Table Of Links
- DEFINITIONS
- DESIGN GOALS
- FRAMEWORK
- EXTENSIONS
- CLASSIFIERS
- FEATURES
- VULNERABILITY FIXING LATENCY
- ANALYSIS OF VULNERABILITY FIXING CHANGES
- ANALYSIS OF VULNERABILITY-INDUCING CHANGES
- N-FOLD VALIDATION
- EVALUATION USING ONLINE DEPLOYMENT MODE
- IMPLICATIONS ON MULTI-PROJECTS
- IMPLICATIONS ON ANDROID SECURITY WORKS
- THREATS TO VALIDITY
- ALTERNATIVE APPROACHES
IV. MODELING
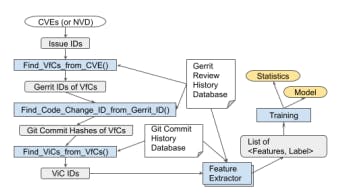
This section presents the design of a machine learning (ML) model trained to classify likely-vulnerable code changes. It explores lightweight classifier options and describes both the new and established input feature data types.
A. CLASSIFIERS
This study explores the following six common classifiers used for software fault prediction:
Decision Tree. It is a kind of flowchart that captures the modeled decision making process where nodes represents decision points and branches represents outcomes.
Random Forrest. It aggregates results from multiple decision trees to produce a single, enhanced result.
SVM (Support Vector Machine). It is a supervised ML algorithm that finds an optimal hyperplane for the training data to separate test data points into distinct classes.
Logistic Regression. It is a statistical method to model the log-odds of an event as a linear combination of one or more independent variables.
Naïve Bayes. It models the distribution of inputs of a given class, assuming the input features are conditionally independent, given the target class.
Quinlan’s C4.5 (v8) [13]. It is an efficient algorithm to generate a decision tree.
The hypothesis is that those common classifiers would be effective in predicting likely-vulnerable code changes. To test the hypothesis, this study evaluates all the six classifiers. All the classifiers are selected for their lightweight nature (e.g., low training cost and short inference time), meeting the two key design requirements. This study seeks to identify which of those classifiers can also achieve the required level of classification accuracy.
B. FEATURES
The classifier relies on a well-selected set of input feature data. The feature data types used in this study are as follows:
Human Profile (HP). The HP features capture the affiliations of the author and reviewer(s) of a code change:
HPauthor represents the trustworthiness of the email domain of an author. Email domains are ranked on an integer scale starting with 1 for the most trustworthy domain type and increasing by 1 as the trustworthiness declines. In Android Open Source Project (AOSP), verified email domains are available, helping to capture the author organizations 6 . Here, the value of ‘1’ is used when an author email domain is for the primary sponsor of AOSP (i.e., google.com); ‘2’ is used when the domain is android.com; ‘3’ is used for an Android partner company (e.g., samsung.com or qualcomm.com); ‘4’ is for other relevant open source communities (e.g., kernel.org); and ‘5’ is for all other domains (e.g., github.com or gmail.com).
HPreviewer similarly represents the trustworthiness of the code reviewer organizations, using the same value scale as HPauthor. It considers reviewers giving scores of ‘+2’, ‘+1’, or ‘-1’ to a given code change. Code changes with a ‘-2’ score from any reviewer is not submittable until the author addresses the respective review. Thus, the score of ‘-2’ is excluded from the modeling. For each relevant reviewer, HPreviewer is calculated and then the largest value is taken (i.e., the most external reviewer organization). It is assumed that external reviewers exhibit different behavioral patterns compared to internal reviewers in identifying potential vulnerabilities (e.g., due to limited access to project-specific, internal information, while some external reviewers possess unique expertise in security or specific domains).
While considering the roles of a code change author and reviewers (e.g., such as committer, active developer, tester, or release engineer) may seem useful, roles are not used in the modeling. It is because attackers can exploit trusted roles (e.g., as an attack vector). Furthermore, roles gleaned from the commit history do not reliably indicate the level of security expertise associated with each role.
Change Complexity (CC). The CC features represent the complexity of a given code change. It relies on a common observation that more complex change are more prone to software defects and thus to software vulnerabilities than the simpler changes. The following two CC features are used to gauge the likelihood of code change author mistakes:
CCadd counts the total number of lines added by a code change. It includes edits to all non-binary, text files in a code change such as source code, configuration files, and build files.
CCdel counts the total number of lines deleted by a code change in a similar manner. Here, we note that a modified source code line is counted as both a deleted line and an added line.
Those two basic change complexity metrics directly measure the volume of a code change. They are simpler than the common code complexity metrics. Furthermore, unlike our code change complexity metrics, the existing code complexity metrics (e.g., Halstead complexity [2], McCabe complexity, or CK metrics [17]) are usually for a software module or equivalent but not for the delta made by a code change. Halstead complexity uses the number of operators and operands in a given software module. McCabe complexity basically gives more weights to the edges in a control flow graph of a given module than the nodes. It also has definitions for cyclomatic, essential, and design complexities. CK metrics are for object-oriented programs as they use the sum of the complexity of the methods of a class.
While the existing code complexity could be applied to measure the complexity of a change, it involves a complex process. For example, one may perform such a code complexity analysis twice before and after applying a given code change to the baseline code and then compute the delta of the calculated code complexity metric values. In practice, aggregating such the delta values of code complexity for various directories, file types, files, modules, classes, and functions is non-trivial. Thus, it alones warrants a dedicated study.
While complex code changes are inherently difficult to find vulnerabilities in, they often get extra attentions from the reviewers (e.g., more questions and more revisions). For example, complex, thoroughly-reviewed code changes might actually be safer than medium-complexity changes that received minimal reviews (e.g., rubberstamped). To model the degree of reviewer engagement, the Patch set Complexity (PC) and Review Pattern (RP) features are devised:
Patch set Complexity (PC). A code change has multiple patch sets if it undergoes multiple revisions (e.g., in response to a code review). The following PC features are specifically devised to capture the volume of those patch sets:
PCcount is the total number of patch sets uploaded before a given code change is finally merged to the repository.
PCrevision is the sum of the total number of source code lines added or deleted by each of the revised patch sets of a code change, excluding the first patch set. It thus captures the volume of revisions made since the first patch set. Here, the lines added or deleted by each patch set are determined by calculating the deltas (or differences) between consecutive patch sets.
PCrelative_revision is a ratio of PCrevision and the number of added or deleted lines by the final merged patch set. It capture the amount of all revision activities relative to the complexity of the merged patch set.
PCavg_patchset represents the average volume of edits (i.e., total number of added and deleted lines) across all patch sets of a code change. It is calculated by PCrevision / (PCcount – 1).
PCmax_patchset and CCmin_patchset indicate the largest and smallest patch set complexity, respectively, measured by the total number of added or deleted lines, found within any patch set of a given code change.
Review Pattern (RP). The RP features are designed to capture the interactions between an author and reviewer(s), such as patterns in code review discussions. Those features are to help us avoid the need for direct and complex semantic analysis of the review comments.
RPtime measures the time elapsed, in seconds, between the initial creation of a code change to its final submission.
RPweekday indicates the day of week when a code change is submitted (e.g., starting from 1 for Sunday).
RPhour indicates the hour of day when a code change is submitted. It uses a 24-hour format (e.g., 0 for [midnight, 1am)).
RP+2 is a boolean value indicating whether a code change is self- approved by the author. Self-approval occurs when the author gives a ‘+2’ review score, while no other reviewer gives a positive score (‘+1’ or ‘+2’).
The RP features primarily focus on the common review scenarios. Many RP variant features are not used in this paper due to either weak correlations with target result or their focus on uncommon scenarios. Here are the three examples. RPreview_count is for the total number of comments posted by all reviewers. RPall_clear indicates unanimous positive reviews (e.g., 1 iff everyone commented gives a review score of ‘+1’ or ‘+2’). It is to capture a case when a reviewer found a vulnerability but because only one engineer needs to give a ‘+2’ score for submission, such valid concern was not properly addressed as part of the review. RPlast_min_change captures if the author self-approved the final patch set with no positive review score on it. The difference with RP+2 is whether some previous patch sets get a positive review score.
None of the RP features used in this paper is solely for rare cases. For example, let us consider a situation where a fixing plan is discussed in a code change (e.g., with multiple revisions), and then someone else cherry-picks the code change, amends it slightly, and self-approves for submission. While the RPtime value of the cherry-pick change does not reflect the original review effort, the RP+2 feature still captures the unusual case.
Human History (HH). The HH features aim to assess the creditability of individual engineers behind code changes. To this end, all past code change changes in the training dataset are classified as either likely-normal changes (LNCs) or vulnerability-inducing changes (ViCs). For each LNC, the author gets 2 points and every reviewer giving a review score of ‘+1’ or ‘+2’ gets 1 point. For each ViC, the author gets -3 points and a reviewer giving a positive review score gets -2 points. Those historical scores are then aggregated for each account. Using the aggregated data, the following HH feature values are calculated at runtime for every new patch set of any given code change:
HHauthor measures the human history score of a code change author, calculated as a ratio of the ViC score of the author and the LNC score of the same author.
HHreviewer measures the human history score of the reviewer(s) of a code change. Similar to the HHauthor score, the HHreviewer score of a reviewer is calculated as a ratio of the ViC score and the LNC score of the reviewer. For a code change with more than one reviewers, the highest value of all reviewers is used.
HHmin_reviewer and HHavg_reviewer are the minimum and average, respectively, human history score of all reviewers of a code change.
The quality of code changes by the same author (or reviewer) can fluctuate over time as engineers gains experience or falls behind on the latest vulnerabilities, secure coding practices, and product knowledge. To address this, the HH (Human History) features can be customized using sliding windows and weighted averages. That is to prioritize recent code changes and vulnerabilities over ones made a long time ago, ensuring the model adapts to the evolving skills and knowledge of engineers.
Vulnerability History (VH). The VH features aim to capture any patterns in when and where the vulnerabilities occurred. Those patterns encompass the temporal locality, spatial locality, and churn locality aspects [7]. Every change in the training dataset is classified as a LNC or ViC. Then the vulnerability history score of each file is calculated by (the number of LNCs in the file) –3 × (the number of ViCs
in the file). Here, any file seen in the ViC list gets –3 points, while any file seen in the LNC list gets +1 point. Those VH statistics of files form the basis of the following VH features:
VHtemporal_max and VHtemporal_min are the maximum and minimum, respectively, vulnerability history score value among all files within a given code change.
VHtemporal_avg is the average of the same, reflecting the churn locality. As code changes involving many files often have relatively simple modifications per file, it takes an average value instead of an aggregated value.
VHspatial_max, VHspatial_min, and VHspatial_avg assess the spatial locality in the VH patterns. They consider the number of ViCs found in: (1) the files in the same directory as ones in a given code change, and (2) the files with the same file names (e.g., using different extensions) across all directories in the code change. The code change gets -2 points for every such a file. Similarly, the change gets +1 point for every LNC file in the same directory. The aggregated scores from all LNC files is then used as a denominator to normalize it (e.g., a code change with many files vs. few files).
Process Tracking (PT). The PT features are designed to capture patterns in the volume of code changes throughout the software development lifecycle. It includes the trends in the numbers of LNCs (likely-normal changes), ViCs (vulnerability-inducing changes), and VfCs (vulnerabilityfixing changes). For example, a mature project might see fewer (or less) code changes overall, fewer submitted ViCs, and a relatively increase in VfCs. Those trends are tracked by the following three PT features. Here, the trend values are pre-computed for each file in a target repository (e.g., all files in the entire git project).
PTchange_volume measures the change in code volume (i.e., the number of source lines) between the current time period (e.g., a month) and the previous one.
PTVfC_volume measures the change in the number of VfCs submitted between the current and previous time periods. It is to assess the strength of underlying vulnerability triggers available in the target project. Its accuracy depends on how long it takes to discover vulnerabilities and then submit VfCs.
PTViC_volume measures the change in the number of ViCs merged between the current and previous time periods.
Text Mining (TM). The TM features are extracted by analyzing the text content of code changes (specifically the added deltas) to identify semantic similarities between vulnerable code changes. The hypothesis is that vulnerable code changes would share common words or tokens in their source code or in accompanying code review discussions.
The TM features parse all the source code lines added by a given code change, identifying and counting specific code pattern types relevant to the target C/C++ programming language. The considered pattern types include: arithmetic (e.g., +, –, *, /, %), comparison (e.g., ==, !=, &&), conditional (e.g., if, else, switch), loop (e.g., for, while), assignment (e.g., =, <<=, +=), logical (e.g., &, |, ^, ~), memory access (e.g., ->, .), and all others. Before those text mining operations, all comments and string constants are removed during a tokenization process.
TMarithmetic represents the proportion of arithmetic symbols found within the total count of all identified symbols.
TMcomparison, TMconditional, TMloop, TMassignment, TMlogical, and TMmemory_access are defined similar to TMarithmetic. While the above TM features are defined for source code deltas, similar metrics would be defined and applied to the textual content of review comments and code change descriptions, highlighting the flexibility of the TM features.
Author:
This paper is