quality, as shown in Figure 7. Notably, both the preservation and accumulation strategies perform well in mitigating both bias amplification and model collapse. Interestingly, these strategies even result in bias reduction.
5.4 Mechanistic Interpretation
To gain a clearer understanding of the causes of bias amplification and how it empirically differs from model collapse, we investigate how neurons behave and vary across different versions[2] of finetuned GPT-2 with differing levels of generation quality and bias performance. First, we examined how the weight of each neuron changes across different versions. For each of the 9,216 neurons, we calculated the correlation between its weight and the model’s bias performance (i.e. the percentage of right-leaning articles) across the 66 versions, as shown in Figure 12 in Appendix G. To statistically test the significance of the correlations, we


6 Discussion
We now discuss the implications of bias amplification for the future development of large language models. As demonstrated, bias amplification is a parallel concept to model collapse and warrants equal emphasis in future research. In our case, we successfully identified ad hoc mitigation strategies, such as Preservation and Accumulation, which act as natural constraints on gradient updates during training by ensuring the model still considers the initial unbiased dataset. However, if the training dataset itself is biased or overrepresents certain demographic or political groups, these methods may fail, while pre-processing strategies could be too resource-intensive. Therefore, there is an urgent need to develop in-process mitigation strategies to address the constraint deficiency and promote more equitable and fair model development.
Authors:
(1) Ze Wang, Holistic AI and University College London;
(2) Zekun Wu, Holistic AI and University College London;
(3) Jeremy Zhang, Emory University;
(4) Navya Jain, University College London;
(5) Xin Guan, Holistic AI;
(6) Adriano Koshiyama.
This paper is available on arxiv under CC BY-NC-SA 4.0 license.
[2] We have 11 generations for each training setup and a total of 6 setups, resulting in 66 versions of fine-tuned GPT-2.
[3] All test results mentioned in this section are uploaded
[story continues]
tags