Insert a RAG layer to My Project, and My Experience with Cursor
TL;DR
My
What’s new in Part 2:
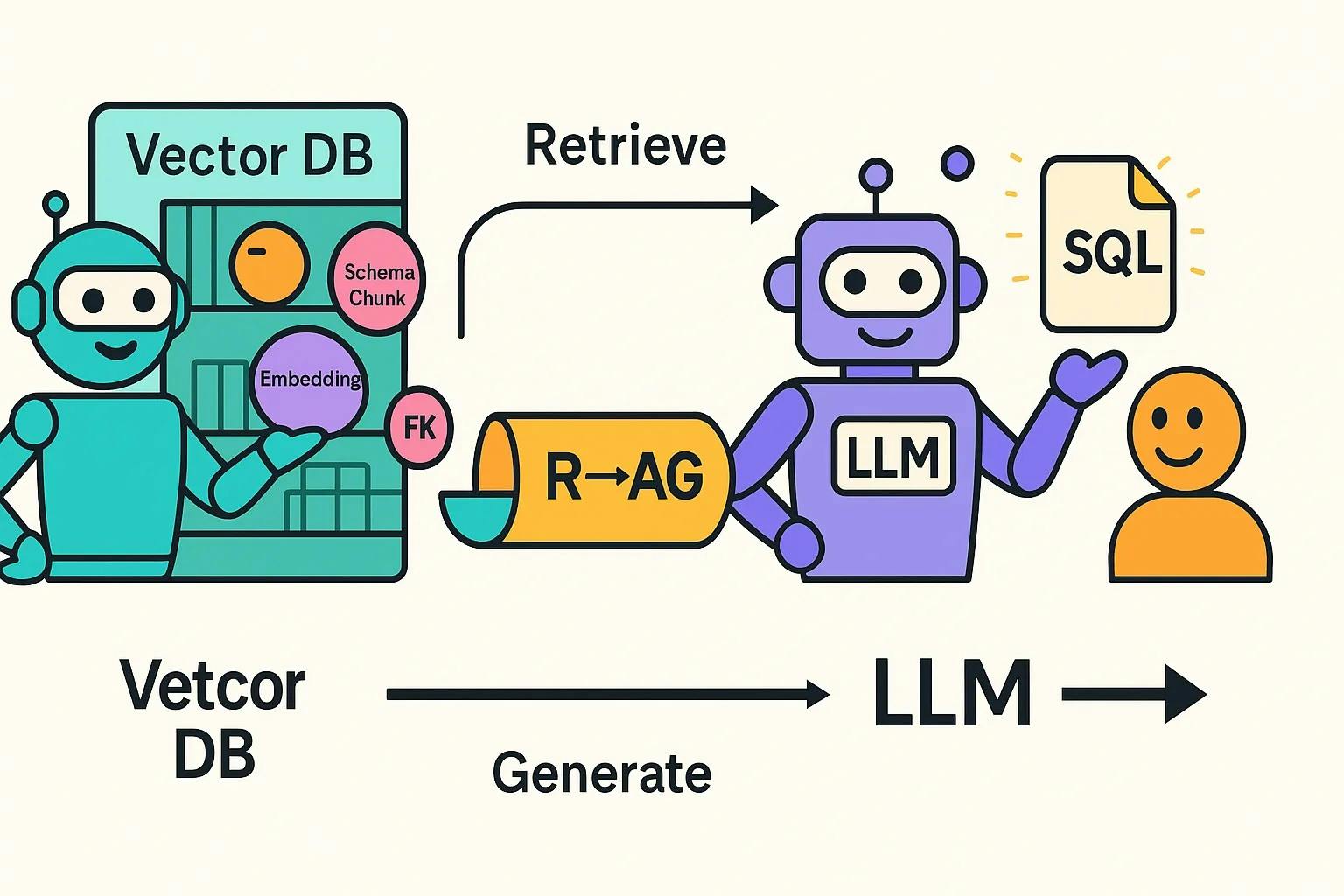
Persistent FAISS vector store loads only the schema chunks you need — columns, keys, indexes — so prompts shrink and latency falls.
Comprehensive test suite — unit, integration, and mock‑DB tests wired into CI — catches schema‑drift and retrieval edge cases before they hit production.
LLM rate‑limit resolution — Added foreign key relationships to the vector DB, which improves schema representation and reduces token usage.
Before we dive in, here are the two show-stoppers from Part 1:
Problem 1 — LLM Lost in Table Relationships
The LLM doesn’t know how your tables connect — you end up spelling out every join path by hand in each prompt.
Problem 2 — Schema Bulk Breaks Rate Limits
Dumping the full database schema into your prompt eats up tokens and almost always trips OpenAI’s 429 errors before you even get a response.
Researching and Solutioning:
What is a Vector Database?
A vector database is a specialized data store designed to hold and query vector representations (arrays of numbers) instead of traditional rows and columns.
Integrating the Vector Database
All of the database’s schema metadata — DDL, PK/FK relationships, index info, comments — gets pulled into rich documents, then embedded and persisted in FAISS for lightning-fast semantic search.
Why FAISS?
LLM suggested FAISS. Besides FAISS, I can also use Chroma, Qdrant, or Weaviate — each supports embedding storage and fast retrieval and can meet this project’s requirements.
FAISS (Facebook AI Similarity Search) is an open-source library developed by Meta’s Fundamental AI Research group for efficient similarity search and clustering of dense vectors.
What I Store: More Than Just a Table Blueprint?
Crucially, I don’t just store basic schema details like table and column names in this vector database. I also explicitly capture and store information about the foreign key relationships that define how these tables connect.
What is RAG?
Retrieval-Augmented Generation (RAG) is the pattern of:
- Retrieving the most relevant embeddings from the vector DB,
- Augmenting the LLM’s prompt with that retrieved context,
- Generating the final answer.
In other words, RAG depends on a vector DB to fetch just the right bits of knowledge before calling the LLM.
Why They Matter to LLM-Powered Apps?
LLMs can only hold so much text in one prompt. A vector DB + RAG lets you keep your “knowledge base” outside the prompt and pull in only what’s needed.
Think of the LLM as a student who can remember only a few pages at a time. The vector DB is the library’s catalog, and RAG is the workflow of fetching the exact pages needed before the student writes their essay.
How Vector DB Helps with LLM API Rate Limit?
A vector database stores your schema as embeddings—each table, column, or relationship becomes a searchable chunk. When a user asks a question (like “How many patients visited last week?”), the system turns that question into an embedding and performs a similarity search. Instead of returning the full schema, it fetches only the top-k most relevant tables—such as patients, visits, and appointments.
This focused context is then passed to the LLM, keeping prompts small while still providing the information it needs to generate accurate SQL.
Retrieval-Augmented Generation Flow (Steps 4 & 5) for the Project
After implementing foreign key awareness in my vector database, the 2 problems (stated earlier) are properly resolved.
Github Link: click
Demos
I am loading a sample database —
Each response includes 3 parts
- SQL Query
- Query Results
- Explaination
In the Second Half of This Article, How Do I Steer My AI Coder(s)?
I drove the project by setting goals and asking questions, the LLM handled the heavy lifting. It highlighted problems, proposed solutions, and explained trade-offs, while I made the final decisions on which path to follow.
A few advice to the drivers:
First, Think Like a Leader: You’re the manager, not the coder. Set clear goals and priorities, then let the LLM handle the implementation details.
Solid tests are your safety net — but with the LLM acting as your pair programmer, you get instant feedback. Run the tests, ask the LLM to debug any failures, and you’ll often find it suggesting cleaner designs mid-run. I’ve lost count of how many times a failing test prompted a better architecture idea!
Avoid Micromanagement: Like a human manager, micromanagement damages the team's efficiency. Specify what needs to happen, but trust the LLM to decide how. Over-constraining prompts can lead to strange designs or hidden bugs. Furthermore, it pulls you into implementation details and exhausts you. Naturally, when you get into this situation, it would feel better to write code by hand.
Intervene When Needed — If the LLM loops or drifts off track, a quick nudge or clarification is all it takes to get back on course. It’s not rare for an LLM to spend 20 minutes trying to fix a test without success. However, it only takes me one minute to find the root cause. Our robot teams always need directors.
Don’t forget — every LLM request costs money. Be mindful of this when the LLM is in self-interrogation mode.